You might also like
- Aim Assignment 3Document10 pagesAim Assignment 3BARATH PNo ratings yet
- Modeling and Simulation CS 313Document23 pagesModeling and Simulation CS 313Govinda RajuNo ratings yet
- Assembly Lines: Worked Out ProblemsDocument8 pagesAssembly Lines: Worked Out ProblemsAnonymous cKmoKeXCpNo ratings yet
- 3.2 Performance EvaluationsDocument18 pages3.2 Performance EvaluationsChetan SolankiNo ratings yet
- Unit 2Document8 pagesUnit 2guddinan makureNo ratings yet
- Chapter 02Document12 pagesChapter 02declutteracc1No ratings yet
- Modeling sporadic jobs and analyzing task utilizationDocument37 pagesModeling sporadic jobs and analyzing task utilizationSanchit AgrawalNo ratings yet
- Simulation BanksDocument28 pagesSimulation BanksJesus NoyolaNo ratings yet
- Sim ExamplesDocument11 pagesSim ExamplesAya HegazyNo ratings yet
- Scheduling Calculation: Graph Method: S. S. Ray, Associate Professor, NIFT, KolkataDocument5 pagesScheduling Calculation: Graph Method: S. S. Ray, Associate Professor, NIFT, KolkataSHIKHA SINGHNo ratings yet
- 4.discrete Event Simulation 2Document54 pages4.discrete Event Simulation 2AdiSatriaPangestuNo ratings yet
- Production Management Control I Line Balancing Bus 314Document7 pagesProduction Management Control I Line Balancing Bus 314faith olaNo ratings yet
- ENEL2CMH1 - Applied Computer MethodsDocument9 pagesENEL2CMH1 - Applied Computer MethodsqanaqNo ratings yet
- Or M3 Ktunotes - inDocument62 pagesOr M3 Ktunotes - inJaya sankarNo ratings yet
- Statistical Predictors of Computing Power in Heterogeneous ClustersDocument9 pagesStatistical Predictors of Computing Power in Heterogeneous ClusterstranthinhamNo ratings yet
- CS2106 Lab 6Document5 pagesCS2106 Lab 6weitsangNo ratings yet
- Quality Management SystemDocument5 pagesQuality Management SystemDharun BlazerNo ratings yet
- Introduction To Using Excel With Essentials Mathematics For Economic AnalysisDocument13 pagesIntroduction To Using Excel With Essentials Mathematics For Economic AnalysisQuji BichiaNo ratings yet
- Processing 2 Jobs Through M Machines: ExampleDocument2 pagesProcessing 2 Jobs Through M Machines: ExampleStani GuptaNo ratings yet
- Exam 2 Review AnswersDocument3 pagesExam 2 Review AnswersAbhishekChakladarNo ratings yet
- Real-Time Calculus Scheduling AlgorithmDocument4 pagesReal-Time Calculus Scheduling AlgorithmChrisLaiNo ratings yet
- Lab ManualDocument85 pagesLab ManualhotboangaNo ratings yet
- Assignment 1Document4 pagesAssignment 1Ashutosh SinghNo ratings yet
- CIM Unit 3.1Document96 pagesCIM Unit 3.1vrushNo ratings yet
- ch10 IsmDocument4 pagesch10 IsmTri Oka Putra0% (1)
- Dsa Assignment TheoryDocument2 pagesDsa Assignment TheoryAnanya AgarwalNo ratings yet
- An Analytical Formula For Throughput of A Production Line With Identical Stations and Random FailuresDocument16 pagesAn Analytical Formula For Throughput of A Production Line With Identical Stations and Random FailuresRonni SiahaanNo ratings yet
- Control System Engineering: Lab ManualDocument18 pagesControl System Engineering: Lab ManualUmair Afzal ShuklaNo ratings yet
- Simple and U-Type Assembly Line Balancing Problems With A Learning EffectDocument8 pagesSimple and U-Type Assembly Line Balancing Problems With A Learning Effectaizamudio23No ratings yet
- International Journal of Engineering Research and Development (IJERD)Document6 pagesInternational Journal of Engineering Research and Development (IJERD)IJERDNo ratings yet
- Comparison of AlgorithmsDocument20 pagesComparison of AlgorithmsSalif NdiayeNo ratings yet
- Binary Decision DiagramsDocument8 pagesBinary Decision DiagramsMohammed MorsyNo ratings yet
- Sequencing ModelDocument10 pagesSequencing ModelBisoyeNo ratings yet
- Lab 02: Cubic spline interpolation and blood flow modellingDocument7 pagesLab 02: Cubic spline interpolation and blood flow modellingkainNo ratings yet
- Real Time System Solutions ManualDocument75 pagesReal Time System Solutions Manualrktiwary256034No ratings yet
- Assignment 4Document9 pagesAssignment 4MH MerhiNo ratings yet
