You might also like
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Martin Caidin - The God MachineDocument134 pagesMartin Caidin - The God MachineLogan BlackstoneNo ratings yet
- Background of The StudyDocument4 pagesBackground of The StudyAlex MapiliNo ratings yet
- Structural Design of Multi-Storeyed Building by U H VaryaniDocument5 pagesStructural Design of Multi-Storeyed Building by U H VaryanidineshNo ratings yet
- 19MT1201 MFE Session Problems 2019 - 20Document22 pages19MT1201 MFE Session Problems 2019 - 20sai tejaNo ratings yet
- Euler Elements of Algebra PDFDocument2 pagesEuler Elements of Algebra PDFDawn0% (1)
- Data Manipulation Language (DML)Document8 pagesData Manipulation Language (DML)asiflistenNo ratings yet
- Harmon Foods Sales ForecastingDocument4 pagesHarmon Foods Sales ForecastingkarthikawarrierNo ratings yet
- Most Important Questions of OnstructionsDocument9 pagesMost Important Questions of OnstructionsCybeRaviNo ratings yet
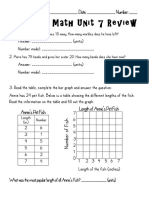
- Everyday Math Unit 7 ReviewDocument3 pagesEveryday Math Unit 7 ReviewReekhaNo ratings yet
- Mesh Repair Improves QualityDocument4 pagesMesh Repair Improves QualityusmanurrehmanNo ratings yet
- Module 1: Nature of StatisticsDocument47 pagesModule 1: Nature of StatisticsHannah Bea LindoNo ratings yet
- Electromagnetic Force Analysis of A Driving CoilDocument6 pagesElectromagnetic Force Analysis of A Driving CoilAngélica María CastrillónNo ratings yet
- Measures of Angles Formed Secants and TangentsDocument47 pagesMeasures of Angles Formed Secants and TangentsKhloe CeballosNo ratings yet
- Che 312 Notebook DistillationDocument19 pagesChe 312 Notebook DistillationUGWU MARYANNNo ratings yet
- Measuring and Modeling The Fatigue Performance of Elastomers For Applications With Complex Loading RequirementsDocument24 pagesMeasuring and Modeling The Fatigue Performance of Elastomers For Applications With Complex Loading RequirementssanthoshnlNo ratings yet
- Paperplainz Com Ib Math Aa SL Practice Exams Paper 1 Practice Exam 1Document5 pagesPaperplainz Com Ib Math Aa SL Practice Exams Paper 1 Practice Exam 1Aung Kyaw HtoonNo ratings yet
- Quality Assurance in The Clinical Chemistry Laboratory Quality ControlDocument8 pagesQuality Assurance in The Clinical Chemistry Laboratory Quality Controlさあ ああさNo ratings yet
- Números Cardinales y OrdinalesDocument5 pagesNúmeros Cardinales y OrdinalesHeffer Rueda EspinosaNo ratings yet
- Class B and AB Amplifiers GuideDocument22 pagesClass B and AB Amplifiers GuideKenneth AmenNo ratings yet
- Algorithmic Differentiation in Finance Explained-Henrard, Marc, Palgrave Macmillan (2017) PDFDocument112 pagesAlgorithmic Differentiation in Finance Explained-Henrard, Marc, Palgrave Macmillan (2017) PDFdata100% (3)
- Drawing Circles using Midpoint AlgorithmDocument2 pagesDrawing Circles using Midpoint AlgorithmMATTHEW JALOWE MACARANASNo ratings yet
- Iec Sit Sit Sepam CurveDocument1 pageIec Sit Sit Sepam Curveyadav_sctNo ratings yet
- GTU BE Semester III Circuits and Networks Exam QuestionsDocument3 pagesGTU BE Semester III Circuits and Networks Exam QuestionsPanktiNo ratings yet
- HSE Global Scholarship Competition 2022 Demonstration Competition Task in Mathematics 11 Grade Execution Time 180 Minutes Maximal Mark 100 PointsDocument1 pageHSE Global Scholarship Competition 2022 Demonstration Competition Task in Mathematics 11 Grade Execution Time 180 Minutes Maximal Mark 100 PointsRazan Muhammad ihsanNo ratings yet
- Di ElectricsDocument32 pagesDi Electricsamaresh_rNo ratings yet
- A0703020108 PDFDocument8 pagesA0703020108 PDFFares EL DeenNo ratings yet
- IC Training Matrix Template Sample 11623Document5 pagesIC Training Matrix Template Sample 11623Nithin MathaiNo ratings yet
- Digital Notes: (Department of Computer Applications)Document14 pagesDigital Notes: (Department of Computer Applications)Anuj PrajapatiNo ratings yet
- Masonry ManualDocument114 pagesMasonry Manualsiju1290% (10)
- LC Filter For Three Phase Inverter ReportDocument19 pagesLC Filter For Three Phase Inverter ReportMuthuRajNo ratings yet