You might also like
- Sad ERDocument25 pagesSad ERpoonamNo ratings yet
- Second Lecture Softquality SystemDocument55 pagesSecond Lecture Softquality SystempoonamNo ratings yet
- Software Quality ManagementDocument64 pagesSoftware Quality ManagementpoonamNo ratings yet
- SadDocument35 pagesSadGunjan AroraNo ratings yet
- Jar FileDocument8 pagesJar Filepoonam100% (1)
- Sad 4Document17 pagesSad 4poonamNo ratings yet
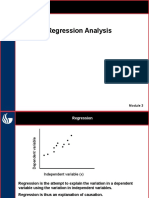
- Regression in Data MiningDocument15 pagesRegression in Data MiningpoonamNo ratings yet
- Very Very Important Data Mining and Clustering - Benjamin Lam 1Document49 pagesVery Very Important Data Mining and Clustering - Benjamin Lam 1poonamNo ratings yet
- Introduction To Hive: Liyin Tang Liyintan@usc - EduDocument24 pagesIntroduction To Hive: Liyin Tang Liyintan@usc - EdupoonamNo ratings yet
- Final HashingDocument23 pagesFinal HashingpoonamNo ratings yet
- Software Configuaration Management NewDocument59 pagesSoftware Configuaration Management NewpoonamNo ratings yet
- Very Important Waht Is Data Warehouse and Why RequiredDocument26 pagesVery Important Waht Is Data Warehouse and Why RequiredpoonamNo ratings yet
- Recursionexaplanation of Recursion Very Much ImportantDocument6 pagesRecursionexaplanation of Recursion Very Much ImportantpoonamNo ratings yet
- TreeiimalectureDocument19 pagesTreeiimalecturepoonamNo ratings yet
- Very Improtant NormalisationDocument5 pagesVery Improtant NormalisationpoonamNo ratings yet
- What Are Differences Between Arrays and CollectionsDocument2 pagesWhat Are Differences Between Arrays and CollectionspoonamNo ratings yet
- Very Very Important Data MiningbySangeetaDocument17 pagesVery Very Important Data MiningbySangeetapoonamNo ratings yet
- Many Slides Taken From Mike Scott, UT AustinDocument41 pagesMany Slides Taken From Mike Scott, UT AustinolcheongNo ratings yet
- What Is A Data Modelvery ImportantDocument7 pagesWhat Is A Data Modelvery ImportantpoonamNo ratings yet
- Pitta Virechan ImportantDocument2 pagesPitta Virechan ImportantdevanshgomberNo ratings yet
- Iway in EcommerceDocument6 pagesIway in Ecommercepoonam75% (4)
- What Is A Package in JavaDocument4 pagesWhat Is A Package in Javapoonam100% (1)
- Pitta Virechan ImportantDocument2 pagesPitta Virechan ImportantdevanshgomberNo ratings yet
- What Is Big Data Question AnswerDocument10 pagesWhat Is Big Data Question AnswerpoonamNo ratings yet
- Dhudhi Badi ImportantDocument4 pagesDhudhi Badi ImportantpoonamNo ratings yet
- Virechan Very ImportantDocument2 pagesVirechan Very ImportantpoonamNo ratings yet
- Virechana Induced Purgation Best Treatment For Pitta ProblemsDocument2 pagesVirechana Induced Purgation Best Treatment For Pitta ProblemspoonamNo ratings yet
- Remember Allways DineshDocument1 pageRemember Allways DineshpoonamNo ratings yet
- Medicinal Use of Harsingar Fever Malria Sugar High BP Intastine ProblemDocument4 pagesMedicinal Use of Harsingar Fever Malria Sugar High BP Intastine ProblempoonamNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Sybase DBA User Guide For BeginnersDocument47 pagesSybase DBA User Guide For BeginnersRaghavendra PrabhuNo ratings yet
