You might also like
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghNo ratings yet
- Symmetric Multiprocessing and MicrokernelDocument6 pagesSymmetric Multiprocessing and MicrokernelManoraj PannerselumNo ratings yet
- Parallel Terminology 2Document7 pagesParallel Terminology 2maxsen021No ratings yet
- Multiprocessor Architecture SystemDocument10 pagesMultiprocessor Architecture SystemManmeet RajputNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- Parallel Programming: Homework Number 5 ObjectiveDocument6 pagesParallel Programming: Homework Number 5 ObjectiveJack BloodLetterNo ratings yet
- Module 5 (VVCE)Document53 pagesModule 5 (VVCE)BHAVANA M RNo ratings yet
- Multi-Core Processors: Page 1 of 25Document25 pagesMulti-Core Processors: Page 1 of 25nnNo ratings yet
- Chapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesDocument41 pagesChapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesraghvendrmNo ratings yet
- Large Computer Systems and Pipelining: HomeworkDocument11 pagesLarge Computer Systems and Pipelining: HomeworkRyan ReyesNo ratings yet
- Multi ProgrammingDocument6 pagesMulti ProgrammingAashish SharrmaNo ratings yet
- Thread Level ParallelismDocument21 pagesThread Level ParallelismKashif Mehmood Kashif MehmoodNo ratings yet
- Infiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceDocument7 pagesInfiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceMugabe DeogratiousNo ratings yet
- Concurrency: Blocking, Starvation, and "Fairness"Document4 pagesConcurrency: Blocking, Starvation, and "Fairness"Lal Mohd Iqram BegNo ratings yet
- Lec 4Document41 pagesLec 4Annie SikandarNo ratings yet
- Thread (Computing) : A Process With Two Threads of Execution, Running On One ProcessorDocument9 pagesThread (Computing) : A Process With Two Threads of Execution, Running On One ProcessorGautam TyagiNo ratings yet
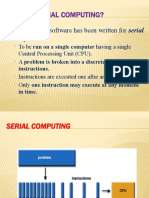
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Multicore ComputersDocument18 pagesMulticore ComputersMikias YimerNo ratings yet
- Lecture 10Document34 pagesLecture 10MAIMONA KHALIDNo ratings yet
- 2-Networks in Cloud ComputingDocument70 pages2-Networks in Cloud ComputingBishnu BashyalNo ratings yet
- Node Node Node Node: 1 Parallel Programming Models 5Document5 pagesNode Node Node Node: 1 Parallel Programming Models 5latinwolfNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- Potential Approaches To Parallel Computation of Rayleigh Integrals in Measuring Acoustic Pressure and IntensityDocument5 pagesPotential Approaches To Parallel Computation of Rayleigh Integrals in Measuring Acoustic Pressure and Intensityblhblh123No ratings yet
- What Is Parallel ComputingDocument9 pagesWhat Is Parallel ComputingLaura DavisNo ratings yet
- HPC NotesDocument24 pagesHPC NotesShadowOPNo ratings yet
- Unit 4 - Cloud Programming ModelsDocument21 pagesUnit 4 - Cloud Programming ModelsMag CreationNo ratings yet
- Cluster ComputingDocument5 pagesCluster Computingshaheen sayyad 463No ratings yet
- Global Semaphores in A Parallel Programming Environment P. Theodoropoulos, P° Tsanakas and G. PapakonstantinouDocument2 pagesGlobal Semaphores in A Parallel Programming Environment P. Theodoropoulos, P° Tsanakas and G. PapakonstantinouنورالدنياNo ratings yet
- Practical File: Parallel ComputingDocument34 pagesPractical File: Parallel ComputingGAMING WITH DEAD PANNo ratings yet
- Introduction To Parallel Computing: John Von Neumann Institute For ComputingDocument18 pagesIntroduction To Parallel Computing: John Von Neumann Institute For Computingsandeep_nagar29No ratings yet
- A Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)Document8 pagesA Review On Use of MPI in Parallel Algorithms: IPASJ International Journal of Computer Science (IIJCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Parallel Systems AssignmentDocument11 pagesParallel Systems AssignmentmahaNo ratings yet
- Solved Assignment - Parallel ProcessingDocument29 pagesSolved Assignment - Parallel ProcessingNoor Mohd Azad63% (8)
- Hardware MultithreadingDocument10 pagesHardware MultithreadingFarin KhanNo ratings yet
- PDS Assignment 01Document3 pagesPDS Assignment 01M Shahzaib AliNo ratings yet
- L38 TLPDocument13 pagesL38 TLPHari KalyanNo ratings yet
- Lecture Week - 2 General Parallelism TermsDocument24 pagesLecture Week - 2 General Parallelism TermsimhafeezniaziNo ratings yet
- Tutorial 4 Solution - OSDocument6 pagesTutorial 4 Solution - OSUnknown UnknownNo ratings yet
- Name:: Abdulhannan KhawajaDocument6 pagesName:: Abdulhannan KhawajaSAMAR BUTTNo ratings yet
- Seminar Report On Threads in DsDocument23 pagesSeminar Report On Threads in DsAnjan SarmaNo ratings yet
