You might also like
- Analisis de Datos CuantitativosDocument7 pagesAnalisis de Datos CuantitativoskevinNo ratings yet
- Conocimiento Científico PDFDocument2 pagesConocimiento Científico PDFMily GVNo ratings yet
- Control Del Ciclo LogísticoDocument18 pagesControl Del Ciclo LogísticoBenedicto VillagraNo ratings yet
- Tema 04 - Hombre CreativoDocument30 pagesTema 04 - Hombre CreativoJorge Luis Surichaqui CervantesNo ratings yet
- InvestigacionDocument11 pagesInvestigacionliborbor_0484No ratings yet
- Epistemología de La AdministraciónDocument3 pagesEpistemología de La AdministraciónDiegoAlejandroChavêzNo ratings yet
- Tipos de Hipótesis-Villamonte Chan JoaquínDocument13 pagesTipos de Hipótesis-Villamonte Chan JoaquínJoaquin VillamonteNo ratings yet
- Proceso Estrategico IIDocument43 pagesProceso Estrategico IIAndrésSanabriaMoreno67% (3)
- Mitos y Falacias de La InvestigaciónDocument17 pagesMitos y Falacias de La InvestigaciónJaime Delgado RamosNo ratings yet
- Cuento Sobre El LiderazgoDocument1 pageCuento Sobre El LiderazgoAlbertoNo ratings yet
- Antes de Que Te Vayas Quiero Decirte PDFDocument12 pagesAntes de Que Te Vayas Quiero Decirte PDFJohana GuerreroNo ratings yet
- Inteligencias MultiplesDocument6 pagesInteligencias Multiplesadriana jimenezNo ratings yet
- Guia Proveedor Supermercados Walmart - ELFFIL20130731 - 0049 PDFDocument9 pagesGuia Proveedor Supermercados Walmart - ELFFIL20130731 - 0049 PDFoctaviokreaNo ratings yet
- Trabajo Equivalente Al Tercer ParcialDocument12 pagesTrabajo Equivalente Al Tercer ParcialedouardNo ratings yet
- ALONSO GUINEA, NURIA - Inteligencias Multiples y Literatura PDFDocument47 pagesALONSO GUINEA, NURIA - Inteligencias Multiples y Literatura PDFjavi_gozaloNo ratings yet
- Taller de TesisDocument7 pagesTaller de TesisRafael Julian Malpartida YapiasNo ratings yet
- Características CualitativaDocument5 pagesCaracterísticas CualitativaYineth ArtunduagaNo ratings yet
- Cuadros Comparativos de La Modificaciones de La Ley de La Micro y Mediana EmpresaDocument5 pagesCuadros Comparativos de La Modificaciones de La Ley de La Micro y Mediana EmpresaEdi EspinozaNo ratings yet
- Actividaa 3.Document3 pagesActividaa 3.Mary MVNo ratings yet
- Tarea IdentificacionDocument11 pagesTarea IdentificacionWinfrid Cahuich GomezNo ratings yet
- Habilidades Del Pensamiento TareaDocument13 pagesHabilidades Del Pensamiento Tareaitzel velazquezNo ratings yet
- Guía para elaborar tesisDocument123 pagesGuía para elaborar tesisLuis M. AtayNo ratings yet
- Guía para Elaborar La Tesis ZORILLADocument123 pagesGuía para Elaborar La Tesis ZORILLAomarNo ratings yet
- Taller 2 Metodologia de La InvestigaciónDocument2 pagesTaller 2 Metodologia de La InvestigaciónDiego VargasNo ratings yet
- Prieto Uribe Diana Nidia Programa de Intervencion Inteligencias MultiplesDocument31 pagesPrieto Uribe Diana Nidia Programa de Intervencion Inteligencias MultiplesDiana Nidia Prieto UribeNo ratings yet
- Operacionalización de La VariableDocument2 pagesOperacionalización de La VariableOskar RaymeNo ratings yet
- Trabajo Análisis EstadísticoDocument10 pagesTrabajo Análisis EstadísticoDiana Karina Ramirez TorresNo ratings yet
- Tarea Procesos de MemoriaDocument8 pagesTarea Procesos de MemoriaMaritaElyNo ratings yet
