You might also like
- Graphical Representation of Multivariate DataFrom EverandGraphical Representation of Multivariate DataPeter C. C. WangNo ratings yet
- Introduction to Stata - An Introduction to Data Manipulation and StatisticsDocument181 pagesIntroduction to Stata - An Introduction to Data Manipulation and StatisticsAmit Kumar SahooNo ratings yet
- An Introduction to MATLAB® Programming and Numerical Methods for EngineersFrom EverandAn Introduction to MATLAB® Programming and Numerical Methods for EngineersNo ratings yet
- Tutorial For StataDocument57 pagesTutorial For StatasuchitjackNo ratings yet
- Data Governance and Data Management: Contextualizing Data Governance Drivers, Technologies, and ToolsFrom EverandData Governance and Data Management: Contextualizing Data Governance Drivers, Technologies, and ToolsNo ratings yet
- UGC MODEL CURRICULUM STATISTICSDocument101 pagesUGC MODEL CURRICULUM STATISTICSAlok ThakkarNo ratings yet
- Stata Semiparametric Regression ModelsDocument109 pagesStata Semiparametric Regression ModelsJoab Dan Valdivia CoriaNo ratings yet
- Regression Graphics: Ideas for Studying Regressions Through GraphicsFrom EverandRegression Graphics: Ideas for Studying Regressions Through GraphicsNo ratings yet
- Here are the answers to the questions on Python revision:1. _type 2. >3. and 4. i5. ii6. ii 7. i8. i9. i10. No output is printed as the code is just assigning values to variablesDocument185 pagesHere are the answers to the questions on Python revision:1. _type 2. >3. and 4. i5. ii6. ii 7. i8. i9. i10. No output is printed as the code is just assigning values to variablesNaresh KumawatNo ratings yet
- Machine Learning Proceedings 1992: Proceedings of the Ninth International Workshop (ML92)From EverandMachine Learning Proceedings 1992: Proceedings of the Ninth International Workshop (ML92)No ratings yet
- Sampling Distribution and Simulation in RDocument10 pagesSampling Distribution and Simulation in RPremier PublishersNo ratings yet
- Arch Model and Time-Varying VolatilityDocument17 pagesArch Model and Time-Varying VolatilityJorge Vega RodríguezNo ratings yet
- UoW Engineering Module Assessment SolutionsDocument4 pagesUoW Engineering Module Assessment SolutionsSanchithya AriyawanshaNo ratings yet
- Gretl TutorialDocument35 pagesGretl TutorialBirat SharmaNo ratings yet
- DevStat8e - 01 - 02 03 04 and 4.6 FCDocument20 pagesDevStat8e - 01 - 02 03 04 and 4.6 FCchemicaly12No ratings yet
- Regression With StataDocument108 pagesRegression With Stataapi-373702575% (4)
- App.A - Detection and Estimation in Additive Gaussian Noise PDFDocument55 pagesApp.A - Detection and Estimation in Additive Gaussian Noise PDFLê Dương LongNo ratings yet
- Data Analysis With Stata: Creating A Working Dataset: Gumilang Aryo Sahadewo October 9, 2017 Mep Feb UgmDocument25 pagesData Analysis With Stata: Creating A Working Dataset: Gumilang Aryo Sahadewo October 9, 2017 Mep Feb UgmLeni MarlinaNo ratings yet
- RSTUDIODocument44 pagesRSTUDIOsamarth agarwalNo ratings yet
- Ma5160 Applied Probability and Statistics 1 PDFDocument4 pagesMa5160 Applied Probability and Statistics 1 PDFPrabhakar Prabhaa50% (2)
- Lecture+14 SAS Bootstrap and JackknifeDocument12 pagesLecture+14 SAS Bootstrap and JackknifeJoanne WongNo ratings yet
- An R Tutorial Starting OutDocument9 pagesAn R Tutorial Starting OutWendy WeiNo ratings yet
- R Short TutorialDocument5 pagesR Short TutorialPratiush TyagiNo ratings yet
- Regression Analysis Assignmentf2008Document3 pagesRegression Analysis Assignmentf2008Ghadeer MohammedNo ratings yet
- Stata - Tips PDFDocument114 pagesStata - Tips PDFglpi100% (1)
