You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Tripura 04092012Document48 pagesTripura 04092012ARTHARSHI GARGNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- AURTTA104 - Assessment 2 Practical Demonstration Tasks - V3Document16 pagesAURTTA104 - Assessment 2 Practical Demonstration Tasks - V3muhammaduzairNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Principal Examiner Feedback Summer 2016: Pearson Edexcel GCSE in Statistics (2ST01) Higher Paper 1HDocument14 pagesPrincipal Examiner Feedback Summer 2016: Pearson Edexcel GCSE in Statistics (2ST01) Higher Paper 1HHeavenly SinNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Concise Beam DemoDocument33 pagesConcise Beam DemoluciafmNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Konsep Negara Hukum Dalam Perspektif Hukum IslamDocument11 pagesKonsep Negara Hukum Dalam Perspektif Hukum IslamSiti MasitohNo ratings yet
- Detailed Lesson Plan (Lit)Document19 pagesDetailed Lesson Plan (Lit)Shan QueentalNo ratings yet
- English 2 Q3 Week 7 DLLDocument7 pagesEnglish 2 Q3 Week 7 DLLEste R A BulaonNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Feb-May SBI StatementDocument2 pagesFeb-May SBI StatementAshutosh PandeyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Inqlusive Newsrooms LGBTQIA Media Reference Guide English 2023 E1Document98 pagesInqlusive Newsrooms LGBTQIA Media Reference Guide English 2023 E1Disability Rights AllianceNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Introduction To Soft Floor CoveringsDocument13 pagesIntroduction To Soft Floor CoveringsJothi Vel Murugan83% (6)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- 1207 - RTC-8065 II InglesDocument224 pages1207 - RTC-8065 II InglesGUILHERME SANTOSNo ratings yet
- Revised PARA Element2 Radio LawsDocument81 pagesRevised PARA Element2 Radio LawsAurora Pelagio Vallejos100% (4)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Chapter 3: Verbal Communication SkillsDocument14 pagesChapter 3: Verbal Communication SkillsFares EL DeenNo ratings yet
- Read The Dialogue Below and Answer The Following QuestionDocument5 pagesRead The Dialogue Below and Answer The Following QuestionDavid GainesNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Decision Tree AlgorithmDocument22 pagesDecision Tree Algorithmvani_V_prakashNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Diffrent Types of MapDocument3 pagesDiffrent Types of MapIan GamitNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- SPWM Vs SVMDocument11 pagesSPWM Vs SVMpmbalajibtechNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Résumé Emily Martin FullDocument3 pagesRésumé Emily Martin FullEmily MartinNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- JOB Performer: Q .1: What Is Permit?Document5 pagesJOB Performer: Q .1: What Is Permit?Shahid BhattiNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Hospital Furniture: Project Profile-UpdatedDocument7 pagesHospital Furniture: Project Profile-UpdatedGaurav GuptaNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Lecture Notes - Introduction To Big DataDocument8 pagesLecture Notes - Introduction To Big Datasakshi kureley0% (1)
- Auditing Multiple Choice Questions and Answers MCQs Auditing MCQ For CA, CS and CMA Exams Principle of Auditing MCQsDocument30 pagesAuditing Multiple Choice Questions and Answers MCQs Auditing MCQ For CA, CS and CMA Exams Principle of Auditing MCQsmirjapur0% (1)
- Cot Observation ToolDocument14 pagesCot Observation ToolArnoldBaladjayNo ratings yet
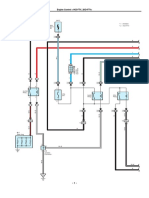
- Diagrama Hilux 1KD-2KD PDFDocument11 pagesDiagrama Hilux 1KD-2KD PDFJeni100% (1)
- Operation ManagementDocument4 pagesOperation ManagementHananiya GizawNo ratings yet
- Do I Need A 1PPS Box For My Mulitbeam SystemDocument3 pagesDo I Need A 1PPS Box For My Mulitbeam SystemutkuNo ratings yet
- Medha Servo Drives Written Exam Pattern Given by KV Sai KIshore (BVRIT-2005-09-ECE)Document2 pagesMedha Servo Drives Written Exam Pattern Given by KV Sai KIshore (BVRIT-2005-09-ECE)Varaprasad KanugulaNo ratings yet
- MT Im For 2002 3 PGC This Is A Lecture About Politics Governance and Citizenship This Will HelpDocument62 pagesMT Im For 2002 3 PGC This Is A Lecture About Politics Governance and Citizenship This Will HelpGen UriNo ratings yet
- New Cisco Certification Path (From Feb2020) PDFDocument1 pageNew Cisco Certification Path (From Feb2020) PDFkingNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Boq Cme: 1 Pole Foundation Soil WorkDocument1 pageBoq Cme: 1 Pole Foundation Soil WorkyuwonoNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)