You might also like
- SssssssssDocument7 pagesSssssssssAnonymous 2iPNmeRHsRNo ratings yet
- Estadística InferencialDocument6 pagesEstadística InferencialAlexamder Mejia RojasNo ratings yet
- Estadística Ejercicios 3Document70 pagesEstadística Ejercicios 3Sharol Nayu Parhuayo IbarraNo ratings yet
- Pruebas de hipótesis sobre medias poblacionalesDocument4 pagesPruebas de hipótesis sobre medias poblacionalesRudy Abdon Puma QuispeNo ratings yet
- Eval de Modelos de Redes 2Document3 pagesEval de Modelos de Redes 2Toño Velázquez0% (1)
- Estadística aplicada a los negocios: medidas numéricas y ejerciciosDocument1 pageEstadística aplicada a los negocios: medidas numéricas y ejerciciosomar bello loveraNo ratings yet
- ProbabilidadesDocument7 pagesProbabilidadesRandy Saboya SaavedraNo ratings yet
- Probabilidades EstadisticasDocument16 pagesProbabilidades EstadisticasJose Armando Huanca Vargas0% (1)
- Formulas MuestreoDocument4 pagesFormulas MuestreoRenzo Acevedo CanoNo ratings yet
- 9 Analisis de La Homogeneidad de Varianza HomocedasticidadDocument8 pages9 Analisis de La Homogeneidad de Varianza Homocedasticidadoscar pari castroNo ratings yet
- Muestreo: Objetivo GeneralDocument24 pagesMuestreo: Objetivo GeneralBlas AronNo ratings yet
- Unidad 4Document29 pagesUnidad 4Esteban HerreraNo ratings yet
- Muestreo Aleatorio: Estimación y AsignaciónDocument9 pagesMuestreo Aleatorio: Estimación y AsignaciónPablo Mayta100% (1)
- Introducción A La Estadística DescriptivaDocument9 pagesIntroducción A La Estadística DescriptivaJoselo ChNo ratings yet
- Taller 4 Distribuciones MuestralesDocument1 pageTaller 4 Distribuciones Muestralescesarhh59No ratings yet
- Regresion y Correlacion Lineal UacDocument9 pagesRegresion y Correlacion Lineal UacAbel Sarcco UstoNo ratings yet
- Correlación y regresión linealDocument78 pagesCorrelación y regresión linealMicky CeronNo ratings yet
- MedidasDocument50 pagesMedidasDaniel LlorenteNo ratings yet
- 6-Distribuciones TeóricasDocument31 pages6-Distribuciones TeóricasJose Adrian Zarate MercadoNo ratings yet
- Ejercicios 1Document2 pagesEjercicios 1LUIS0% (2)
- Diferencia promedios pruebas ICFES colegiosDocument3 pagesDiferencia promedios pruebas ICFES colegiosvictor chaparroNo ratings yet
- Modelo Anova y AncovaDocument5 pagesModelo Anova y AncovaDiana DíasNo ratings yet
- Intervalos de ConfianzaDocument48 pagesIntervalos de ConfianzaEver Castillo PeñaNo ratings yet
- Estadística probabilística fundamentosDocument31 pagesEstadística probabilística fundamentosAndrea AquinoNo ratings yet
- Resumenes y Analisis de Los Trabajos deDocument414 pagesResumenes y Analisis de Los Trabajos deMARIA FERNANDA DIAZ CHAVEZ0% (1)
- Parcial II - Inferencia Estadística AMB BDocument3 pagesParcial II - Inferencia Estadística AMB BNatalia Suarez RomeroNo ratings yet
- Prueba de Hipotesis Trabajo FinalDocument8 pagesPrueba de Hipotesis Trabajo Finalvampiro_vat_28100% (1)
- 22.distribuciones Muestrales Promedios 1 Y2 Ieat53-5Document7 pages22.distribuciones Muestrales Promedios 1 Y2 Ieat53-5juan LondoñoNo ratings yet
- Diseño de SondeoDocument8 pagesDiseño de SondeokendrysNo ratings yet
- Ejercicio Resuelto en RstudioDocument2 pagesEjercicio Resuelto en RstudioMatheus GTNo ratings yet
- Proyecto Socio Formativo-Estadística Inferencial (Oficial) PDFDocument12 pagesProyecto Socio Formativo-Estadística Inferencial (Oficial) PDFHilary Hurtado MontañoNo ratings yet
