You might also like
- Introducción Modelos de Ecuaciones EstructuralesDocument42 pagesIntroducción Modelos de Ecuaciones EstructuralesFanny SpmNo ratings yet
- Aplicación de Ecuaciones Estructurales en El ECSI-Índice Europeo de Satisfacción Del Cliente PDFDocument11 pagesAplicación de Ecuaciones Estructurales en El ECSI-Índice Europeo de Satisfacción Del Cliente PDFcbarriosnNo ratings yet
- SEM Vs PLSDocument10 pagesSEM Vs PLSSanti TotalNo ratings yet
- Ecuaciones Estructurales Sesi n1Document43 pagesEcuaciones Estructurales Sesi n1Giovanni GabrielNo ratings yet
- Tesis Ecuaciones EstructuralesDocument0 pagesTesis Ecuaciones EstructuralesjcaldanabNo ratings yet
- Sistema de Ecuaciones Estructurales - Una Herramienta de InvestigaciónDocument104 pagesSistema de Ecuaciones Estructurales - Una Herramienta de InvestigaciónJESUS GARCIA HERNANDEZNo ratings yet
- Introducción A Las Ecuaciones Estructurales en AMOS y R - Lara (2014)Document285 pagesIntroducción A Las Ecuaciones Estructurales en AMOS y R - Lara (2014)Eduardo Aguirre Dávila100% (1)
- El Aprendizaje EstratégicoDocument3 pagesEl Aprendizaje EstratégicoEneri Diony MtzNo ratings yet
- Modelos de Ecuaciones Estructurales. Características, Fases, Construcción, Aplicación y ResultadosDocument7 pagesModelos de Ecuaciones Estructurales. Características, Fases, Construcción, Aplicación y ResultadosLorelineNo ratings yet
- Propuesta de Modelo de Medición de Imagen de Marca PDFDocument142 pagesPropuesta de Modelo de Medición de Imagen de Marca PDFMercedes Baño HifóngNo ratings yet
- Introducción Aplicada A Los Modelos de Ecuaciones EstructuralesDocument25 pagesIntroducción Aplicada A Los Modelos de Ecuaciones EstructuralesManuel Garcia QuihuataNo ratings yet
- 24 Herramientas Tic para Crear Actividades InteractivasDocument1 page24 Herramientas Tic para Crear Actividades Interactivaswillyfigueroa100% (1)
- Libro Rasch X TodosDocument150 pagesLibro Rasch X TodosTati Leon FuentesNo ratings yet
- Lectura U 9 LiderazgoDocument7 pagesLectura U 9 Liderazgodaniel hernandezNo ratings yet
- Análisis Multivariante. Ordenación IDocument27 pagesAnálisis Multivariante. Ordenación IGabriel HiNo ratings yet
- Comunidades Virtuales de AprendizajeDocument38 pagesComunidades Virtuales de AprendizajeAnonymous M365BOYTzNo ratings yet
- Guía Normas ApaDocument7 pagesGuía Normas Apalenguharas100% (9)
- Modelos de Ecuaciones EstructuralesDocument23 pagesModelos de Ecuaciones EstructuralesGerardo RodríguezNo ratings yet
- Introduccion Al Programa AMOS 5Document5 pagesIntroduccion Al Programa AMOS 5jorjisalasNo ratings yet
- Estadística Descriptiva MultivariadaDocument266 pagesEstadística Descriptiva MultivariadaYenifer Guzmán100% (1)
- Razonamiento Logico y VerbalDocument15 pagesRazonamiento Logico y VerbalLeo Magy0% (1)
- 04 Introduccion AMOSDocument17 pages04 Introduccion AMOSNoyka Lara100% (1)
- Finanzas AmosDocument18 pagesFinanzas AmosPolNo ratings yet
- Conde, F. Las Perspectivas Metodológicas Cualitativa y Cuantitativa en El Contexto de La Historia de Las Ciencias (Fragmentos)Document4 pagesConde, F. Las Perspectivas Metodológicas Cualitativa y Cuantitativa en El Contexto de La Historia de Las Ciencias (Fragmentos)chico_75No ratings yet
