You might also like
- CountryDocument6 pagesCountrykhawarbashirNo ratings yet
- ACR FORM Filled PDFDocument7 pagesACR FORM Filled PDFkhawarbashir100% (1)
- Solution To CS 5104 Take-Home QuizDocument2 pagesSolution To CS 5104 Take-Home QuizkhawarbashirNo ratings yet
- A Fragile Watermarking Scheme For Color Image AuthenticationDocument5 pagesA Fragile Watermarking Scheme For Color Image AuthenticationkhawarbashirNo ratings yet
- A Fragile Watermarking Scheme For Color Image AuthenticationDocument5 pagesA Fragile Watermarking Scheme For Color Image AuthenticationkhawarbashirNo ratings yet
- JPEG Image Compression Implemented in Matlab: by Michael ChristensenDocument6 pagesJPEG Image Compression Implemented in Matlab: by Michael ChristensenChandan KumarNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Retinex Algorithm PDFDocument15 pagesRetinex Algorithm PDFMaheswari GorantlaNo ratings yet
- Analysis of Electrical and Thermal Characteristics of Load-Relay Circuit Using Thermal ImagingDocument6 pagesAnalysis of Electrical and Thermal Characteristics of Load-Relay Circuit Using Thermal ImagingChethan GowdaNo ratings yet
- Computer Vision I: Raul Queiroz FeitosaDocument26 pagesComputer Vision I: Raul Queiroz FeitosaCarolina BeakliniNo ratings yet
- Counting Trees Using Segmentation and Vectorization in SAGA GisDocument6 pagesCounting Trees Using Segmentation and Vectorization in SAGA GisCassie SmithNo ratings yet
- Lab 4Document3 pagesLab 4Kavin KarthiNo ratings yet
- THS 102 - Module 2 Writing The Components of Chapter 1Document25 pagesTHS 102 - Module 2 Writing The Components of Chapter 1Kabagis TVNo ratings yet
- A Survey of Shaped-Based Registration and Segmentation Techniques For Cardiac ImagesDocument24 pagesA Survey of Shaped-Based Registration and Segmentation Techniques For Cardiac ImagesFaiz Zeo XiiNo ratings yet
- AaryanSachdeva Project ReportDocument41 pagesAaryanSachdeva Project ReportAaryan SachdevaNo ratings yet
- Digital Image Processing Notes PDFDocument139 pagesDigital Image Processing Notes PDFRaja Sekhar100% (4)
- International Journal of Image Processing (IJIP), Volume (4) : IssueDocument74 pagesInternational Journal of Image Processing (IJIP), Volume (4) : IssueAI Coordinator - CSC JournalsNo ratings yet
- Lee Lewicki Ieee Tip 02Document10 pagesLee Lewicki Ieee Tip 02vsalaiselvamNo ratings yet
- Currency Recognition System Using Image ProcessingDocument3 pagesCurrency Recognition System Using Image ProcessingAnonymous kw8Yrp0R5rNo ratings yet
- Color Image Segmentation Advantages and ProspectsDocument43 pagesColor Image Segmentation Advantages and ProspectsDak IanNo ratings yet
- Project ListDocument89 pagesProject ListMahesh KanikeNo ratings yet
- A Unified Microstructure Segmentation Approach Via Human-In-The-Loop Machine LearningDocument8 pagesA Unified Microstructure Segmentation Approach Via Human-In-The-Loop Machine Learning1286313960No ratings yet
- Research CollectionDocument25 pagesResearch Collectiondipali1631No ratings yet
- Simulation Projects (Ece) Digital Signal Processing (Adsp & Texas) Image ProcessingDocument2 pagesSimulation Projects (Ece) Digital Signal Processing (Adsp & Texas) Image Processingpradeepkumar1826No ratings yet
- Final Leaf PDFDocument63 pagesFinal Leaf PDFPower BangNo ratings yet
- Paper Smoothness ComparisonDocument14 pagesPaper Smoothness ComparisonSammy KimNo ratings yet
- Some Practical Assignments in Computer VisionDocument4 pagesSome Practical Assignments in Computer VisionLuis David MirandaNo ratings yet
- A Comparison of YOLO and Mask R-CNN For Segmenting Head and Tail of FishDocument6 pagesA Comparison of YOLO and Mask R-CNN For Segmenting Head and Tail of FishDemon YouthNo ratings yet
- Jia-Bin Huang: EducationDocument10 pagesJia-Bin Huang: EducationdewufhweuihNo ratings yet
- IEEE-Plant Identification Using FiltersDocument8 pagesIEEE-Plant Identification Using FiltersAtharva ZagadeNo ratings yet
- Mtech-Syllabus-Data Science - Sem1Document25 pagesMtech-Syllabus-Data Science - Sem1reshmaitagiNo ratings yet
- Virtual Mouse Using Colour Segmentation: Vit UniversityDocument9 pagesVirtual Mouse Using Colour Segmentation: Vit Universityyukul gargishNo ratings yet
- MHD202-Semantic Segmentation and Mapping of Traffic Scene-Presentation SlidesDocument32 pagesMHD202-Semantic Segmentation and Mapping of Traffic Scene-Presentation SlidesBHAVESH S (Alumni)No ratings yet
- Diseases Detection of Cotton Leaf Spot Using Image Processing and SVM ClassifierDocument5 pagesDiseases Detection of Cotton Leaf Spot Using Image Processing and SVM ClassifierShoaib R. SoomroNo ratings yet
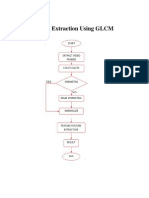
- Feature Extraction Using GLCM (Mamography)Document3 pagesFeature Extraction Using GLCM (Mamography)him1234567890No ratings yet
- Applications of Graph Theory in Computer Science An OverviewDocument12 pagesApplications of Graph Theory in Computer Science An OverviewAlemayehu Geremew100% (2)
- Human Parsing For Image-Based Virtual Try-On Using Pix2PixDocument5 pagesHuman Parsing For Image-Based Virtual Try-On Using Pix2Pixkeerthika PeravaliNo ratings yet