- Trabajo Intervalos de Confianza para La Varianza de Una PoblacionDocument9 pagesTrabajo Intervalos de Confianza para La Varianza de Una PoblacionRobert ThomasNo ratings yet
- TEMA5PROBABILIDADDocument15 pagesTEMA5PROBABILIDADEder Ram0% (1)
- Promedio, DesviacionDocument3 pagesPromedio, DesviacionXiilvy Mrll CntrsNo ratings yet
- Pruebas No Paramétricas para Una Sola MuestraDocument3 pagesPruebas No Paramétricas para Una Sola MuestraDante Palacios ValdiviezoNo ratings yet
- Diagrama de AsmeDocument9 pagesDiagrama de AsmeAndree Victor Santiago NinatantaNo ratings yet
- Crem Helados Salitó: líder en distribución de helados en el HuilaDocument12 pagesCrem Helados Salitó: líder en distribución de helados en el HuilaTifany CaicedoNo ratings yet
- Fundamento Teórico-Estudio de MercadoDocument12 pagesFundamento Teórico-Estudio de MercadoCarlos Garcia Cuevas100% (2)
- Formulario ANOVA de Un FactorDocument1 pageFormulario ANOVA de Un FactorJaque PecuaNo ratings yet
- Caso de Plan de Gestion Del ConocimientoDocument31 pagesCaso de Plan de Gestion Del ConocimientoJENEAN_No ratings yet
- 2 Muestreo Aleatorio SimpleDocument57 pages2 Muestreo Aleatorio SimpleD.j. Planex100% (1)
- Prueba de Hipótesis CDDocument23 pagesPrueba de Hipótesis CDCarlos Caruajulca TigllaNo ratings yet
- Tema 7.2 - Intervalos de Confianza - DavidDocument13 pagesTema 7.2 - Intervalos de Confianza - DavidAndres Sanga TitoNo ratings yet
- Taller Econometría I - Preguntas clave GujaratiDocument6 pagesTaller Econometría I - Preguntas clave GujaratidanielNo ratings yet
- Informe AnaliticoDocument3 pagesInforme AnaliticoAura Moreno100% (2)
- Escala StapelDocument1 pageEscala StapelRoger Julio Caycho VasquezNo ratings yet
- TrabajoDocument7 pagesTrabajoBustamante Daniel100% (1)
- Proyecto Final EstadísticaDocument18 pagesProyecto Final EstadísticaHugo Armando Lara Viveros100% (1)
- Estadistica FinalDocument10 pagesEstadistica FinalYrene Thalia Vicos PajueloNo ratings yet
- Unidad II Descripcion de La Informacion MuestralDocument5 pagesUnidad II Descripcion de La Informacion MuestralJose Carlos GarciaNo ratings yet
- Guia de EstadísticaDocument70 pagesGuia de EstadísticaAristidesNo ratings yet
- Gráfico P (Proporción de Defectuosos)Document8 pagesGráfico P (Proporción de Defectuosos)Freiler Prado MausaNo ratings yet
- 10 Pasos de Joseph Juran y 14 de CrosbyDocument16 pages10 Pasos de Joseph Juran y 14 de CrosbyLuis Ramon Ttorres Heredia LHNo ratings yet
- Establezca Con Base Estadística. Ejercicios para Explotar Craneos.Document1 pageEstablezca Con Base Estadística. Ejercicios para Explotar Craneos.Eder Daniel Castillo100% (1)
- Test Tema 3Document7 pagesTest Tema 3paula0% (1)
- Guía de Ejercicios Prueba de KS y R Correlación de PearsonDocument2 pagesGuía de Ejercicios Prueba de KS y R Correlación de Pearsongeraldine ibarraNo ratings yet
- Estadistica Taller 2Document8 pagesEstadistica Taller 2Johana MuñozNo ratings yet
- Unidad 2-Estimaciones-HoracioRancesFonsecaCamachoDocument48 pagesUnidad 2-Estimaciones-HoracioRancesFonsecaCamachoAbraham VelázquezNo ratings yet
- GENERALDocument1 pageGENERALmaria alejandraNo ratings yet
- Os 2000002 - Ov 21000993Document1 pageOs 2000002 - Ov 21000993maria alejandraNo ratings yet
- Clasificacion de AgregadosDocument128 pagesClasificacion de Agregadosmaria alejandra0% (1)