- Sandhya PochamreddyDocument3 pagesSandhya PochamreddyjaniNo ratings yet
- Assignment No1 - ModifiedDocument22 pagesAssignment No1 - ModifiedMukhtar AhmedNo ratings yet
- SQL Tutorial - DB2 SQL Tutorials - SQL TutorDocument2 pagesSQL Tutorial - DB2 SQL Tutorials - SQL TutorSaurabh ChoudharyNo ratings yet
- Intro To Project Engineering ToolsDocument112 pagesIntro To Project Engineering ToolselakkiyaNo ratings yet
- Oracle 1Z0-083 - Simulado 1Document37 pagesOracle 1Z0-083 - Simulado 1ikki FenixNo ratings yet
- SE Fitness Gym 2Document7 pagesSE Fitness Gym 2yoeliyyNo ratings yet
- RDBMS and Table RelationshipsDocument28 pagesRDBMS and Table RelationshipsForkensteinNo ratings yet
- s85 Hijet PDFDocument268 pagess85 Hijet PDFMade AndilalaNo ratings yet
- Business AnalyticsDocument1 pageBusiness AnalyticsDinah Ruth EscobarNo ratings yet
- Pentaho CE Vs EE - 6.1 Feature Comparision Chart PDFDocument2 pagesPentaho CE Vs EE - 6.1 Feature Comparision Chart PDFAndre FiorotNo ratings yet
- SQL Server Performance TuningDocument25 pagesSQL Server Performance TuningBang TrinhNo ratings yet
- Interview Questions - Manual and DB TestingDocument5 pagesInterview Questions - Manual and DB TestingSri Harsha PogulaNo ratings yet
- Agg AwareDocument26 pagesAgg AwareyaswanthrdyNo ratings yet
- Cursors in DbmsDocument4 pagesCursors in DbmsJugalkishore FatehchandkaNo ratings yet
- Geo Distance Search With MySQLDocument29 pagesGeo Distance Search With MySQLOleksiy Kovyrin94% (87)
- Creating A Simple File Using Source Keys: HDL HCM Data LoaderDocument2 pagesCreating A Simple File Using Source Keys: HDL HCM Data Loaderswati280591No ratings yet
- PreSales Specialist Oracle Database 11gDocument13 pagesPreSales Specialist Oracle Database 11gZoran Vidić100% (1)
- JDBC Chapter 1Document45 pagesJDBC Chapter 1kassahunNo ratings yet
- DBMS Unit 1Document23 pagesDBMS Unit 1Raj KumarNo ratings yet
- Dynamo and BigTable Review and ComparisonDocument5 pagesDynamo and BigTable Review and ComparisonAADITYANo ratings yet
- Alteryx Interview Questions and AnswersDocument23 pagesAlteryx Interview Questions and Answersrahulv2No ratings yet
- Excel Championship 2018Document2 pagesExcel Championship 2018SettAung NaingNo ratings yet
- B SRV Admin Ref Linux 8116Document1,768 pagesB SRV Admin Ref Linux 8116Christophe MOUYNo ratings yet
- HRMS DEVELOPMENT WHITE PAPER Continuous CalculationDocument19 pagesHRMS DEVELOPMENT WHITE PAPER Continuous CalculationMarwan SNo ratings yet
- SAP - ABAP Performance Tuning: Skills GainedDocument3 pagesSAP - ABAP Performance Tuning: Skills GainedAZn5ReDNo ratings yet
- Oracle ERP ER DiagramsDocument13 pagesOracle ERP ER Diagramsdxtrzat100% (2)
- Final Exam OracleDocument232 pagesFinal Exam OracleCatalina Popescu100% (1)
- Basic Usage - Clustrix DocumentationDocument3 pagesBasic Usage - Clustrix DocumentationCSKNo ratings yet
- Eleventh Workshop Tamil EpigraphyDocument1 pageEleventh Workshop Tamil EpigraphyCikgu Thanesh BalakrishnanNo ratings yet