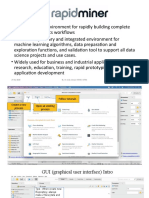
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Time Table FEAS - BME - Fall 2020 (V-01)Document5 pagesTime Table FEAS - BME - Fall 2020 (V-01)farsunNo ratings yet
- Lec 03 (BSP) Inverse Z-TransformDocument12 pagesLec 03 (BSP) Inverse Z-TransformfarsunNo ratings yet
- RIU-Signals-SystemsDocument11 pagesRIU-Signals-SystemsfarsunNo ratings yet
- Research Methodology OutlineDocument2 pagesResearch Methodology OutlinefarsunNo ratings yet
- Lec 01-Introduction To Biomedical Signal ProcessingDocument35 pagesLec 01-Introduction To Biomedical Signal ProcessingfarsunNo ratings yet
- Rabbi hablii mil ladunnka zhurriy-yatan Tay-yibahDocument2 pagesRabbi hablii mil ladunnka zhurriy-yatan Tay-yibahfarsunNo ratings yet
- Lec05 (S&S) Systems and PropertiesDocument39 pagesLec05 (S&S) Systems and PropertiesfarsunNo ratings yet
- INTERNATIONAL ADMISSIONDocument21 pagesINTERNATIONAL ADMISSIONfarsunNo ratings yet
- Signals and Systems With MATLAB Applications - Steven T. KarrisDocument598 pagesSignals and Systems With MATLAB Applications - Steven T. KarrisEugen LupuNo ratings yet
- Structures For Discrete-Time SystemsDocument30 pagesStructures For Discrete-Time SystemsfarsunNo ratings yet
- 2016 3 28 (Basic Electronics) - OutlineDocument3 pages2016 3 28 (Basic Electronics) - OutlinefarsunNo ratings yet
- Biomedical Image ProcessingDocument3 pagesBiomedical Image ProcessingfarsunNo ratings yet
- Amplifier OperationDocument44 pagesAmplifier OperationfarsunNo ratings yet
- 05-ML (Linear Regression)Document31 pages05-ML (Linear Regression)farsunNo ratings yet
- Lec 01-Research MethodologyDocument46 pagesLec 01-Research MethodologyfarsunNo ratings yet
- EE-212 Circuit Analysis Course OverviewDocument3 pagesEE-212 Circuit Analysis Course OverviewfarsunNo ratings yet
- BJT Amplifier Biasing and OperationDocument36 pagesBJT Amplifier Biasing and OperationfarsunNo ratings yet
- 07-AC Circuit AnalysisDocument45 pages07-AC Circuit AnalysisfarsunNo ratings yet
- Digital Image Processing LecturesDocument46 pagesDigital Image Processing LecturesfarsunNo ratings yet
- 01-PN Junction and DiodesDocument46 pages01-PN Junction and DiodesfarsunNo ratings yet
- DIP Lecture-3-6Document64 pagesDIP Lecture-3-6farsunNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- RPA in The Credit Card Industry PDFDocument10 pagesRPA in The Credit Card Industry PDFArunBaluPazhayannur100% (1)
- Group 6 Research PaperDocument4 pagesGroup 6 Research Paper202210756No ratings yet
- Robots Will Steal Your Job, But That's OKDocument57 pagesRobots Will Steal Your Job, But That's OKDestoviNo ratings yet
- Industrial Training ReportDocument33 pagesIndustrial Training ReportVishakha TandonNo ratings yet
- Neural Network - DR - Nadir N. CharniyaDocument20 pagesNeural Network - DR - Nadir N. Charniyaymcm2010No ratings yet
- Xcede Salary GuideDocument10 pagesXcede Salary GuideJoel Cerqueira PonteNo ratings yet
- THE Dice Tech Salary: 2021 EDITIONDocument36 pagesTHE Dice Tech Salary: 2021 EDITIONSurendiran DhayalarajanNo ratings yet
- Two-Stage Filter Response Normalization Network For Real Image DenoisingDocument5 pagesTwo-Stage Filter Response Normalization Network For Real Image DenoisingMay Thet TunNo ratings yet
- Dissertation Topics in Organisational PsychologyDocument4 pagesDissertation Topics in Organisational PsychologyAcademicPaperWritersCanada100% (1)
- Algorithms For Predictive Maintenance Efficiently Developed With MatlabDocument22 pagesAlgorithms For Predictive Maintenance Efficiently Developed With MatlabHanif AndiNo ratings yet
- Welding Defect Classification Based On Convolution Neural Network (CNN) and Gaussian KernelDocument5 pagesWelding Defect Classification Based On Convolution Neural Network (CNN) and Gaussian KernelĐào Văn HưngNo ratings yet
- KPMG Ignite Unlocks The Value of AIDocument1 pageKPMG Ignite Unlocks The Value of AIPallavi ReddyNo ratings yet
- Human Trafficking and Technology Trends Challenges and Opportunities WEB PDFDocument6 pagesHuman Trafficking and Technology Trends Challenges and Opportunities WEB PDFSijal zafarNo ratings yet
- Deeplearning - Ai Deeplearning - AiDocument43 pagesDeeplearning - Ai Deeplearning - AiLê TườngNo ratings yet
- UCS RM Intro-EtlDocument30 pagesUCS RM Intro-Etlnur ashfaralianaNo ratings yet
- ClusteringDocument17 pagesClusteringAatri PalNo ratings yet
- BIM PTPP PalembangDocument21 pagesBIM PTPP PalembangSiti Aisyah NurjannahNo ratings yet
- Human Rights in The Age of Social MediaDocument3 pagesHuman Rights in The Age of Social MediaAlnur PrmakhanNo ratings yet
- A Review On Question and Answer System For Covid-19 Literature On Pre-Trained ModelsDocument4 pagesA Review On Question and Answer System For Covid-19 Literature On Pre-Trained ModelsIJAR JOURNALNo ratings yet
- 72552Document8 pages72552Andres GuevaraNo ratings yet
- ML Lecture 3 Optimization Linear ClassificationDocument15 pagesML Lecture 3 Optimization Linear ClassificationRahul VasanthNo ratings yet
- Urban AI: Understanding The Emerging Role of Artificial Intelligence in Smart CitiesDocument6 pagesUrban AI: Understanding The Emerging Role of Artificial Intelligence in Smart CitiesMiguel R MoNo ratings yet
- Regulariza On: The Problem of Overfi6ngDocument19 pagesRegulariza On: The Problem of Overfi6ngAnilSiwakotiNo ratings yet
- AWS SageMaker MLDocument1,588 pagesAWS SageMaker MLzimo80100% (1)
- DFA MinimizationDocument10 pagesDFA MinimizationMahesh ThosarNo ratings yet
- Digital Pakistan PolicyDocument24 pagesDigital Pakistan PolicySardar RowaisNo ratings yet
- Allen 2020Document32 pagesAllen 2020Melor MasdokiNo ratings yet
- Course Outlines-SemesterDocument7 pagesCourse Outlines-SemesterZara TariqNo ratings yet
- Gartner Seven Imperatives To AdoptDocument24 pagesGartner Seven Imperatives To AdoptmstorentNo ratings yet
- Chatbots and Health: Mental Health History of AI-powered ChatbotsDocument7 pagesChatbots and Health: Mental Health History of AI-powered Chatbotsstevenkanyanjua1No ratings yet