- El amor desde la perspectiva científicaDocument3 pagesEl amor desde la perspectiva científicamaria alejandraNo ratings yet
- Memoria Os 20000003Document6 pagesMemoria Os 20000003maria alejandraNo ratings yet
- Estadistica InferencialDocument53 pagesEstadistica Inferencialmaria alejandraNo ratings yet
- Memoria Os 20000003Document6 pagesMemoria Os 20000003maria alejandraNo ratings yet
- Os 2000002 - Ov 21000993Document1 pageOs 2000002 - Ov 21000993maria alejandraNo ratings yet
- Libro 1Document4 pagesLibro 1maria alejandraNo ratings yet
- Libro 1Document4 pagesLibro 1maria alejandraNo ratings yet
- Plantilla de Cronograma para Formacion Complementaria VirtualDocument1 pagePlantilla de Cronograma para Formacion Complementaria VirtualBarreto JairoNo ratings yet
- Formación virtual y competencias laboralesDocument3 pagesFormación virtual y competencias laboralesJorge Fuentes100% (2)
- 311 Afirmado EspecificacionesDocument11 pages311 Afirmado Especificacionesdanny arteagaNo ratings yet
- Esfuerzos en pavimentos flexiblesDocument30 pagesEsfuerzos en pavimentos flexiblesu2013216278100% (1)
- Transferencia de Carga A Través de Pasadores de Carga (Dovelas)Document1 pageTransferencia de Carga A Través de Pasadores de Carga (Dovelas)maria alejandraNo ratings yet
- Talleres Textos Clase 1Document3 pagesTalleres Textos Clase 1maria alejandra100% (2)
- 3 Como Desarrollar Un Ensayo de OpinonDocument10 pages3 Como Desarrollar Un Ensayo de Opinonmaria alejandraNo ratings yet
- Esfuerzos en pavimentos flexiblesDocument30 pagesEsfuerzos en pavimentos flexiblesu2013216278100% (1)
- NTC 110 Cementos. Método para Determinar La Consistencia Normal Del Cemento Hidráulico PDFDocument6 pagesNTC 110 Cementos. Método para Determinar La Consistencia Normal Del Cemento Hidráulico PDFEdier Lagos89% (9)
- Estadistica InferencialDocument53 pagesEstadistica Inferencialmaria alejandraNo ratings yet
- 3 Como Desarrollar Un Ensayo de OpinonDocument10 pages3 Como Desarrollar Un Ensayo de Opinonmaria alejandraNo ratings yet
- 3 Como Desarrollar Un Ensayo de OpinonDocument10 pages3 Como Desarrollar Un Ensayo de Opinonmaria alejandraNo ratings yet
- Microcemento Uso InyeccionesDocument4 pagesMicrocemento Uso InyeccionesCristian AlexanderNo ratings yet
- Estadistica InferencialDocument53 pagesEstadistica Inferencialmaria alejandraNo ratings yet
- I N V - E-720-07Document2 pagesI N V - E-720-07maria alejandraNo ratings yet
- Intervalos de confianza para estadísticasDocument7 pagesIntervalos de confianza para estadísticasIsmael Bohórquez RemolinaNo ratings yet
- 3 Como Desarrollar Un Ensayo de OpinonDocument10 pages3 Como Desarrollar Un Ensayo de Opinonmaria alejandraNo ratings yet
- Laboratorio de Materiales 2 FicDocument2 pagesLaboratorio de Materiales 2 FicKathe ZornosaNo ratings yet
- Análisis de implementación de conductores ACCC y GTACSR en línea de transmisión 220 kVDocument8 pagesAnálisis de implementación de conductores ACCC y GTACSR en línea de transmisión 220 kVale_1905No ratings yet
- Linea de TiempoDocument3 pagesLinea de TiempoRonald Isaac Chavez RetisNo ratings yet
- Planificación de actividades para el desarrollo de lenguaje, coordinación motriz y conocimiento del cuerpo en preescolaresDocument6 pagesPlanificación de actividades para el desarrollo de lenguaje, coordinación motriz y conocimiento del cuerpo en preescolaresErika IñiguezNo ratings yet