- Modelo de Estilos Sociales y VersatilidadDocument7 pagesModelo de Estilos Sociales y Versatilidadj_saldarriagaNo ratings yet
- Modelos Jerarquicos Lineales - Gaviria y CastroDocument67 pagesModelos Jerarquicos Lineales - Gaviria y CastrointemperanteNo ratings yet
- Como Funciona La Mente (PDFDrive)Document717 pagesComo Funciona La Mente (PDFDrive)Federico TomásNo ratings yet
- Tesis Modelo Tpack PDFDocument913 pagesTesis Modelo Tpack PDFMadia MoralesNo ratings yet
- Metodologia Ecuaciones EstructuralesDocument196 pagesMetodologia Ecuaciones EstructuralesJuan Quilodran FonsecaNo ratings yet
- Objetivos EducacionalesDocument5 pagesObjetivos EducacionalesPaola J VásquezNo ratings yet
- Statabasico disenoMatrizDatosDocument100 pagesStatabasico disenoMatrizDatosAdrier Zamalloa SuarezNo ratings yet
- ATLAS TiDocument17 pagesATLAS TiPancracia LibertadNo ratings yet
- Levy y Varela - Capítulo 3: Normalidad y Otros Supuestos en Análisis de CovarianzasDocument27 pagesLevy y Varela - Capítulo 3: Normalidad y Otros Supuestos en Análisis de CovarianzasMartin WarenNo ratings yet
- Aprendizaje Adaptativo ITESMDocument33 pagesAprendizaje Adaptativo ITESMAnna Linda Alcala100% (1)
- Cuadernillo Ejercicios ResueltosDocument215 pagesCuadernillo Ejercicios ResueltosEva DíazNo ratings yet
- Ensayo - Sistemas de InformaciónDocument2 pagesEnsayo - Sistemas de InformaciónFernanda OchoaNo ratings yet
- Ecuaciones Estructurales Con LisrelDocument3 pagesEcuaciones Estructurales Con LisrelmiqueralesNo ratings yet
- Diplomado en Diseño InstruccionalDocument4 pagesDiplomado en Diseño InstruccionalCarlosNo ratings yet
- LibroTransicion Aritmetica-Algebra Grupo MESCUD U Distrital 1999Document117 pagesLibroTransicion Aritmetica-Algebra Grupo MESCUD U Distrital 1999Oscar Gacharná León100% (1)
- Art04 SEM Papeles Del PsicologoDocument22 pagesArt04 SEM Papeles Del PsicologoCarlos Viera CarrascoNo ratings yet
- Monografia EstadisticaDocument21 pagesMonografia EstadisticaKarla Arleth Santos LauraNo ratings yet
- Modelo de Regresion LinealDocument24 pagesModelo de Regresion LinealCristhian AlexanderNo ratings yet
- Satisfacción de Clientes - Ecuaciones EstructuralesDocument11 pagesSatisfacción de Clientes - Ecuaciones Estructuralesasvc8536100% (1)
- Modelo Lavaan PDFDocument72 pagesModelo Lavaan PDFNaldoNo ratings yet
- Ecuaciones EstructuralesDocument22 pagesEcuaciones EstructuralesRafa Perez Hernandez100% (1)
- Modelos de Estructura de CovarianzaDocument43 pagesModelos de Estructura de CovarianzaJessica ValdezNo ratings yet
- Análisis de Ecuaciones Estructurales Conceptos, Etapas de Desarrollo y Un Ejemplo de Aplicación. Marcos CupaniDocument13 pagesAnálisis de Ecuaciones Estructurales Conceptos, Etapas de Desarrollo y Un Ejemplo de Aplicación. Marcos CupaniLucas De MariaNo ratings yet
- Ecuaciones EstructuralesDocument12 pagesEcuaciones EstructuralesvictoriusNo ratings yet
- Semana 8Document32 pagesSemana 8Freddy Samuel Choque MedinaNo ratings yet
