You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Little Mongodb Schema BookDocument27 pagesLittle Mongodb Schema BookMasoom 'Meente' TulsianiNo ratings yet
- 1z0 047 Oracle Database SQL ExpertDocument270 pages1z0 047 Oracle Database SQL ExpertLigia PeţuNo ratings yet
- Relational Model-Merged-Pages-1-163,166-211,214-250,253-289,292-343,346-393,396-438Document426 pagesRelational Model-Merged-Pages-1-163,166-211,214-250,253-289,292-343,346-393,396-438abhijith100% (1)
- Data Modeling With DynamoDBDocument9 pagesData Modeling With DynamoDBJknoxvilNo ratings yet
- Mallikarjun Ramadurg Mallik034: Follow Me by Search Mallik034 at Youtube / FB / Linkedin / Twitter / Blogspot / InstagramDocument14 pagesMallikarjun Ramadurg Mallik034: Follow Me by Search Mallik034 at Youtube / FB / Linkedin / Twitter / Blogspot / Instagramvenkanna keesaraNo ratings yet
- Company Database - Questions - UpdatedDocument7 pagesCompany Database - Questions - UpdatedmathuNo ratings yet
- Proses DatabaseDocument17 pagesProses DatabaseTomUltrasNo ratings yet
- Oracle 9i CursorDocument1 pageOracle 9i CursorRidho WijayaNo ratings yet
- Connect C# To MySQL - CodeProjectDocument10 pagesConnect C# To MySQL - CodeProjectJoshua BrownNo ratings yet
- Teradata-Performance SQLDocument47 pagesTeradata-Performance SQLGowtham kannanNo ratings yet
- Find Any Action Inside The IDE: Ctrl+Shift+ADocument2 pagesFind Any Action Inside The IDE: Ctrl+Shift+AusaootestoousaNo ratings yet
- Csec It Sba 2022 Database ManagementDocument4 pagesCsec It Sba 2022 Database ManagementJanicSmithNo ratings yet
- Teste 5 8Document22 pagesTeste 5 8Veronica Perjeru100% (4)
- Globally Distributed, Secure MongoDB With Azure Cosmos DBDocument23 pagesGlobally Distributed, Secure MongoDB With Azure Cosmos DBspringleeNo ratings yet
- OLAP Cubes and BasicsDocument2 pagesOLAP Cubes and BasicsGHKomarNo ratings yet
- Using Subqueries in DB2 Using Subqueries in DB2Document15 pagesUsing Subqueries in DB2 Using Subqueries in DB2rajamain333No ratings yet
- Distributed Dbms Advanced ConceptsDocument70 pagesDistributed Dbms Advanced Conceptsstevenkanyanjua1No ratings yet
- SQLDocument4 pagesSQLAshok KumarNo ratings yet
- RDBMSDocument28 pagesRDBMSShravan ApteNo ratings yet
- IGNOU MCS-023 Solved Assignment 2016-17Document11 pagesIGNOU MCS-023 Solved Assignment 2016-17MaheshNo ratings yet
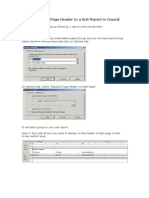
- How To Add A Page Header To A Sub Report in Crystal ReportsDocument4 pagesHow To Add A Page Header To A Sub Report in Crystal Reportsrajithp1985No ratings yet
- Coding Aplikasi Pemesanan Tiket PesawatDocument16 pagesCoding Aplikasi Pemesanan Tiket PesawatBagus NugrohoNo ratings yet
- PL SQL Interview Questions and AnswersDocument3 pagesPL SQL Interview Questions and AnswersatoztargetNo ratings yet
- KVS Sample Paper Xii CS 2021Document4 pagesKVS Sample Paper Xii CS 2021Pubg BoyNo ratings yet
- 11g PLSQLDocument742 pages11g PLSQLAbdullah ÇetinkayaNo ratings yet
- Create, Alter, Drop, Rename, Truncate: DDL Data Definition LanguageDocument4 pagesCreate, Alter, Drop, Rename, Truncate: DDL Data Definition LanguagePrabhakar PrabhuNo ratings yet
- Relational AlgebraDocument45 pagesRelational AlgebraNamanNo ratings yet
- VL2020210105055 Ast04 PDFDocument3 pagesVL2020210105055 Ast04 PDFManish RaoNo ratings yet
- DBMS C1P2Document42 pagesDBMS C1P2Amit SinghNo ratings yet
- Chapter 15: Concurrency Control: Database System Concepts, 6 EdDocument55 pagesChapter 15: Concurrency Control: Database System Concepts, 6 Edbhaskar_chintakindiNo ratings yet