- Web QuestDocument8 pagesWeb QuestEESMesondeFierroNo ratings yet
- Marco Referencial PDFDocument28 pagesMarco Referencial PDFJAIME100% (1)
- Taller de TesisDocument8 pagesTaller de TesisOmar Bazán NavarroNo ratings yet
- Test de LiderazgoDocument4 pagesTest de LiderazgoDiana LopezNo ratings yet
- Enfoques MixtosDocument5 pagesEnfoques MixtosOnesis PerSantNo ratings yet
- Análisis de Instrumentos de Medición Del Pensamiento CríticoDocument10 pagesAnálisis de Instrumentos de Medición Del Pensamiento CríticoYohan Alberto Manco DurangoNo ratings yet
- Trabajo 2 Sandra AhumadaDocument10 pagesTrabajo 2 Sandra AhumadaSandra Liliana Ahumada100% (1)
- El problema científico: identificación y planteamientoDocument36 pagesEl problema científico: identificación y planteamientoAnnie MNNo ratings yet
- TA06 PalmerosMontielDocument10 pagesTA06 PalmerosMontielAddí Israel Palmeros MontielNo ratings yet
- Para Trabajar EneroDocument6 pagesPara Trabajar EneroYenersy AlmánzarNo ratings yet
- Creación de una prueba de aptitudes escolaresDocument34 pagesCreación de una prueba de aptitudes escolaresCarlos ArmasNo ratings yet
- UNIR - Identificación y Atención A Problemas Visuales - KJHPDocument7 pagesUNIR - Identificación y Atención A Problemas Visuales - KJHPJoana HernandezNo ratings yet
- Metacognicion y AprendizajeDocument17 pagesMetacognicion y Aprendizajecidbud100% (1)
- Semana 5 - Cultura OrganizacionalDocument22 pagesSemana 5 - Cultura OrganizacionalIvette Campos AriasNo ratings yet
- Analisis CorrelacionalDocument30 pagesAnalisis CorrelacionalEduardo Vélez100% (1)
- Kaizen Mejora Continua Sistema LeanDocument21 pagesKaizen Mejora Continua Sistema LeanLic. Jorge Ricardo Gámez Elizondo:.No ratings yet
- Modelos de Inteligencia EmocionalDocument27 pagesModelos de Inteligencia EmocionalJosué ClímacoNo ratings yet
- Actividad 1 - Comparando Miradas PDFDocument9 pagesActividad 1 - Comparando Miradas PDFYency GuayaboNo ratings yet
- DiseñoinstruccionalDocument17 pagesDiseñoinstruccionalinteligenciapuraNo ratings yet
- Clase N°7 - Metodología de InvestigaciónDocument19 pagesClase N°7 - Metodología de InvestigaciónSebastian IgnacioNo ratings yet
- Medicion DidacticaDocument11 pagesMedicion DidacticaShinobi Perez PerezNo ratings yet
- PROYECTO para DISLEXIADocument9 pagesPROYECTO para DISLEXIAIsabel Monroy100% (1)
- Qué Es El Diseño de InvestigaciónDocument7 pagesQué Es El Diseño de InvestigaciónAngel Hbt CartelNo ratings yet
- 0.investigacion en 10 Pasos. IntroDocument8 pages0.investigacion en 10 Pasos. IntroEdison Coimbra G.No ratings yet
- Tema8 Investigacion AccionDocument30 pagesTema8 Investigacion AccionAnyi AlbaNo ratings yet
- Felicidad Como Proyecto PersonalDocument7 pagesFelicidad Como Proyecto PersonalValeria TorresNo ratings yet
- Adaptacion Curricular SECUNDARIADocument78 pagesAdaptacion Curricular SECUNDARIApatyalvaNo ratings yet
- Ciclo de Vida de Un EquipoDocument24 pagesCiclo de Vida de Un EquipoRicardo Deveze GarciaNo ratings yet
- Tema Tres Diseño de Esperimentos. Estadistica Inf2Document16 pagesTema Tres Diseño de Esperimentos. Estadistica Inf2luisa velazquezNo ratings yet
- Investigación Educativa o Investigación Pedagógica PDFDocument13 pagesInvestigación Educativa o Investigación Pedagógica PDFYamith J. Fandiño100% (1)