- Modelos de Ecuaciones EstructuralesDocument18 pagesModelos de Ecuaciones EstructuralesnaldoNo ratings yet
- Modelos Matemáticos Basados en La Naturaleza de LasDocument27 pagesModelos Matemáticos Basados en La Naturaleza de LasMarco Sanchez Olaya67% (6)
- Análisis de Ecuaciones Estructurales. Conceptos, Etapas de Desarrollo y Un Ejemplo de AplicaciónDocument13 pagesAnálisis de Ecuaciones Estructurales. Conceptos, Etapas de Desarrollo y Un Ejemplo de AplicaciónJoaquín CarrascosaNo ratings yet
- Metodologia VarDocument7 pagesMetodologia VarDaniela OliveraNo ratings yet
- Regresión LinealDocument26 pagesRegresión LinealjhonNo ratings yet
- Proyecto AngelDocument19 pagesProyecto AngelAngel Jesus Silva MorenoNo ratings yet
- SEM 2012 M Sallan, Analisis de Modelos de Ecuaciones EstructuralesDocument8 pagesSEM 2012 M Sallan, Analisis de Modelos de Ecuaciones Estructuralesfranckiko2No ratings yet
- Ensayo EconometriaDocument6 pagesEnsayo EconometriaAnonymous aw9hSLSNo ratings yet
- Tarea 3 - Samuel BermúdezDocument10 pagesTarea 3 - Samuel BermúdezKevin Andres Diaz Arteaga100% (1)
- ECONOMETRIADocument9 pagesECONOMETRIAAndrea Alba BalderramaNo ratings yet
- Envases Innovadores FIRMEDocument9 pagesEnvases Innovadores FIRMEbruno diaz delgadoNo ratings yet
- Envases - ContaminacionDocument35 pagesEnvases - Contaminacionbruno diaz delgadoNo ratings yet
- Etica en La EmpresaDocument5 pagesEtica en La Empresabruno diaz delgadoNo ratings yet
- Cultivos AgroindustrialesDocument4 pagesCultivos Agroindustrialesbruno diaz delgadoNo ratings yet
- Balance de Materia en Procesos No ReactivosDocument2 pagesBalance de Materia en Procesos No Reactivosbruno diaz delgadoNo ratings yet
- Eficiencia TermicaDocument3 pagesEficiencia Termicabruno diaz delgadoNo ratings yet
- Conservación Por Congelación en Vegetales-Practica 9Document2 pagesConservación Por Congelación en Vegetales-Practica 9bruno diaz delgadoNo ratings yet
- Otros Tratamientos en Los AlimentosDocument19 pagesOtros Tratamientos en Los Alimentosbruno diaz delgadoNo ratings yet
- Fluidos Utilizados en La AgroindustriaDocument26 pagesFluidos Utilizados en La Agroindustriabruno diaz delgadoNo ratings yet
- Envases InnovadoresDocument9 pagesEnvases Innovadoresbruno diaz delgadoNo ratings yet
- Fluidos Utilizados en La AgroindustriaDocument12 pagesFluidos Utilizados en La Agroindustriabruno diaz delgado100% (1)
- Trabajo Animal para ImprimirDocument19 pagesTrabajo Animal para Imprimirbruno diaz delgadoNo ratings yet
- Conservacion Por Reduccion de HumedadDocument27 pagesConservacion Por Reduccion de Humedadbruno diaz delgadoNo ratings yet
- Tarea de Reconocimiento de Materiales de LaboratorioDocument17 pagesTarea de Reconocimiento de Materiales de Laboratoriobruno diaz delgadoNo ratings yet
- Trabajo Animal para ImprimirDocument19 pagesTrabajo Animal para Imprimirbruno diaz delgadoNo ratings yet
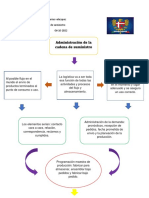
- Administracion de Cadena de SuministroDocument2 pagesAdministracion de Cadena de SuministroAlexis emmanuel Arias velazquezNo ratings yet
- Trabajo Avionica - Sistemas de IonDocument36 pagesTrabajo Avionica - Sistemas de IonKelvin Allan Soler LopezNo ratings yet
- Formato de Solicitud de Acceso A La Red Gsi - 1Document1 pageFormato de Solicitud de Acceso A La Red Gsi - 1Jaime MedranoNo ratings yet
- CurpDocument1 pageCurpAline MercadoNo ratings yet
- Modulo I A Responder Las Nueve PreguntasDocument8 pagesModulo I A Responder Las Nueve PreguntasdennisquispeNo ratings yet
- Brecha Digital en Tiempo Del Covid-19Document10 pagesBrecha Digital en Tiempo Del Covid-19Gaby cabrialesNo ratings yet
- Perfil de Descripción de Puestos de La Unidad de Gestión Documental y Archivo - CONSAADocument9 pagesPerfil de Descripción de Puestos de La Unidad de Gestión Documental y Archivo - CONSAAIsai GarciaNo ratings yet
- Acta de Reunion N°01Document2 pagesActa de Reunion N°01Job RosalesNo ratings yet
- Ti m1 Grinda SierraDocument12 pagesTi m1 Grinda SierraOsvaldo VegaNo ratings yet
- Taller 1Document5 pagesTaller 1Maria Ruiz LinoNo ratings yet
- Evaluacion Final - Escenario 8 - SEGUNDO BLOQUE-TEORICO - MODELOS DE TOMA DE DECISIONES - (GRUPO B03)Document7 pagesEvaluacion Final - Escenario 8 - SEGUNDO BLOQUE-TEORICO - MODELOS DE TOMA DE DECISIONES - (GRUPO B03)Juliana PatiñoNo ratings yet
- Guia 3 - INSTALACION DE PROGRAMASDocument78 pagesGuia 3 - INSTALACION DE PROGRAMASIvan Dario RubianoNo ratings yet
- Modulacion FM y AskDocument8 pagesModulacion FM y Askoscar riseroNo ratings yet
- Varios Azure PDFDocument169 pagesVarios Azure PDFCarlos AriasNo ratings yet
- Tarea 1 de La Practica - packET. MHCDocument5 pagesTarea 1 de La Practica - packET. MHCcasamivilNo ratings yet
- 22 Manual de Usuario de La Extensión CINEMA 4DDocument22 pages22 Manual de Usuario de La Extensión CINEMA 4Dtabio 85No ratings yet
- Informe Centro de PresiónDocument2 pagesInforme Centro de PresióneduarNo ratings yet
- Coleccion Libros de Zecharia Sitchin PDF Identi PDFDocument5 pagesColeccion Libros de Zecharia Sitchin PDF Identi PDFChATIERIXNo ratings yet
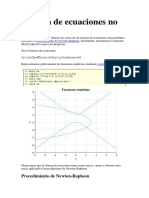
- Sistema de Ecuaciones No LinealesDocument9 pagesSistema de Ecuaciones No LinealesWanderley Kevin Alccaihuaman Quispe0% (1)
- Lab 1 SensoresDocument7 pagesLab 1 SensoresGonzalo PimentelNo ratings yet
- Modulacion Por Pulsos Codificados (PCM)Document9 pagesModulacion Por Pulsos Codificados (PCM)Agustín Rodríguez RojasNo ratings yet
- Dentro FueraDocument3 pagesDentro Fueralorena100% (2)
- Mobile App Security Checklist-Spanish 1.1Document64 pagesMobile App Security Checklist-Spanish 1.1Juan MartinNo ratings yet
- Redes SocialesDocument3 pagesRedes SocialesNoé Hernández SagastumeNo ratings yet
- Roadmap 2022Document2 pagesRoadmap 2022dragorinNo ratings yet
- Modelo de Sesión - ZoilaDocument2 pagesModelo de Sesión - ZoilaAlejandro Nolasco EstradaNo ratings yet
- Taller Electrónica DigitalDocument53 pagesTaller Electrónica Digitalcsantos712100% (1)
- Cuando BotarDocument2 pagesCuando BotarKamy Muñoz PizarroNo ratings yet
- Teoria PolinomioDocument14 pagesTeoria PolinomioCristian SulcaNo ratings yet
- Manual MENTOR UT - Español - 2020Document130 pagesManual MENTOR UT - Español - 2020Alexander Sueco Leyan Castillo100% (1)