- Regression With StataDocument132 pagesRegression With StataOrtal RubinsteinNo ratings yet
- Quiz 6Document8 pagesQuiz 6Kristine Villaverde100% (1)
- Sample Question For Business StatisticsDocument12 pagesSample Question For Business StatisticsLinh ChiNo ratings yet
- Random ForestDocument83 pagesRandom ForestBharath Reddy MannemNo ratings yet
- Probability-Assignment 1Document4 pagesProbability-Assignment 1ibtihaj aliNo ratings yet
- Index Numbers (Maths)Document12 pagesIndex Numbers (Maths)Vijay AgrahariNo ratings yet
- Exercise ProbabilityDocument87 pagesExercise ProbabilityMalik Mohsin IshtiaqNo ratings yet
- Introduction To Data ScienceDocument8 pagesIntroduction To Data ScienceMajor ProjectNo ratings yet
- Time Series Project On Daily TemperaturesDocument12 pagesTime Series Project On Daily Temperaturestsiu45No ratings yet
- Ordinal and Multinomial ModelsDocument58 pagesOrdinal and Multinomial ModelsSuhel Ahmad100% (1)
- Stata TaskDocument3 pagesStata TaskSaad RajaNo ratings yet
- GSEMModellingusingStata PDFDocument97 pagesGSEMModellingusingStata PDFmarikum74No ratings yet
- 3.exponential Family & Point Estimation - 552Document33 pages3.exponential Family & Point Estimation - 552Alfian Syamsurizal0% (1)
- 1 Statistics PDFDocument40 pages1 Statistics PDFHue HueNo ratings yet
- Stata 4dummiesDocument12 pagesStata 4dummiesPablo CostillaNo ratings yet
- Measure of LocationsDocument6 pagesMeasure of LocationsSidra SiddiquiNo ratings yet
- Using R For Scientific Computing: Karline SoetaertDocument53 pagesUsing R For Scientific Computing: Karline SoetaertSafont Rodrigo CarlesNo ratings yet
- R Basics PDFDocument10 pagesR Basics PDFSAILY JADHAVNo ratings yet
- R Programming NotesDocument113 pagesR Programming Notesnalluri_08No ratings yet
- Compound Distributions and Mixture Distributions: ParametersDocument5 pagesCompound Distributions and Mixture Distributions: ParametersDennis ClasonNo ratings yet
- Discrete Mathematical StructuresDocument3 pagesDiscrete Mathematical StructuresJustice ReloadedNo ratings yet
- Learning RDocument15 pagesLearning RWilson RangelNo ratings yet
- Basic ProbDocument47 pagesBasic ProbAravind TaridaluNo ratings yet
- Python Programming 101 PDFDocument108 pagesPython Programming 101 PDFArt DollosaNo ratings yet
- Lab Report 1 PDFDocument6 pagesLab Report 1 PDFmr xyzNo ratings yet
- New Microsoft Word DocumentDocument163 pagesNew Microsoft Word DocumentPrahlad Reddy100% (1)
- Multiple Choice Questions For Discussion. Part 2Document20 pagesMultiple Choice Questions For Discussion. Part 2BassamSheryan50% (2)
- Principles of Data VisualizationDocument2 pagesPrinciples of Data VisualizationAAKASHNo ratings yet
- Extrapolation Methods for Extending Known Data PointsDocument3 pagesExtrapolation Methods for Extending Known Data PointsmakarandwathNo ratings yet
- Data Science with R: Programming Guide for Analyzing Casino Win/Loss DataDocument46 pagesData Science with R: Programming Guide for Analyzing Casino Win/Loss DataNimmi GuptaNo ratings yet
- Test of HypothesisDocument48 pagesTest of HypothesisSAEEDAWANNo ratings yet
- R Tutorial Covers Programming, Packages, Graphics & MoreDocument25 pagesR Tutorial Covers Programming, Packages, Graphics & MoreAsdssadf ScrvhstwNo ratings yet
- Semianalytical Productivity Models For Perforated CompletionsDocument10 pagesSemianalytical Productivity Models For Perforated CompletionsPhước LêNo ratings yet
- Two-stage Cluster Sampling Design and AnalysisDocument119 pagesTwo-stage Cluster Sampling Design and AnalysisZahra HassanNo ratings yet