- Actividad GlosarioDocument4 pagesActividad Glosarioangelica ipuz0% (1)
- Capitulo 10 Analisis de Los Datos CuantitativosDocument4 pagesCapitulo 10 Analisis de Los Datos CuantitativosJuan Betancourt EsparzaNo ratings yet
- ERmodelo LogicoDocument1 pageERmodelo LogicoGedeoni ChNo ratings yet
- C++ 01Document107 pagesC++ 01Dave SGNo ratings yet
- Articulo Java Awt GraphicsDocument11 pagesArticulo Java Awt GraphicsGedeoni ChNo ratings yet
- GUÍA METODOLÓGICA Completa Abril 12 de 2013Document55 pagesGUÍA METODOLÓGICA Completa Abril 12 de 2013Gedeoni ChNo ratings yet
- Ejercicios de Programacion en JavaDocument213 pagesEjercicios de Programacion en JavaNetza Lopez75% (4)
- Trabajan DoDocument17 pagesTrabajan DoGedeoni ChNo ratings yet
- Explicacion de Diagramas de FaseDocument25 pagesExplicacion de Diagramas de FaseArmando Martinez GNo ratings yet
- Laboratorio 05 Cena de FilósofosDocument2 pagesLaboratorio 05 Cena de FilósofosGedeoni ChNo ratings yet
- Formato Alquiler - Contrato de ArrendamientoDocument1 pageFormato Alquiler - Contrato de ArrendamientoGedeoni ChNo ratings yet
- Part 3 Investigacion 12Document6 pagesPart 3 Investigacion 12Gedeoni ChNo ratings yet
- Proyecto de Culto JovenDocument11 pagesProyecto de Culto JovenGedeoni ChNo ratings yet
- Eugenia Bahit - Poo y MVC en PHPDocument66 pagesEugenia Bahit - Poo y MVC en PHPRamón Villa100% (1)
- ScrumDocument41 pagesScrumGedeoni ChNo ratings yet
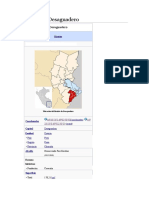
- Distrito Desaguadero PerúDocument3 pagesDistrito Desaguadero PerúGedeoni ChNo ratings yet
- Informe de Apertura Del Ministerio JovenDocument7 pagesInforme de Apertura Del Ministerio JovenGedeoni ChNo ratings yet
- Choclitos ClubDocument1 pageChoclitos ClubGedeoni ChNo ratings yet
- El Ciclo Económico en América LatinaDocument9 pagesEl Ciclo Económico en América LatinaGedeoni ChNo ratings yet
- Ideales Club de Conquistadores JADocument1 pageIdeales Club de Conquistadores JAGedeoni ChNo ratings yet
- CARATULASDocument3 pagesCARATULASGedeoni ChNo ratings yet
- CONQUISMATCH 2013 (Corregido Aql Envio Borrador)Document11 pagesCONQUISMATCH 2013 (Corregido Aql Envio Borrador)yoelito_06No ratings yet
- Plan de Monitoreo 2014Document11 pagesPlan de Monitoreo 2014Gedeoni ChNo ratings yet
- Compromiso de Gestión 1Document5 pagesCompromiso de Gestión 1Gedeoni ChNo ratings yet
- El Arte de EnseniarDocument6 pagesEl Arte de EnseniarGedeoni ChNo ratings yet
- Casos Uso UMLDocument33 pagesCasos Uso UMLCharito JaramilloNo ratings yet
- Casos de UsoDocument18 pagesCasos de UsoCarlos Alberto PriviteraNo ratings yet
- IpV4 e IpV6Document6 pagesIpV4 e IpV6Gedeoni ChNo ratings yet
- ModenDocument11 pagesModenGedeoni ChNo ratings yet
- System Praise: CaracteristicasDocument1 pageSystem Praise: CaracteristicasGedeoni ChNo ratings yet
- SCANER COPORAQUEqDocument2 pagesSCANER COPORAQUEqGedeoni ChNo ratings yet
- Cap. 3 EXPERIMENTOS CON UN SOLO FACTORDocument105 pagesCap. 3 EXPERIMENTOS CON UN SOLO FACTORJheri Teddy Alcon YujraNo ratings yet
- Estadistica IIDocument7 pagesEstadistica IILoaiza María Carolina100% (1)
- Semana 3 - A - Medidas de Dispersion PDFDocument9 pagesSemana 3 - A - Medidas de Dispersion PDFLeon Vara brianNo ratings yet
- 746 - TPS - 2 - 9141704 - Monsalve JoseDocument12 pages746 - TPS - 2 - 9141704 - Monsalve Josejose monsalveNo ratings yet