- 3.3-Recent Trends in Parallel ComputingDocument12 pages3.3-Recent Trends in Parallel ComputingChetan SolankiNo ratings yet
- Dca6105 - Computer ArchitectureDocument6 pagesDca6105 - Computer Architectureanshika mahajanNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Unit-1 OsDocument9 pagesUnit-1 Osbharathijawahar583No ratings yet
- Computer MultitaskingDocument5 pagesComputer MultitaskingWhitney NewtonNo ratings yet
- Operating System (3439)Document10 pagesOperating System (3439)Tooba Hassan 364-FSS/BSIAA/F19No ratings yet
- Debugging Real-Time Multiprocessor Systems: Class #264, Embedded Systems Conference, Silicon Valley 2006Document15 pagesDebugging Real-Time Multiprocessor Systems: Class #264, Embedded Systems Conference, Silicon Valley 2006lathavenkyNo ratings yet
- Parallel and Distributed SystemsDocument63 pagesParallel and Distributed SystemsSrinivas NaiduNo ratings yet
- Introduction To Parallel ProcessingDocument29 pagesIntroduction To Parallel ProcessingAzri Mohd KhanilNo ratings yet
- Ch:1 Introduction (12M) : Operating SystemDocument5 pagesCh:1 Introduction (12M) : Operating SystemSusham Jagdale SJNo ratings yet
- Multiprocessors: COMP 211 - Computer Systems Organization and ArchitectureDocument29 pagesMultiprocessors: COMP 211 - Computer Systems Organization and Architecture'Bryan Mendoza'No ratings yet
- Multicore Software Development Techniques: Applications, Tips, and TricksFrom EverandMulticore Software Development Techniques: Applications, Tips, and TricksRating: 2.5 out of 5 stars2.5/5 (2)
- Introduction to Reliable and Secure Distributed ProgrammingFrom EverandIntroduction to Reliable and Secure Distributed ProgrammingNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOperating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- New File ListDocument2 pagesNew File ListDIPAK VINAYAK SHIRBHATENo ratings yet
- Aahan's BirthdayDocument22 pagesAahan's BirthdayDIPAK VINAYAK SHIRBHATENo ratings yet
- Educational Multimedia On Hydraulics and PneumaticsDocument89 pagesEducational Multimedia On Hydraulics and PneumaticsDIPAK VINAYAK SHIRBHATENo ratings yet
- Dipak Vinayak Shirbhate VSRDIJCSIT 3479 Research Communication June 2014Document4 pagesDipak Vinayak Shirbhate VSRDIJCSIT 3479 Research Communication June 2014DIPAK VINAYAK SHIRBHATENo ratings yet
- Girls Hostel FormDocument1 pageGirls Hostel FormDIPAK VINAYAK SHIRBHATENo ratings yet
- Quality Circles For Vikramshila StudentsDocument22 pagesQuality Circles For Vikramshila StudentsDIPAK VINAYAK SHIRBHATENo ratings yet
- 2 Dipak Vinayak Shirbhate VSRDIJMCAPE 3631 Research Paper 4 8 August 2014Document8 pages2 Dipak Vinayak Shirbhate VSRDIJMCAPE 3631 Research Paper 4 8 August 2014DIPAK VINAYAK SHIRBHATENo ratings yet
- Prospectus For 14-15Document44 pagesProspectus For 14-15DIPAK VINAYAK SHIRBHATENo ratings yet
- Quality Circle A Case Study: Prof. D.V. Shirbhate Principal, Vikramshila Polytechnic DarapurDocument34 pagesQuality Circle A Case Study: Prof. D.V. Shirbhate Principal, Vikramshila Polytechnic DarapurDIPAK VINAYAK SHIRBHATENo ratings yet
- Domestic Water Heater PDFDocument39 pagesDomestic Water Heater PDFDIPAK VINAYAK SHIRBHATENo ratings yet
- Pramod Naik's Letter Director MsbteDocument1 pagePramod Naik's Letter Director MsbteDIPAK VINAYAK SHIRBHATENo ratings yet
- Salary Slip - May 2014Document5 pagesSalary Slip - May 2014DIPAK VINAYAK SHIRBHATENo ratings yet
- Boys Hostel FormDocument1 pageBoys Hostel FormDIPAK VINAYAK SHIRBHATE100% (1)
- Prospectus For 13-14Document42 pagesProspectus For 13-14DIPAK VINAYAK SHIRBHATENo ratings yet
- Classification of EnterprenuersDocument12 pagesClassification of EnterprenuersDIPAK VINAYAK SHIRBHATE100% (2)
- Creativity & The Business IdeaDocument12 pagesCreativity & The Business IdeaDIPAK VINAYAK SHIRBHATENo ratings yet
- Inplant TrainingDocument1 pageInplant TrainingDIPAK VINAYAK SHIRBHATENo ratings yet
- Prospectus Data 2013-14Document12 pagesProspectus Data 2013-14DIPAK VINAYAK SHIRBHATENo ratings yet
- Leave ApplicationDocument2 pagesLeave ApplicationDIPAK VINAYAK SHIRBHATE100% (2)
- Autocad 2009 Tips and Tricks DVSDocument24 pagesAutocad 2009 Tips and Tricks DVSDIPAK VINAYAK SHIRBHATENo ratings yet
- Proposal For New PolytechnicDocument7 pagesProposal For New PolytechnicDIPAK VINAYAK SHIRBHATENo ratings yet
- Importance of Diploma Education For Rural StudentsnnDocument55 pagesImportance of Diploma Education For Rural Studentsnnvspd2010No ratings yet
- Rule 3Document1 pageRule 3DIPAK VINAYAK SHIRBHATENo ratings yet
- Nss Allotment Request Letter ModifiedDocument2 pagesNss Allotment Request Letter ModifiedDIPAK VINAYAK SHIRBHATE75% (4)