- Chapter 1Document3 pagesChapter 1Beth Barnett100% (1)
- Telemark University College Faculty of Technology: M.Sc. ProgrammeDocument41 pagesTelemark University College Faculty of Technology: M.Sc. ProgrammeSayed LezonNo ratings yet
- Operation SchedulingDocument28 pagesOperation SchedulingGagan BhatiNo ratings yet
- SF2863 Hwa1 KTHDocument4 pagesSF2863 Hwa1 KTHKirtan PatelNo ratings yet
- KTMT AssignmentsDocument3 pagesKTMT AssignmentsNguyên NguyễnNo ratings yet
- Hw6 SolutionDocument11 pagesHw6 SolutionHarishChoudharyNo ratings yet
- Introduction To Parallel Computing: Solution ManualDocument70 pagesIntroduction To Parallel Computing: Solution ManualAkashNo ratings yet
- 1 Incrementing in Worst Case O (1) Time.: N 0 I N 1 N 1 0Document2 pages1 Incrementing in Worst Case O (1) Time.: N 0 I N 1 N 1 0DongWoo OhNo ratings yet
- Reference 5REAL-TIME CALCULUS FOR SCHEDULING HARD REAL-TIME SYSTEMSDocument4 pagesReference 5REAL-TIME CALCULUS FOR SCHEDULING HARD REAL-TIME SYSTEMSaravind_1No ratings yet
- ENG3104 Assignment3Document8 pagesENG3104 Assignment3Nayim MohammadNo ratings yet
- Fundamentals of Statistical Signal Processing by DR Steven KayDocument25 pagesFundamentals of Statistical Signal Processing by DR Steven KayUtpal DasNo ratings yet
- Chapter 42Document85 pagesChapter 42Sam VNo ratings yet
- Rules of Thumb For Retail LayoutDocument12 pagesRules of Thumb For Retail LayoutArunav SahayNo ratings yet
- Parallel SortDocument7 pagesParallel SortzololuxyNo ratings yet
- WTFDocument6 pagesWTFDerek BowermanNo ratings yet
- Programming Pattern RecognitionDocument8 pagesProgramming Pattern RecognitionJ. Perry StonneNo ratings yet
- Half Wave Rectifier Circuit SimulationDocument33 pagesHalf Wave Rectifier Circuit SimulationHomoudAlsohaibi100% (2)
- The Optimum Pipeline Depth For A Microprocessor: A. Hartstein and Thomas R. PuzakDocument7 pagesThe Optimum Pipeline Depth For A Microprocessor: A. Hartstein and Thomas R. PuzakSiddharth SinghNo ratings yet
- Lab 06Document22 pagesLab 06Talha SaeedNo ratings yet
- Steps in Production Line BalancingDocument3 pagesSteps in Production Line BalancingWani Abrol0% (1)
- hw3 PDFDocument3 pageshw3 PDFKevin PaxsonNo ratings yet
- Problem Set Ee8205 PDFDocument4 pagesProblem Set Ee8205 PDFksajjNo ratings yet
- Promodel ManualDocument14 pagesPromodel ManualJorge S. CortezNo ratings yet
- Remote Projects Follow-up with Scrum-Excel Burn Down Chart: Scrum and Jira, #1From EverandRemote Projects Follow-up with Scrum-Excel Burn Down Chart: Scrum and Jira, #1No ratings yet
- ARA ProPresentationto CIC July 2008Document29 pagesARA ProPresentationto CIC July 2008Yeoh KhNo ratings yet
- Finite Element MethodDocument172 pagesFinite Element MethodYeoh KhNo ratings yet
- Yes 4g in MalaysiaDocument17 pagesYes 4g in MalaysiaYeoh KhNo ratings yet
- Pau Tanjung PresentationDocument19 pagesPau Tanjung PresentationYeoh KhNo ratings yet
- Yamazumi Process Modeling Tool AdaptiveBMS For ManufacturingDocument10 pagesYamazumi Process Modeling Tool AdaptiveBMS For ManufacturingYeoh KhNo ratings yet
- 2d Heat Conduction FemDocument8 pages2d Heat Conduction FemYeoh Kh100% (1)
- Heuristic Rules of ALBDocument1 pageHeuristic Rules of ALBYeoh KhNo ratings yet
- Ans I Thread SizesDocument3 pagesAns I Thread SizesPasinduNo ratings yet
- Fuzzy Logic IntroductionDocument9 pagesFuzzy Logic Introductionapi-3806146No ratings yet
- Brand and Product For CaeDocument4 pagesBrand and Product For CaeYeoh KhNo ratings yet
- Metric Screw Thread ChartDocument1 pageMetric Screw Thread ChartYeoh KhNo ratings yet
- TUTOR NAME LIST AND AVAILABILITYDocument1 pageTUTOR NAME LIST AND AVAILABILITYYeoh KhNo ratings yet
- Product Jack Floor Jack - RM140Document8 pagesProduct Jack Floor Jack - RM140Yeoh KhNo ratings yet
- Kettle Bicycle Fan LampDocument2 pagesKettle Bicycle Fan LampYeoh KhNo ratings yet
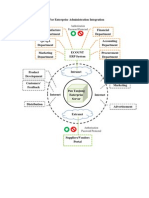
- Framework Proposed For Enterprise Administration IntegrationDocument1 pageFramework Proposed For Enterprise Administration IntegrationYeoh KhNo ratings yet
