You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- TrigonometryDocument15 pagesTrigonometryJnanam100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Simple Harmonic Motion and ElasticityDocument105 pagesSimple Harmonic Motion and ElasticityyashveerNo ratings yet
- Datacentre Total Cost of Ownership (TCO) Models: A SurveyDocument16 pagesDatacentre Total Cost of Ownership (TCO) Models: A SurveyBilly BryanNo ratings yet
- Material Models in PlaxisDocument136 pagesMaterial Models in PlaxismpvfolloscoNo ratings yet
- Mechanical Vibration NotesDocument56 pagesMechanical Vibration NotesYadanaNo ratings yet
- Cost Model For Establishing A Data CenterDocument20 pagesCost Model For Establishing A Data CenterBilly BryanNo ratings yet
- Computer Science & Engineering: An International Journal (CSEIJ)Document2 pagesComputer Science & Engineering: An International Journal (CSEIJ)cseijNo ratings yet
- Efficient Adaptive Intra Refresh Error Resilience For 3D Video CommunicationDocument16 pagesEfficient Adaptive Intra Refresh Error Resilience For 3D Video CommunicationBilly BryanNo ratings yet
- Computer Science & Engineering: An International Journal (CSEIJ)Document2 pagesComputer Science & Engineering: An International Journal (CSEIJ)cseijNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- The Influence of Silicon Area On The Performance of The Full AddersDocument10 pagesThe Influence of Silicon Area On The Performance of The Full AddersBilly BryanNo ratings yet
- Developing A Case-Based Retrieval System For Supporting IT CustomersDocument9 pagesDeveloping A Case-Based Retrieval System For Supporting IT CustomersBilly BryanNo ratings yet
- Application of Dynamic Clustering Algorithm in Medical SurveillanceDocument5 pagesApplication of Dynamic Clustering Algorithm in Medical SurveillanceBilly BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- International Journal of Computer Science, Engineering and Applications (IJCSEA)Document11 pagesInternational Journal of Computer Science, Engineering and Applications (IJCSEA)Billy BryanNo ratings yet
- International Journal of Advanced Information Technology (IJAIT)Document1 pageInternational Journal of Advanced Information Technology (IJAIT)ijaitjournalNo ratings yet
- Scope & Topics: ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print)Document1 pageScope & Topics: ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print)Billy BryanNo ratings yet
- International Journal of Computer Science, Engineering and Applications (IJCSEA)Document9 pagesInternational Journal of Computer Science, Engineering and Applications (IJCSEA)Billy BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- Computer Science & Engineering: An International Journal (CSEIJ)Document2 pagesComputer Science & Engineering: An International Journal (CSEIJ)cseijNo ratings yet
- Data Partitioning For Ensemble Model BuildingDocument7 pagesData Partitioning For Ensemble Model BuildingAnonymous roqsSNZNo ratings yet
- Computer Science & Engineering: An International Journal (CSEIJ)Document2 pagesComputer Science & Engineering: An International Journal (CSEIJ)cseijNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- International Journal of Advanced Information Technology (IJAIT)Document1 pageInternational Journal of Advanced Information Technology (IJAIT)ijaitjournalNo ratings yet
- Hybrid Database System For Big Data Storage and ManagementDocument13 pagesHybrid Database System For Big Data Storage and ManagementBilly BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- International Journal of Computer Science, Engineering and Applications (IJCSEA)Document2 pagesInternational Journal of Computer Science, Engineering and Applications (IJCSEA)Billy BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- International Journal of Computer Science, Engineering and Applications (IJCSEA)Document2 pagesInternational Journal of Computer Science, Engineering and Applications (IJCSEA)Billy BryanNo ratings yet
- ISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsDocument1 pageISSN: 2230 - 9616 (Online) 2231 - 0088 (Print) Scope & TopicsBilly BryanNo ratings yet
- International Journal of Computer Science, Engineering and Applications (IJCSEA)Document2 pagesInternational Journal of Computer Science, Engineering and Applications (IJCSEA)Billy BryanNo ratings yet
- Tom Two Mark QuestionDocument23 pagesTom Two Mark QuestionTamil SelvanNo ratings yet
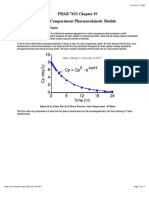
- PHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsDocument23 pagesPHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsBandameedi RamuNo ratings yet
- Stratified Random Sampling PrecisionDocument10 pagesStratified Random Sampling PrecisionEPAH SIRENGONo ratings yet
- Mat 510 Week 11 Final Exam Latest StrayerDocument4 pagesMat 510 Week 11 Final Exam Latest StrayercoursehomeworkNo ratings yet
- Udl Exchange LessonDocument4 pagesUdl Exchange Lessonapi-297083252No ratings yet
- Report On Fingerprint Recognition SystemDocument9 pagesReport On Fingerprint Recognition Systemaryan singhalNo ratings yet
- Selection, Bubble, Insertion Sorts & Linear Binary Search ExplainedDocument5 pagesSelection, Bubble, Insertion Sorts & Linear Binary Search ExplainedAndrew MagdyNo ratings yet
- ECON 233-Introduction To Game Theory - Husnain Fateh AhmadDocument7 pagesECON 233-Introduction To Game Theory - Husnain Fateh AhmadAdeel ShaikhNo ratings yet
- F Distribution - TableDocument2 pagesF Distribution - TableanupkewlNo ratings yet
- Full Download Ebook Ebook PDF Mathematics in Action Algebraic Graphical and Trigonometric Problem Solving 5th Edition PDFDocument42 pagesFull Download Ebook Ebook PDF Mathematics in Action Algebraic Graphical and Trigonometric Problem Solving 5th Edition PDFwillie.ortiz343100% (41)
- Governor System (Electrical Part)Document142 pagesGovernor System (Electrical Part)የፐፐፐ ነገርNo ratings yet
- Irace Comex TutorialDocument5 pagesIrace Comex TutorialOmarSerranoNo ratings yet
- Writing Scientific NotationDocument2 pagesWriting Scientific NotationkolawoleNo ratings yet
- CISE-302-Linear-Control-Systems-Lab-Manual 1Document22 pagesCISE-302-Linear-Control-Systems-Lab-Manual 1ffffffNo ratings yet
- The Relationship Between Capital Structure and Firm Performance - New Evidence From PakistanDocument12 pagesThe Relationship Between Capital Structure and Firm Performance - New Evidence From Pakistanhammadshah786No ratings yet
- Structure Chap-7 Review ExDocument7 pagesStructure Chap-7 Review Exabenezer g/kirstosNo ratings yet
- SpecimenDocument31 pagesSpecimenSerge DemirdjianNo ratings yet
- How Rebar Distribution Affects Concrete Beam Flexural StrengthDocument10 pagesHow Rebar Distribution Affects Concrete Beam Flexural Strengthtoma97No ratings yet
- Calculate stock indices and returnsDocument5 pagesCalculate stock indices and returnsSiddhant AggarwalNo ratings yet
- Relation between resolution III and confounded responsesDocument50 pagesRelation between resolution III and confounded responsesrohitrealisticNo ratings yet
- Trigonometric Functions and Equations (Unit - 1)Document76 pagesTrigonometric Functions and Equations (Unit - 1)Santosh YaramatiNo ratings yet
- 04 Handout 1 (Feedback)Document11 pages04 Handout 1 (Feedback)Kathleen Anne MendozaNo ratings yet
- Mock Test Paper 2013 (Answers)Document84 pagesMock Test Paper 2013 (Answers)Varun GuptaNo ratings yet
- The 3-Rainbow Index of GraphsDocument28 pagesThe 3-Rainbow Index of GraphsDinda KartikaNo ratings yet
- Mark Scheme (Results) January 2007: GCE Mathematics Statistics (6683)Document8 pagesMark Scheme (Results) January 2007: GCE Mathematics Statistics (6683)ashiqueNo ratings yet