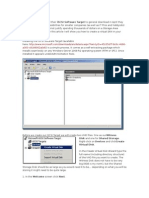
You might also like
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Catepilar ParameterDocument3 pagesCatepilar ParameterHAriantonoNo ratings yet
- Data Migration in Sap Using LSMW: (Batch Input Recording Method)Document61 pagesData Migration in Sap Using LSMW: (Batch Input Recording Method)fharooksNo ratings yet
- Pricing - Condition Base ValueDocument5 pagesPricing - Condition Base Valuemahesshbabum9231100% (1)
- Movement Types Determining The WM Movement Type During TO Creation PDFDocument5 pagesMovement Types Determining The WM Movement Type During TO Creation PDFShyamNo ratings yet
- SD GTS Integration: Community WIKI SAP CommunityDocument5 pagesSD GTS Integration: Community WIKI SAP CommunitySUDHIRNo ratings yet
- Internet Transaction Server (ITS) and ITSmobileDocument37 pagesInternet Transaction Server (ITS) and ITSmobileRohini GoudNo ratings yet
- Install and tune SAP ATP ServerDocument10 pagesInstall and tune SAP ATP ServerkoyalpNo ratings yet
- Sap ReferenceDocument88 pagesSap Referenceapi-3856831No ratings yet
- Cin Config DocumentationDocument40 pagesCin Config Documentationrama_mk_sapsdNo ratings yet
- Diagnostic Codes: Shutdown SISDocument3 pagesDiagnostic Codes: Shutdown SISNovakurniawanNo ratings yet
- Standard WorkflowDocument36 pagesStandard WorkflowSunilkumar BethinediNo ratings yet
- 3 Post Installation Tasks & Other PracticalsDocument33 pages3 Post Installation Tasks & Other PracticalsMukesh JuyalNo ratings yet
- Process For Setting Up The Work Tool: Testing and AdjustingDocument31 pagesProcess For Setting Up The Work Tool: Testing and AdjustingMbahdiro KolenxNo ratings yet
- DX210WA Hydraulic Schematic: Serial Number 5001 and UpDocument1 pageDX210WA Hydraulic Schematic: Serial Number 5001 and UpHaidar SareeniNo ratings yet
- Customer Ageing ReportDocument9 pagesCustomer Ageing Reportbikash das100% (1)
- Basic Service Purchase Order Process Withholding - Service Management - Localization Latin America - SCN WikiDocument10 pagesBasic Service Purchase Order Process Withholding - Service Management - Localization Latin America - SCN Wikivtheamth100% (1)
- Sap QuestionsDocument16 pagesSap QuestionskavinganNo ratings yet
- Interactive Schematic: This Document Is Best Viewed at A Screen Resolution of 1024 X 768Document10 pagesInteractive Schematic: This Document Is Best Viewed at A Screen Resolution of 1024 X 768Alfonso BarrantesNo ratings yet
- R140LC 9sDocument35 pagesR140LC 9sAimHighNo ratings yet
- slis_layout_alv documentations fieldsDocument8 pagesslis_layout_alv documentations fieldsClasesXXXNo ratings yet
- 2018 AFO SSA Fertilizer Plants Register-Min-Ilovep PDFDocument40 pages2018 AFO SSA Fertilizer Plants Register-Min-Ilovep PDFSiddhNo ratings yet
- 330l Elect 1Document2 pages330l Elect 1Nath JeffNo ratings yet
- Balluf Sensors User's GuideDocument26 pagesBalluf Sensors User's GuidecakendriNo ratings yet
- Material Determination: PurposeDocument8 pagesMaterial Determination: PurposeTravis SchmidtNo ratings yet
- FI S. No General Ledger T-Code S. NoDocument6 pagesFI S. No General Ledger T-Code S. NoTejendra SoniNo ratings yet
- Cat Electronic Technician 2014A v1.0 Product Status ReportDocument10 pagesCat Electronic Technician 2014A v1.0 Product Status ReportGeorge ZormpasNo ratings yet
- Status Report Fruytier 972K Pem00444 DPF A Plus de 140% Soot - PSRPT - 2021-07-28 - 09.36.43Document13 pagesStatus Report Fruytier 972K Pem00444 DPF A Plus de 140% Soot - PSRPT - 2021-07-28 - 09.36.43Jean DiscretNo ratings yet