- Heuristic-Based Optimization Models For Assembly Line Balancing in Garment IndustryDocument15 pagesHeuristic-Based Optimization Models For Assembly Line Balancing in Garment IndustryYeoh KhNo ratings yet
- TUTOR NAME LIST AND AVAILABILITYDocument1 pageTUTOR NAME LIST AND AVAILABILITYYeoh KhNo ratings yet
- PG McaDocument35 pagesPG McaYeoh KhNo ratings yet
- Arena Template Developer's GuideDocument286 pagesArena Template Developer's Guidejhonny_otiNo ratings yet
- Control ChartsDocument2 pagesControl ChartsYeoh KhNo ratings yet
- LISA & GiD Impct ManualDocument203 pagesLISA & GiD Impct ManualYeoh KhNo ratings yet
- Envision Runtime AdministrationDocument488 pagesEnvision Runtime Administrationobsidian743No ratings yet
- p601 5 3Document433 pagesp601 5 3Mark CheneyNo ratings yet
- and Install Powerpivot For Excel: Microsoft Web SiteDocument8 pagesand Install Powerpivot For Excel: Microsoft Web Siteunicycle1234No ratings yet
- Excel Formulas and FunctionsDocument12 pagesExcel Formulas and FunctionsprasanjeetbNo ratings yet
- C28X Iqmath Library: A Virtual Floating Point Engine V1.5 July 8, 2008Document72 pagesC28X Iqmath Library: A Virtual Floating Point Engine V1.5 July 8, 2008Tesfaye Utopia UtopiaNo ratings yet
- Excel Practise WorkDocument49 pagesExcel Practise WorklodhisahbNo ratings yet
- PC 811 TroubleshootingGuideDocument654 pagesPC 811 TroubleshootingGuidesriec120% (1)
- ExcelFunctions - PracticeDocument107 pagesExcelFunctions - PracticeSəbuhiƏbülhəsənliNo ratings yet
- Workflow Tech Spec From DeloitteDocument27 pagesWorkflow Tech Spec From DeloitteSesirekha RavinuthulaNo ratings yet
- At The End of The Session You Will Have Adequate Knowledge To UnderstandDocument248 pagesAt The End of The Session You Will Have Adequate Knowledge To Understandrobel100% (1)
- 2022 Techwear GuideDocument42 pages2022 Techwear GuideCeline LowNo ratings yet
- Implementing Payroll Interface For ADP Global PayrollDocument75 pagesImplementing Payroll Interface For ADP Global PayrollAbhiram Jayaram100% (1)
- Advanced Excel FormulasDocument208 pagesAdvanced Excel Formulasballagabi100% (2)
- Search courses based on skills and management blogDocument14 pagesSearch courses based on skills and management blogduality bbwNo ratings yet
- Using IF, COUNT, and COUNTA FunctionsDocument19 pagesUsing IF, COUNT, and COUNTA FunctionsLala BubNo ratings yet
- Working With Flat FilesDocument24 pagesWorking With Flat FilesyprajuNo ratings yet
- Essential Spreadsheets ExercisesDocument23 pagesEssential Spreadsheets ExercisesBharath BkrNo ratings yet
- Assignment - ADocument10 pagesAssignment - AParth MundhadaNo ratings yet
- An Iterative Mitchell's Algorithm Based MultiplierDocument6 pagesAn Iterative Mitchell's Algorithm Based Multiplieraditya_me123No ratings yet
- Ab Initio TrainingDocument103 pagesAb Initio Trainingsuperstarraj63% (8)
- HaViMo2 Image Processing Module Optimized for Color and Grid DetectionDocument9 pagesHaViMo2 Image Processing Module Optimized for Color and Grid DetectionEnaliza AnuarNo ratings yet
- Lacls Fiscal Solution Path 15102021 Pix OracleDocument199 pagesLacls Fiscal Solution Path 15102021 Pix OracleLeandro Wandekoken CavalheiroNo ratings yet
- Excel Tables, Functions and Pivot TablesDocument12 pagesExcel Tables, Functions and Pivot TablesabdulbasitNo ratings yet
- A 30-b Integrated Logarithmic Number System Processor - 91Document8 pagesA 30-b Integrated Logarithmic Number System Processor - 91Phuc HoangNo ratings yet
- How JavaScript Objects Are ImplementedDocument50 pagesHow JavaScript Objects Are ImplementedSungkwan ParkNo ratings yet
- UNIT-3: 1. What Do You Mean by Cell in Ms-Excel?Document22 pagesUNIT-3: 1. What Do You Mean by Cell in Ms-Excel?Amisha SainiNo ratings yet
- Abinitio InterviewDocument70 pagesAbinitio InterviewChandni Kumari100% (5)
- Microsoft Excel Features PresentationDocument75 pagesMicrosoft Excel Features PresentationAlok JhaNo ratings yet
- FINMODDocument2 pagesFINMODEve Daughter of GodNo ratings yet
- Informatica Interview QnADocument345 pagesInformatica Interview QnASuresh DhinnepalliNo ratings yet