- Production Optimization in An Oil Producing Asset - The BP Azeri Field Optimizer CaseDocument11 pagesProduction Optimization in An Oil Producing Asset - The BP Azeri Field Optimizer CaseLesly RiveraNo ratings yet
- En SeS ReportDesignerDocument87 pagesEn SeS ReportDesignermichelRamirezNo ratings yet
- Tutorial BiogemeDocument111 pagesTutorial BiogemeGlênia PinheiroNo ratings yet
- Astm 141Document6 pagesAstm 141CPA BTKNo ratings yet
- Measures of VariationDocument31 pagesMeasures of VariationMerjie A. NunezNo ratings yet
- "Examen Final 3er Corte - Planeación de Producción" 1Document6 pages"Examen Final 3er Corte - Planeación de Producción" 1Juan Camilo AlfonsoNo ratings yet
- Chan, Ramyar (2016) - Practical Challenges in Reserve RiskDocument36 pagesChan, Ramyar (2016) - Practical Challenges in Reserve RiskDamien ServaisNo ratings yet
- Process Analysis by Statistical Methods D. HimmelblauDocument474 pagesProcess Analysis by Statistical Methods D. HimmelblauSofia Mac Rodri100% (4)
- Mathed11: Advanced Statistics Module 1: Nonparametric Statistics Pretest/Exercise1/Activity 1Document6 pagesMathed11: Advanced Statistics Module 1: Nonparametric Statistics Pretest/Exercise1/Activity 1khylie briguelNo ratings yet
- FRM Test 09 AnsDocument25 pagesFRM Test 09 AnsKamal BhatiaNo ratings yet
- Profibus DP Pressure Transmitter User Manual - 20121112 PDFDocument42 pagesProfibus DP Pressure Transmitter User Manual - 20121112 PDFLuis CristóbalNo ratings yet
- AutotraderDocument50 pagesAutotraderVijay Vishwanath ThombareNo ratings yet
- Georglm: A Package For Generalised Linear Spatial Models Introductory SessionDocument10 pagesGeorglm: A Package For Generalised Linear Spatial Models Introductory SessionAlvaro Ernesto Garzon GarzonNo ratings yet
- LPP Sensitivity ReportDocument7 pagesLPP Sensitivity ReportVenkatesh mNo ratings yet
- Batch Mesh Solid Structural TutorialDocument34 pagesBatch Mesh Solid Structural TutorialPedro MaiaNo ratings yet
- A-1200 Methods Intro enDocument9 pagesA-1200 Methods Intro enMARICENo ratings yet
- Advanced Analytics PGDBDA Feb20Document13 pagesAdvanced Analytics PGDBDA Feb20Songs DrizzleNo ratings yet
- Smta-Gdl Smta-Gdl DFM Presentation 2012-07Document263 pagesSmta-Gdl Smta-Gdl DFM Presentation 2012-07tnchsgNo ratings yet
- Dampack AnalysisDocument45 pagesDampack Analysisratno widoyoNo ratings yet
- What Is Sampling?: PopulationDocument4 pagesWhat Is Sampling?: PopulationFarhaNo ratings yet
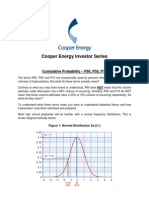
- Cumulative Probability P90 P50 P10 - 2Document7 pagesCumulative Probability P90 P50 P10 - 2Amir O. Osho100% (1)
- Backtest overfitting demonstration tool introduces online interface to illustrate impactDocument9 pagesBacktest overfitting demonstration tool introduces online interface to illustrate impactmikhaillevNo ratings yet
- Insulation Aging and Life Models: FP KSTDocument7 pagesInsulation Aging and Life Models: FP KSTajmaltkNo ratings yet
- BIM - SPESIFIKASI PARAMETER JKR (1) (001-033) .Ms - enDocument33 pagesBIM - SPESIFIKASI PARAMETER JKR (1) (001-033) .Ms - enPigmy LeeNo ratings yet
- Creating Revit Template - ChecklistDocument7 pagesCreating Revit Template - ChecklistmertNo ratings yet
- Bayesian Cost Effectiveness Analysis With The R Package BCEA PDFDocument181 pagesBayesian Cost Effectiveness Analysis With The R Package BCEA PDFNelson Carvas JrNo ratings yet
- Ascent Combat Framework DocumentationDocument70 pagesAscent Combat Framework Documentationfacy ben bookNo ratings yet
- Full Download Business Analytics 3rd Edition Camm Test BankDocument35 pagesFull Download Business Analytics 3rd Edition Camm Test Bankwyattcgkzc100% (33)