- TR-01 Protocolo de Trazo y Replanteo de Tuberia AciDocument1 pageTR-01 Protocolo de Trazo y Replanteo de Tuberia AciJonatan ParedesNo ratings yet
- Articulo de InvestigaciónDocument5 pagesArticulo de InvestigaciónLuis Alberto Sanchez MoratilloNo ratings yet
- Metodos de Produccion de PetroleoDocument8 pagesMetodos de Produccion de PetroleomiguelNo ratings yet
- El duelo del paciente infantil con cáncerDocument6 pagesEl duelo del paciente infantil con cáncerLiana Pérez RodríguezNo ratings yet
- Revista: Natura Cosmeticos. Com - ArDocument174 pagesRevista: Natura Cosmeticos. Com - ArJoy RomeroNo ratings yet
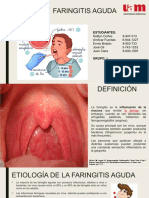
- Faringitis AgudaDocument12 pagesFaringitis AgudaMarta GaitanNo ratings yet
- Dominio en El TiempoDocument21 pagesDominio en El TiempoKansocrah NakNo ratings yet
- Cancionero Grupo Guías y Scout PaicavíDocument18 pagesCancionero Grupo Guías y Scout PaicavíFrancisco ValdesNo ratings yet
- Los SismosDocument5 pagesLos Sismosmarian Loid 888No ratings yet
- 18649-Texto Del Artículo-73935-1-10-20170602Document11 pages18649-Texto Del Artículo-73935-1-10-20170602Valentina CastañedaNo ratings yet
- Fármacos Hipolipemiantes: HipercolesterolemiaDocument21 pagesFármacos Hipolipemiantes: HipercolesterolemiaAivree DreowoneNo ratings yet
- Formación y Estructura Económica de La Hacienda en Nueva EspañaDocument2 pagesFormación y Estructura Económica de La Hacienda en Nueva EspañaJuan Eliel GarciaNo ratings yet
- Energia Solar Fotovoltaica Comunidad ValencianaDocument4 pagesEnergia Solar Fotovoltaica Comunidad ValencianaBlanca Gomez Rodriguez-AriasNo ratings yet
- 3.1.19 Sensores para Monitorización DSUDocument34 pages3.1.19 Sensores para Monitorización DSURobben WhiteNo ratings yet
- Efecto fotoeléctrico guía laboratorio virtualDocument8 pagesEfecto fotoeléctrico guía laboratorio virtualJhonny PalominoNo ratings yet
- Leucemias AgudasDocument45 pagesLeucemias AgudasKaren Ramirez PorrasNo ratings yet
- Clínica IV. Semana 2. Orientac Estudio IndependienteDocument6 pagesClínica IV. Semana 2. Orientac Estudio IndependienteTibaira FrancoNo ratings yet
- Que Tipos de Vitaminas ExistenDocument7 pagesQue Tipos de Vitaminas ExistenEleazarColladoNo ratings yet
- Examen 2do BachilleratoDocument3 pagesExamen 2do BachilleratoAndrés EspinozaNo ratings yet
- Rúbrica de Evaluación-Role PlayDocument1 pageRúbrica de Evaluación-Role PlayLluvia YCNo ratings yet
- Propiedad Horizontal PresupuestoDocument16 pagesPropiedad Horizontal PresupuestoCristobal Martinez EchavarriaNo ratings yet
- Como Se Puede Hacer Una Clase Invertida RDocument3 pagesComo Se Puede Hacer Una Clase Invertida Rapi-399932263No ratings yet
- Diagnostico Inicial Matematica 6basicoDocument9 pagesDiagnostico Inicial Matematica 6basicoDaisy MuñozNo ratings yet
- Subestacion UnmsmDocument17 pagesSubestacion UnmsmMartín Jesús Nieto MartinezNo ratings yet
- Sopa de LetrasDocument8 pagesSopa de LetrasluamanuelalondonoNo ratings yet
- La Tecnología, La(s) Cultura(s) Tecnológica(s) y La Educación Popular en Tiempos de GlobalizaciónDocument41 pagesLa Tecnología, La(s) Cultura(s) Tecnológica(s) y La Educación Popular en Tiempos de GlobalizaciónLaura ZarazaNo ratings yet
- 2 HL Envases y EmbalajesDocument71 pages2 HL Envases y EmbalajesCarito PinherNo ratings yet