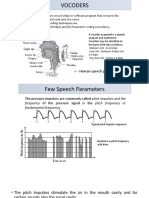
You might also like
- Speech FileDocument14 pagesSpeech FileVineet KumarNo ratings yet
- LPC Modeling: Unit 5 1.speech CompressionDocument13 pagesLPC Modeling: Unit 5 1.speech CompressionRyan ReedNo ratings yet
- Chapter 1: Introduction To Audio Signal Processing: KH WongDocument55 pagesChapter 1: Introduction To Audio Signal Processing: KH Wongvaz5zNo ratings yet
- Codec 2Document30 pagesCodec 2Bob BarkerNo ratings yet
- Human Speech Producing Organs: 2.4 KbpsDocument108 pagesHuman Speech Producing Organs: 2.4 KbpsdfbbvcxNo ratings yet
- Speech Coding TechniquesDocument38 pagesSpeech Coding TechniquesJacob JayaseelanNo ratings yet
- Adaptive Multi Rate Coder Using ACLPDocument45 pagesAdaptive Multi Rate Coder Using ACLPshah_mayanaNo ratings yet
- Xpo ComDocument5 pagesXpo ComBambang GastomoNo ratings yet
- VocoderDocument9 pagesVocoderRohit AgrawalNo ratings yet
- Lesson02 PDFDocument23 pagesLesson02 PDFMehnaz Baloch100% (1)
- Underwater Voice Communications Using Digital Techniques: B. Woodward HDocument4 pagesUnderwater Voice Communications Using Digital Techniques: B. Woodward HVinh Quang NguyenNo ratings yet
- OFDMADocument36 pagesOFDMAMostafa Mohammed EladawyNo ratings yet
- Multimedia Digital AudioDocument7 pagesMultimedia Digital AudioMohammed Abdel Khaleq DwikatNo ratings yet
- Sound and Digital AudioDocument27 pagesSound and Digital Audiogabs2No ratings yet
- A Self-Steering Digital Microphone Array: At&T NJ, UsaDocument4 pagesA Self-Steering Digital Microphone Array: At&T NJ, UsaMayssa RjaibiaNo ratings yet
- RF Receiver BasicsDocument46 pagesRF Receiver Basicsbayman66No ratings yet
- McCree MixedExcitationLPCVocoderModel ieeetSAP95Document9 pagesMcCree MixedExcitationLPCVocoderModel ieeetSAP95ΚουρδιστόςΑνανάςNo ratings yet
- Application of Microphone Array For Speech Coding in Noisy EnvironmentDocument5 pagesApplication of Microphone Array For Speech Coding in Noisy Environmentscribd1235207No ratings yet
- Training Session No.: Digital AudioDocument28 pagesTraining Session No.: Digital AudioMohd AmirNo ratings yet
- The Diagram Outlines The Key Steps Involved in CoDocument20 pagesThe Diagram Outlines The Key Steps Involved in CoTaqwa ElsayedNo ratings yet
- A Pitch Detection AlgorithmDocument6 pagesA Pitch Detection AlgorithmNavneeth NarayanNo ratings yet
- 1.1.3 SoundDocument6 pages1.1.3 SoundSarah HussainNo ratings yet
- Opus Silk CodecDocument10 pagesOpus Silk Codecproton meNo ratings yet
- CELPDocument23 pagesCELPANeek181No ratings yet
- From Ek 51 Est Coaching 1Document13 pagesFrom Ek 51 Est Coaching 1Jam MagatNo ratings yet
- Introduction To Multimedia. Analog-Digital RepresentationDocument29 pagesIntroduction To Multimedia. Analog-Digital Representationraghudathesh100% (1)
- Topic 8 Lecture: VN XN N VNDocument15 pagesTopic 8 Lecture: VN XN N VNshutup121No ratings yet
- Digital CommunicationsDocument39 pagesDigital Communicationsmakomdd100% (1)
- Dereje Teferi (PHD) Dereje - Teferi@Aau - Edu.EtDocument30 pagesDereje Teferi (PHD) Dereje - Teferi@Aau - Edu.EtdaveNo ratings yet
- DSP Lab Assignment 4Document9 pagesDSP Lab Assignment 4wafa hopNo ratings yet
- SVAN 958 Four Channels Sound & Vibration Analyser: FeaturesDocument2 pagesSVAN 958 Four Channels Sound & Vibration Analyser: FeaturesCuauhtzin Alejandro Rosales Peña AlfaroNo ratings yet
- Side Band SuppressionDocument10 pagesSide Band SuppressionTwin ParadoxNo ratings yet
- ExtraDocument44 pagesExtraJosephine Pinlac Junio100% (1)
- OFDM LectureDocument128 pagesOFDM Lectureashugolu02No ratings yet
- Introduction To SamplingDocument24 pagesIntroduction To SamplingFabio Luigi RuggieroNo ratings yet