- Extending Extending - SRM - Web - Dynpro - ViewSRM Web Dynpro ViewDocument19 pagesExtending Extending - SRM - Web - Dynpro - ViewSRM Web Dynpro Viewmostafaelbarbary100% (3)
- Pricing Configuration Guide With Used CasesDocument39 pagesPricing Configuration Guide With Used CasesGulliver Traveller100% (1)
- MigoDocument3 pagesMigoShesadri Nath100% (1)
- 1104 Troubleshooting PERKINS - PDF - Throttle - Fuel Injection PDFDocument1 page1104 Troubleshooting PERKINS - PDF - Throttle - Fuel Injection PDFHaider AlbatalNo ratings yet
- EA465 Generator Automatic Voltage Regulator Operation ManualDocument6 pagesEA465 Generator Automatic Voltage Regulator Operation Manualfahad pirzadaNo ratings yet
- Hitachi Unified Storage Command Line Interface Reference GuideDocument688 pagesHitachi Unified Storage Command Line Interface Reference Guidetedington2540No ratings yet
- RF Device: GUI DevicesDocument11 pagesRF Device: GUI Deviceschinmay patilNo ratings yet
- 980G Series II Electrical System Wheel Loader: Harness and Wire Electrical Schematic SymbolsDocument4 pages980G Series II Electrical System Wheel Loader: Harness and Wire Electrical Schematic SymbolsPlstina RamsNo ratings yet
- RLM ExcerciseDocument35 pagesRLM ExcerciseAnjaliNo ratings yet
- SAP task list tables searchDocument2 pagesSAP task list tables searchBoban Vasiljevic100% (1)
- TT216E-00 CircitDocument412 pagesTT216E-00 Circitthuan100% (1)
- Physical Inventory Process in SAP MMDocument11 pagesPhysical Inventory Process in SAP MMPrudhvikrishna GurramNo ratings yet
- FSCM Workshop - 02 - Manage and Collect Credits - V2Document3 pagesFSCM Workshop - 02 - Manage and Collect Credits - V2RajuNo ratings yet
- Smartforms XML FormatDocument35 pagesSmartforms XML FormatNurdin AchmadNo ratings yet
- Vistex UpgradeDocument1 pageVistex UpgradeRavinderPalSinghNo ratings yet
- SHD0 Screen Variant CreationDocument24 pagesSHD0 Screen Variant Creationsirurjp3271No ratings yet
- 232D/236D/242D/ 246D/262D: Skid Steer LoadersDocument20 pages232D/236D/242D/ 246D/262D: Skid Steer LoadersCapacitaciones RutasNo ratings yet
- SE91 transaction message class configurationDocument4 pagesSE91 transaction message class configurationmayoorNo ratings yet
- Diagrama 318-D2 PDFDocument16 pagesDiagrama 318-D2 PDFDaniel Rosales ReyesNo ratings yet
- Solenoid Valves: Systems OperationDocument6 pagesSolenoid Valves: Systems OperationMbahdiro KolenxNo ratings yet
- SAP MM Configuration Document V1Document28 pagesSAP MM Configuration Document V1ALBERTO CASTELLANONo ratings yet
- Debugging A Background JobDocument16 pagesDebugging A Background Jobdevu shivagondaNo ratings yet
- BAPI Functions for Goods Movement and Outbound DeliveryDocument14 pagesBAPI Functions for Goods Movement and Outbound DeliveryLeonardus Tedo SantosoNo ratings yet
- FS - TS - e - PD758 Mnemonic - PDDocument14 pagesFS - TS - e - PD758 Mnemonic - PDSrinivasan NarasimmanNo ratings yet
- Komtrax Remote Monitoring for Komatsu PC130F-7 Hydraulic ExcavatorDocument14 pagesKomtrax Remote Monitoring for Komatsu PC130F-7 Hydraulic ExcavatorAditya Wisnu Wardhana100% (2)
- SAP Coding Standards ERPAMSDocument19 pagesSAP Coding Standards ERPAMSNaresh VepuriNo ratings yet
- Engine Performance - Test - Engine Speed: 320D and 323D Excavators Hydraulic SystemDocument3 pagesEngine Performance - Test - Engine Speed: 320D and 323D Excavators Hydraulic SystemEm sulistio100% (1)
