You might also like
- 2Document2 pages2Muhammad FarhanNo ratings yet
- 5Document2 pages5Muhammad FarhanNo ratings yet
- Chapter 3Document5 pagesChapter 3Muhammad FarhanNo ratings yet
- SQA TasksDocument2 pagesSQA TasksMuhammad FarhanNo ratings yet
- 2Document2 pages2Muhammad FarhanNo ratings yet
- Chapter3 PrintDocument2 pagesChapter3 PrintMuhammad FarhanNo ratings yet
- Chapter 3Document5 pagesChapter 3Muhammad FarhanNo ratings yet
- Using State Machine Workflows 2010Document5 pagesUsing State Machine Workflows 2010Muhammad FarhanNo ratings yet
- 111Document1 page111Muhammad FarhanNo ratings yet
- NW2013 Create A Very Basic WorkflowDocument7 pagesNW2013 Create A Very Basic WorkflowMuhammad FarhanNo ratings yet
- Simple Approval Workflow NW2013Document10 pagesSimple Approval Workflow NW2013Muhammad Farhan100% (1)
- CodeDocument3 pagesCodeMuhammad FarhanNo ratings yet
- NF2010 Installation Guide EnglishDocument13 pagesNF2010 Installation Guide EnglishMuhammad FarhanNo ratings yet
- Organizational Organizational Structure Structure: Lecture # 10 Lecture # 10Document4 pagesOrganizational Organizational Structure Structure: Lecture # 10 Lecture # 10Muhammad FarhanNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Dry Bulk Cargo Handling in Perlis PortDocument5 pagesDry Bulk Cargo Handling in Perlis PortShahrul ShafiqNo ratings yet
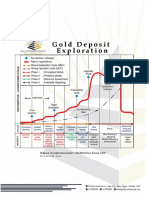
- Stages of An Exploration Project. (Modifted From Eimon 1988.)Document1 pageStages of An Exploration Project. (Modifted From Eimon 1988.)KareemAmenNo ratings yet
- TMLDocument12 pagesTMLTebe Emil MichiNo ratings yet
- Draft Uganda Mining and Mineral Bill, 2019Document175 pagesDraft Uganda Mining and Mineral Bill, 2019African Centre for Media Excellence100% (5)
- Blasthole Reference Book - tcm892-1923757Document248 pagesBlasthole Reference Book - tcm892-1923757Paul Gossen80% (5)
- WWW - MINEPORTAL.in: CALL/WHATSAPP-8804777500Document9 pagesWWW - MINEPORTAL.in: CALL/WHATSAPP-8804777500Sujib BarmanNo ratings yet
- Mineral and Energy ResourcesDocument4 pagesMineral and Energy ResourcesJoseph ZotooNo ratings yet
- London Market Closing Update 14 July 2017Document3 pagesLondon Market Closing Update 14 July 2017ChrisTheodorouNo ratings yet
- How Tall A Column in Block Caving 2014-May-2Document11 pagesHow Tall A Column in Block Caving 2014-May-2carlo cerruttiNo ratings yet
- 10 07 First-Industrial-RevolutionDocument44 pages10 07 First-Industrial-Revolutionapi-235788394No ratings yet
- BASO Presentation PDFDocument25 pagesBASO Presentation PDFGEOEXPLOREMINPERU MINERÍA Y GEOLOGIANo ratings yet
- La Bugal - Blaan vs. RamosDocument2 pagesLa Bugal - Blaan vs. RamosSjaneyNo ratings yet
- Writ GenDocument475 pagesWrit Genagus tiwansyah50% (2)
- Overview of Zimbabwe's Mining Sector: Alex Mhembere President Chamber of Mines of ZimbabweDocument41 pagesOverview of Zimbabwe's Mining Sector: Alex Mhembere President Chamber of Mines of Zimbabweclemence0% (1)
- Reading Materials Sustainable Development of Real EstateDocument513 pagesReading Materials Sustainable Development of Real EstateArafat DomadoNo ratings yet
- InspectionTrends 201101Document44 pagesInspectionTrends 201101Dino PedutoNo ratings yet
- Fco Daw-CarpacoDocument1 pageFco Daw-CarpacoMuhammad SupiyanNo ratings yet
- MPSA As of September 2019Document45 pagesMPSA As of September 201904 pandaNo ratings yet
- Data Mining Made EasyDocument554 pagesData Mining Made EasyAamir HamidNo ratings yet
- Directors Report 2011 12 WCLDocument146 pagesDirectors Report 2011 12 WCLsarvesh.bhartiNo ratings yet
- ERP in Mining IndustryDocument24 pagesERP in Mining Industrynirajiitkgp100% (2)
- Quarry Seminar 2015Document104 pagesQuarry Seminar 2015Anonymous vz0E87iFCNo ratings yet
- Understanding Mining Production Costs and Future Plans for Panel CavingDocument5 pagesUnderstanding Mining Production Costs and Future Plans for Panel CavingDiego Arturo Rojas AlfaroNo ratings yet
- Stripping Ratio ConsiderationsDocument18 pagesStripping Ratio ConsiderationsFranz Diaz100% (2)
- Report of KARNATAKA LOKAYUKTA Into Allegations of Illegal MiningDocument283 pagesReport of KARNATAKA LOKAYUKTA Into Allegations of Illegal MiningSampath BulusuNo ratings yet
- BOTSWANADocument32 pagesBOTSWANAAvinash_Negi_7301No ratings yet
- Mineral Year Book - NigeriaDocument6 pagesMineral Year Book - NigeriaOpe-Oluwa FadipeNo ratings yet
- Value-In-Use Model From Iron Ore Through Direct-Reduced Iron and Electric Arc FurnaceDocument11 pagesValue-In-Use Model From Iron Ore Through Direct-Reduced Iron and Electric Arc FurnaceGladman MundingiNo ratings yet
- State Mining Corporation: Career OpportunitiesDocument38 pagesState Mining Corporation: Career OpportunitiesRashid BumarwaNo ratings yet
- Aprroved MPS EPDocument1 pageAprroved MPS EPAlverastine AnNo ratings yet