- Software Defined Radio Handbook - 9th EditionDocument62 pagesSoftware Defined Radio Handbook - 9th EditionA. VillaNo ratings yet
- Analog Characteristics of Ultrasonic Flaw DetectorsDocument8 pagesAnalog Characteristics of Ultrasonic Flaw DetectorsbingwazzupNo ratings yet
- DCS SolnDocument6 pagesDCS SolnSandeep Kumar100% (1)
- VocoderDocument12 pagesVocoderKola OladapoNo ratings yet
- PCM (Pulse code modulation) : -Teacher: Masters Nguyễn Thanh Đức -Group memberDocument77 pagesPCM (Pulse code modulation) : -Teacher: Masters Nguyễn Thanh Đức -Group memberTao Thích Màu ĐenNo ratings yet
- AnswerDocument23 pagesAnswerplokplokplokNo ratings yet
- Waveform Coding Techniques: Document ID: 8123Document7 pagesWaveform Coding Techniques: Document ID: 8123Kugly DooNo ratings yet
- Answer 1.1%Document29 pagesAnswer 1.1%Anonymous 7puVtTdpVNo ratings yet
- SoundDocument4 pagesSoundThe Best AboodNo ratings yet
- Lab09 PDFDocument11 pagesLab09 PDFDaNo ratings yet
- Linear PredictionDocument94 pagesLinear PredictionAndreas RousalisNo ratings yet
- Audio/Speech Signal Processing: An OverviewDocument18 pagesAudio/Speech Signal Processing: An OverviewpaulNo ratings yet
- B. Tech.: Fifth Semester Examination, 2003-2004Document3 pagesB. Tech.: Fifth Semester Examination, 2003-2004Ravindra KumarNo ratings yet
- ECE 221 - AC Circuit and System LabDocument7 pagesECE 221 - AC Circuit and System Labapi-595474257No ratings yet
- Unit I Content Beyond Syllabus Introduction To Information Theory What Is "Information Theory" ?Document16 pagesUnit I Content Beyond Syllabus Introduction To Information Theory What Is "Information Theory" ?ShanmugapriyaVinodkumarNo ratings yet
- DSP-1 (Intro) (S)Document77 pagesDSP-1 (Intro) (S)karthik0433No ratings yet
- Lesson 4 - Coding of Text, Voice, Image, and VideoDocument11 pagesLesson 4 - Coding of Text, Voice, Image, and VideoLee Heng YewNo ratings yet
- BER For BPSK in OFDM With Rayleigh Multipath ChannelDocument6 pagesBER For BPSK in OFDM With Rayleigh Multipath ChannelNaveen Kumar ChadalavadaNo ratings yet
- Bat Detector Information Pack Sept 2011Document8 pagesBat Detector Information Pack Sept 2011jijil1No ratings yet
- Pentek HandbookDocument63 pagesPentek HandbookIniyavan ElumalaiNo ratings yet
- Digital Communications - Fundamentals & Applications (Q0) PDFDocument39 pagesDigital Communications - Fundamentals & Applications (Q0) PDFMohamd barcaNo ratings yet
- Department of Electronics and Communication Engineering EC 3012 Digital Communication-Monsoon 2015Document3 pagesDepartment of Electronics and Communication Engineering EC 3012 Digital Communication-Monsoon 2015shreyas_stinsonNo ratings yet
- 05 MRB Radiotherapy Technician Notification 06032018Document31 pages05 MRB Radiotherapy Technician Notification 06032018Vikas PsNo ratings yet
- Reasoning By: Arun Kumar SirDocument11 pagesReasoning By: Arun Kumar SirVikas Ps100% (1)
- Overview BrochureDocument13 pagesOverview BrochureVikas PsNo ratings yet
- 07 MOS CapacitorDocument33 pages07 MOS CapacitorVikas PsNo ratings yet
- 07 E&TE Final.Document116 pages07 E&TE Final.Vikas PsNo ratings yet
- 02 Carrier Transport PhenomenaDocument28 pages02 Carrier Transport PhenomenaVikas PsNo ratings yet
- 03 Non Equilibrium Excess CarriersDocument30 pages03 Non Equilibrium Excess CarriersVikas PsNo ratings yet
- February Monthly Magazine English 0259847a407f2Document85 pagesFebruary Monthly Magazine English 0259847a407f2Vikas PsNo ratings yet
- Feedback Amp and OscillatorDocument47 pagesFeedback Amp and OscillatorVikas PsNo ratings yet
- 01 Energy Band and SemiconductorsDocument50 pages01 Energy Band and SemiconductorsVikas PsNo ratings yet
- Sertraline-Induced DiplopiaDocument3 pagesSertraline-Induced DiplopiaVikas PsNo ratings yet