- Overview of XXP and Its SAP ImplementationDocument15 pagesOverview of XXP and Its SAP ImplementationJagannadh BirakayalaNo ratings yet
- ALL Problems and Solutions in SAPDocument5 pagesALL Problems and Solutions in SAPPILLINAGARAJUNo ratings yet
- Useful Troubleshooting TipsDocument81 pagesUseful Troubleshooting TipsPeter Naveen NaviNo ratings yet
- Abap DumpsDocument19 pagesAbap DumpsAbdul27No ratings yet
- 01 FirstDocument11 pages01 FirstSurut ShahNo ratings yet
- Manet AssignmentDocument5 pagesManet AssignmentHolly AndersonNo ratings yet
- Penetration Tester Resume SampleDocument3 pagesPenetration Tester Resume SampleogautierNo ratings yet
- Zenoss Extended MonitorDocument6 pagesZenoss Extended MonitorRuben KamermanNo ratings yet
- ISCSI Target 3.3Document5 pagesISCSI Target 3.3Zainuri MuhammadNo ratings yet
- Ultrastar Deluxe: (For Grown-Up Children Too and at Least Pedagogically Valuable)Document10 pagesUltrastar Deluxe: (For Grown-Up Children Too and at Least Pedagogically Valuable)Gerald GocoNo ratings yet
- Creo Brisque Improof Instalation and User GuideDocument78 pagesCreo Brisque Improof Instalation and User GuideaysdrecNo ratings yet
- 般若波羅蜜多心經注音(心經注音) at Time Waits for No One 痞客邦Document1 page般若波羅蜜多心經注音(心經注音) at Time Waits for No One 痞客邦有話直說No ratings yet
- 2 - The Current State of ICT TechnologiesDocument30 pages2 - The Current State of ICT TechnologiesErwin JudeNo ratings yet
- Google My Business HelpDocument1 pageGoogle My Business HelpReboot Computer ServicesNo ratings yet
- Chapter 1 MPLS OAM Configuration Commands ...................................................................... 1-1Document27 pagesChapter 1 MPLS OAM Configuration Commands ...................................................................... 1-1Randy DookheranNo ratings yet
- Unit-Iv: AspDocument16 pagesUnit-Iv: Aspmahesh9741No ratings yet
- Cellocator FleetsolutionsDocument6 pagesCellocator FleetsolutionsKarla Haydé Quintana EsparzaNo ratings yet
- Fort San Pedro National High School: CJ Name Name NameDocument20 pagesFort San Pedro National High School: CJ Name Name NameSiji PaclibarNo ratings yet
- Basics of Networking Paper 19BCASD23Document169 pagesBasics of Networking Paper 19BCASD23Adithya NaikNo ratings yet
- NetTime - Network Time Synchronization ToolDocument3 pagesNetTime - Network Time Synchronization Toolmateigeorgescu80No ratings yet
- Survival GuideDocument137 pagesSurvival GuideClawsfinger100% (2)
- Intellyk Inc. Acquires Staffing Business Unit of Quadrant 4 System CorporationDocument3 pagesIntellyk Inc. Acquires Staffing Business Unit of Quadrant 4 System CorporationPR.comNo ratings yet
- Computer Crime Homework 3 Protecting Personal DataDocument1 pageComputer Crime Homework 3 Protecting Personal DataSia DhimanNo ratings yet
- RF+BSS Engineer CVDocument4 pagesRF+BSS Engineer CVIjaz Hussain DarNo ratings yet
- Migrating to Apex One as a Service AssessmentDocument5 pagesMigrating to Apex One as a Service AssessmentArundevaraj MNo ratings yet
- Facebook Cracker Tool AnalysisDocument3 pagesFacebook Cracker Tool AnalysisMuhammad Raihan AzzamNo ratings yet
- PCSDocument11 pagesPCSSaurabhNo ratings yet
- Module 1 Tourism Planning Development Tourism Promotion Services NC II 1 1Document10 pagesModule 1 Tourism Planning Development Tourism Promotion Services NC II 1 1Axel HagosojosNo ratings yet