- Probabilidad pieza defectuosa máquina producción fábricaDocument4 pagesProbabilidad pieza defectuosa máquina producción fábricaRony Yerko CabreraNo ratings yet
- Estadística General: SilaboDocument5 pagesEstadística General: SilaboPaty V V Always be happyNo ratings yet
- Estadística descriptiva muestrasDocument8 pagesEstadística descriptiva muestrasMikeyla RomeroNo ratings yet
- Ejercicios Libro Probabilidad y EstadisticaDocument7 pagesEjercicios Libro Probabilidad y EstadisticaSofia CamposNo ratings yet
- U3 Estadísticas2Document23 pagesU3 Estadísticas2VICTOR MORONo ratings yet
- Sesión5-Regresión y Correlación Lineal-2023-I-NuevoDocument27 pagesSesión5-Regresión y Correlación Lineal-2023-I-NuevoCristhel LunaNo ratings yet
- Grupo 06 Practica N. 03 EstadisticaDocument25 pagesGrupo 06 Practica N. 03 EstadisticaMaria Fernanda Acosta MontoyaNo ratings yet
- EstadisticaDocument11 pagesEstadisticaBayron Alexander RODRIGUEZ ESPITIANo ratings yet
- Curva de Aprendizaje (Jimmy Icabalzeta)Document62 pagesCurva de Aprendizaje (Jimmy Icabalzeta)Pedro SilvestriNo ratings yet
- Algar RoboDocument5 pagesAlgar Robokaprino3No ratings yet
- Actividad 3, TallerDocument4 pagesActividad 3, TallerCristian GaleanoNo ratings yet
- B. Diseño Experimental 2k Con Punto Central en La Lixiviación 1) Experimentos Realizados. Según El Diseño Experimental PlanteadoDocument7 pagesB. Diseño Experimental 2k Con Punto Central en La Lixiviación 1) Experimentos Realizados. Según El Diseño Experimental PlanteadoEfrain TunquiNo ratings yet
- Interpretación Del Reporte ProgBAv2Document19 pagesInterpretación Del Reporte ProgBAv2Christian Saldaña DonayreNo ratings yet
- Estrategias Definir Tamaño de MuestraDocument7 pagesEstrategias Definir Tamaño de MuestraJoselyn AndreaNo ratings yet
- Tarea 1. Probabilidad y EstadísticaDocument8 pagesTarea 1. Probabilidad y EstadísticaNancy CarapiaNo ratings yet
- Paso 3 - Jhonatan QuinteroDocument15 pagesPaso 3 - Jhonatan QuinteroElkin Ortiz VasquezNo ratings yet
- Actividad 4 Medidas de DispersionDocument3 pagesActividad 4 Medidas de DispersionWilliam Enrique Blanco Balza100% (1)
- Instituto de Ciencias y Estudios Superiores de Tamaulipas A.C: Actividades de BioestadísticaDocument11 pagesInstituto de Ciencias y Estudios Superiores de Tamaulipas A.C: Actividades de BioestadísticadrvillamxNo ratings yet
- Distribución Hipergeométrica Juan Camilo Ibañez ArgotyDocument6 pagesDistribución Hipergeométrica Juan Camilo Ibañez ArgotyTatiana JuradoNo ratings yet
- Frecuencia y Hipotesis - ADocument8 pagesFrecuencia y Hipotesis - ARikardoBarbozaNo ratings yet
- Monografia de GeoestadisticaDocument23 pagesMonografia de GeoestadisticaKhriztian Jack CBNo ratings yet
- MEDIAMUESTRAL ESTMADOR PUNTUAL DE LA MEDIAPOBLACIONALDocument16 pagesMEDIAMUESTRAL ESTMADOR PUNTUAL DE LA MEDIAPOBLACIONALJonatan GamalielNo ratings yet
- Aplicación Con El Uso Del Software Estadístico SPSSDocument8 pagesAplicación Con El Uso Del Software Estadístico SPSSDanielRiosRoblesNo ratings yet
- Ejercicio 2Document38 pagesEjercicio 2NADIA JACQUELINE SANDOVAL ZURITANo ratings yet
- Taller 04 Ejercicio de EstadisticaDocument4 pagesTaller 04 Ejercicio de EstadisticaAlexandra Isabel Elias VelasquezNo ratings yet