- 2014lorazepam InduceddiplopiaDocument3 pages2014lorazepam InduceddiplopiaVikas PsNo ratings yet
- SatcomDocument11 pagesSatcomVikas PsNo ratings yet
- Basic Facts About CirulatorsDocument10 pagesBasic Facts About CirulatorsVikas PsNo ratings yet
- Banki NG Awareness & Computer Knowl Edge: Pri Vate Li Mi TedDocument17 pagesBanki NG Awareness & Computer Knowl Edge: Pri Vate Li Mi TedVikas PsNo ratings yet
- Electrical Engineer Fresher Resume PDF DownloadDocument1 pageElectrical Engineer Fresher Resume PDF DownloadMûhämmåd Jûñåîd MúghålNo ratings yet
- Di/dt Noise in CMOS Integrated Circuits: Patrik LarssonDocument2 pagesDi/dt Noise in CMOS Integrated Circuits: Patrik LarssonmadhuriNo ratings yet
- TL 9000 Quality Management System Measurements Handbook NPR ExamplesDocument7 pagesTL 9000 Quality Management System Measurements Handbook NPR ExamplesMani Rathinam RajamaniNo ratings yet
- Porting uCOS-II To A PIC MicrocontrollerDocument18 pagesPorting uCOS-II To A PIC MicrocontrollerHimanshu SharmaNo ratings yet
- DS-RTCD905 H6W4Document2 pagesDS-RTCD905 H6W4david fonsecaNo ratings yet
- IDirect HubDocument6 pagesIDirect HubAsim Penkar PenkarNo ratings yet
- Battery Alarm User ManualDocument22 pagesBattery Alarm User ManualSandeep KumarNo ratings yet
- Fly by WireDocument20 pagesFly by WireAnurag RanaNo ratings yet
- Easygen-3000Xt Series: ManualDocument904 pagesEasygen-3000Xt Series: Manualincore1976No ratings yet
- Layout LPDocument6 pagesLayout LPAndrea BautistaNo ratings yet
- Power Supply and Security Alarm ProjectDocument29 pagesPower Supply and Security Alarm ProjectDhruv Gupta100% (1)
- National Institute of Technology Calicut: Digital Communication Lab ReportDocument7 pagesNational Institute of Technology Calicut: Digital Communication Lab ReportSaketh RaviralaNo ratings yet
- Class11 CacheDocument41 pagesClass11 Cacheef_irshadNo ratings yet
- Pravail APS 2100 Quick Start CardDocument4 pagesPravail APS 2100 Quick Start CardAli Ben SalahNo ratings yet
- Technical Seminar DocumentationDocument44 pagesTechnical Seminar DocumentationvenkyNo ratings yet
- AlokDocument5 pagesAlokAlok KumarNo ratings yet
- Cb-2-Du-Nf-01Document2 pagesCb-2-Du-Nf-01Huỳnh Tấn LợiNo ratings yet
- TDD HarqDocument24 pagesTDD HarqVimal Pratap SinghNo ratings yet
- Internal Guide:-Mrs. A.A. Askhedkar: by Dikita Chauhan Amita Joshi & Anuja KaradkhedkarDocument33 pagesInternal Guide:-Mrs. A.A. Askhedkar: by Dikita Chauhan Amita Joshi & Anuja KaradkhedkarMohit ChauhanNo ratings yet
- Auxiliary Relays RXMB 1 RXMB 2 and RXMC 1Document12 pagesAuxiliary Relays RXMB 1 RXMB 2 and RXMC 1jenskg100% (1)
- Ieee 1147Document48 pagesIeee 1147Jose Antonio EstofaneroNo ratings yet
- Measuring Laser Power and Energy OutputDocument5 pagesMeasuring Laser Power and Energy OutputBilel KrayniNo ratings yet
- Project MicroprocessoresDocument22 pagesProject Microprocessoresshahd dawoodNo ratings yet
- 3 DicDocument18 pages3 DicPhanindra BodduNo ratings yet
- Shuttle MN31/N ManualDocument72 pagesShuttle MN31/N ManualFlavio Betti0% (1)
- ENGG 143.02 Lab Activity 1 - ManlapazDocument3 pagesENGG 143.02 Lab Activity 1 - ManlapazJuan Glicerio C. ManlapazNo ratings yet
- Wireless Communication Lecture Notes by Dr.O.Cyril Mathew, PHD., Al-Ameen Engineering College-ErodeDocument76 pagesWireless Communication Lecture Notes by Dr.O.Cyril Mathew, PHD., Al-Ameen Engineering College-ErodeCyril Mathew0% (1)
- Lab Exercise #1: Introduction To The Cypress Fm4 Board and Fm4 Starter KitDocument12 pagesLab Exercise #1: Introduction To The Cypress Fm4 Board and Fm4 Starter KitAhmed HamoudaNo ratings yet
- Copley Absolute Encoder GuideDocument54 pagesCopley Absolute Encoder GuideAlecsandruNeacsuNo ratings yet