- Information Security Policy TemplateDocument2 pagesInformation Security Policy TemplategfbNo ratings yet
- Airtel Sales & Insurance ServicesDocument13 pagesAirtel Sales & Insurance ServicesSunil Kumar NagNo ratings yet
- O Impostor Que Vive em Mim - Brennan ManningDocument2 pagesO Impostor Que Vive em Mim - Brennan Manningsreginasoares9950100% (1)
- E1 Pri TroubleshootingDocument4 pagesE1 Pri TroubleshootingAlemseged HabtamuNo ratings yet
- Forensic Analysis of the Windows 7 RegistryDocument18 pagesForensic Analysis of the Windows 7 RegistryNeetish JayantNo ratings yet
- Linde Service GuideDocument5 pagesLinde Service GuideMário AndradeNo ratings yet
- Temp Mail - Disposable Temporary Email Title GeneratorDocument3 pagesTemp Mail - Disposable Temporary Email Title GeneratorasdewqNo ratings yet
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- What Algorithms Want: Imagination in the Age of ComputingFrom EverandWhat Algorithms Want: Imagination in the Age of ComputingRating: 3.5 out of 5 stars3.5/5 (41)
- Generative Art: A practical guide using ProcessingFrom EverandGenerative Art: A practical guide using ProcessingRating: 4 out of 5 stars4/5 (4)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Linux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepFrom EverandLinux: The Ultimate Beginner's Guide to Learn Linux Operating System, Command Line and Linux Programming Step by StepRating: 4.5 out of 5 stars4.5/5 (9)
- Software Engineering at Google: Lessons Learned from Programming Over TimeFrom EverandSoftware Engineering at Google: Lessons Learned from Programming Over TimeRating: 4 out of 5 stars4/5 (11)
- Introducing Python: Modern Computing in Simple Packages, 2nd EditionFrom EverandIntroducing Python: Modern Computing in Simple Packages, 2nd EditionRating: 4 out of 5 stars4/5 (7)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersFrom EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersRating: 5 out of 5 stars5/5 (7)
- CODING FOR ABSOLUTE BEGINNERS: How to Keep Your Data Safe from Hackers by Mastering the Basic Functions of Python, Java, and C++ (2022 Guide for Newbies)From EverandCODING FOR ABSOLUTE BEGINNERS: How to Keep Your Data Safe from Hackers by Mastering the Basic Functions of Python, Java, and C++ (2022 Guide for Newbies)No ratings yet
- GROKKING ALGORITHMS: Simple and Effective Methods to Grokking Deep Learning and Machine LearningFrom EverandGROKKING ALGORITHMS: Simple and Effective Methods to Grokking Deep Learning and Machine LearningNo ratings yet
- Tiny Python Projects: Learn coding and testing with puzzles and gamesFrom EverandTiny Python Projects: Learn coding and testing with puzzles and gamesRating: 5 out of 5 stars5/5 (2)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- Python Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsFrom EverandPython Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsRating: 3.5 out of 5 stars3.5/5 (54)
- Python for Data Analysis: A Beginners Guide to Master the Fundamentals of Data Science and Data Analysis by Using Pandas, Numpy and IpythonFrom EverandPython for Data Analysis: A Beginners Guide to Master the Fundamentals of Data Science and Data Analysis by Using Pandas, Numpy and IpythonNo ratings yet
- Python: For Beginners A Crash Course Guide To Learn Python in 1 WeekFrom EverandPython: For Beginners A Crash Course Guide To Learn Python in 1 WeekRating: 3.5 out of 5 stars3.5/5 (23)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet