You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- 6 Noise and Multiple Attenuation PDFDocument164 pages6 Noise and Multiple Attenuation PDFFelipe CorrêaNo ratings yet
- Design of Predictive Magic Cards.Document26 pagesDesign of Predictive Magic Cards.aries25th3No ratings yet
- Grande PuntoDocument4 pagesGrande Puntocuick100% (1)
- Kirigami Pop UpsDocument9 pagesKirigami Pop UpsTamaraJovanovic100% (2)
- Mechanical Vibration NotesDocument56 pagesMechanical Vibration NotesYadanaNo ratings yet
- Arduino GuideDocument39 pagesArduino GuidecuickNo ratings yet
- SGM 3-2020 PDFDocument16 pagesSGM 3-2020 PDFcuickNo ratings yet
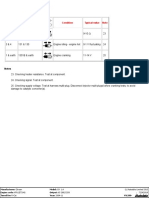
- Heated Oxygen Sensor (HO2S) 1: Terminals Wire Colour/number Condition Typical Value NoteDocument1 pageHeated Oxygen Sensor (HO2S) 1: Terminals Wire Colour/number Condition Typical Value NotecuickNo ratings yet
- SilverCrest SAB 160 B2 ManualDocument1 pageSilverCrest SAB 160 B2 ManualcuickNo ratings yet
- Transparenta Septembrie 2021Document212 pagesTransparenta Septembrie 2021cuickNo ratings yet
- Cikuit: Asynchronous DesignDocument14 pagesCikuit: Asynchronous DesigncuickNo ratings yet
- Inter ViuDocument33 pagesInter ViucuickNo ratings yet
- Scanned With CamscannerDocument6 pagesScanned With CamscannercuickNo ratings yet
- WHO 2019 nCoV Clinical 2020.4 EngDocument21 pagesWHO 2019 nCoV Clinical 2020.4 EngPouronik KarmakerNo ratings yet
- SGM 3-2020Document16 pagesSGM 3-2020cuickNo ratings yet
- Inter ViuDocument33 pagesInter ViucuickNo ratings yet
- GM 11-2019-Ex REZDocument10 pagesGM 11-2019-Ex REZcuickNo ratings yet
- Formula 10Document11 pagesFormula 10cuickNo ratings yet
- GM 11 2019Document6 pagesGM 11 2019cuickNo ratings yet
- GM 2 2019-1Document7 pagesGM 2 2019-1cuickNo ratings yet
- c4 Test 2Document4 pagesc4 Test 2cuickNo ratings yet
- Fundamentals of Neural Network Image RestorationDocument15 pagesFundamentals of Neural Network Image RestorationcuickNo ratings yet
- Image Processing Series: Published TitlesDocument9 pagesImage Processing Series: Published TitlescuickNo ratings yet
- 5.1.1 Weight-Parameterized Model-Based Neuron: N P M P NDocument33 pages5.1.1 Weight-Parameterized Model-Based Neuron: N P M P NcuickNo ratings yet
- 1.1 The Importance of Vision: 2002 CRC Press LLCDocument18 pages1.1 The Importance of Vision: 2002 CRC Press LLCcuickNo ratings yet
- 7.1 Modeling Timing: Timed CircuitsDocument18 pages7.1 Modeling Timing: Timed CircuitscuickNo ratings yet
- 8.2 MBNN Model For Edge Characterization: 8.2.1 Input-Parameterized Model-Based NeuronDocument15 pages8.2 MBNN Model For Edge Characterization: 8.2.1 Input-Parameterized Model-Based NeuroncuickNo ratings yet
- ChangeshjhjkhjkDocument5 pagesChangeshjhjkhjkChilmy FarouqNo ratings yet
- 161 09595 0 Irf540nDocument10 pages161 09595 0 Irf540nindianhitsNo ratings yet
- Irf640n PDFDocument12 pagesIrf640n PDFLeonel Antonio100% (1)
- Rezultate Clasa A Vi-A: NR - Crt. ID Nume Prenume Clasa Scoala Prof Coordonatori Of. Joc Of. Total Premiu Rezultat Data PalDocument5 pagesRezultate Clasa A Vi-A: NR - Crt. ID Nume Prenume Clasa Scoala Prof Coordonatori Of. Joc Of. Total Premiu Rezultat Data PalcuickNo ratings yet
- NR - CRT ID Nume Prenume Clasa Profesor Indrumator Binar Oficiu Numere Oficiu Total Premiu Rezultat Scoala de Provenie NtaDocument9 pagesNR - CRT ID Nume Prenume Clasa Profesor Indrumator Binar Oficiu Numere Oficiu Total Premiu Rezultat Scoala de Provenie NtacuickNo ratings yet
- ACEA Oil SequencesDocument14 pagesACEA Oil Sequencesctiiin100% (1)
- On The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsDocument11 pagesOn The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsMojeime Igor NowakNo ratings yet
- The Fast Continuous Wavelet Transformation (FCWT) For Real-Time, High-Quality, Noise-Resistant Time-Frequency AnalysisDocument17 pagesThe Fast Continuous Wavelet Transformation (FCWT) For Real-Time, High-Quality, Noise-Resistant Time-Frequency AnalysisHARRYNo ratings yet
- 0606 MW Otg MS P11Document8 pages0606 MW Otg MS P11Yu Yan ChanNo ratings yet
- Assignment 1 - Simple Harmonic MotionDocument2 pagesAssignment 1 - Simple Harmonic MotionDr. Pradeep Kumar SharmaNo ratings yet
- Governor System (Electrical Part)Document142 pagesGovernor System (Electrical Part)የፐፐፐ ነገርNo ratings yet
- The 3-Rainbow Index of GraphsDocument28 pagesThe 3-Rainbow Index of GraphsDinda KartikaNo ratings yet
- Solid State PhysicsDocument281 pagesSolid State PhysicsChang Jae LeeNo ratings yet
- Stratified Random Sampling PrecisionDocument10 pagesStratified Random Sampling PrecisionEPAH SIRENGONo ratings yet
- National University of Engineering Statistics Qualified PracticeDocument6 pagesNational University of Engineering Statistics Qualified PracticeAlvaro Gabriel Culqui MontoyaNo ratings yet
- Divergence and CurlDocument8 pagesDivergence and CurlaliNo ratings yet
- Ejercicos Mentales Volumen 13Document10 pagesEjercicos Mentales Volumen 13Luis TorresNo ratings yet
- Math 9Document8 pagesMath 9Erich GallardoNo ratings yet
- Brent Kung AdderDocument60 pagesBrent Kung AdderAnonymous gLVMeN2hNo ratings yet
- Subsea Control Systems SXGSSC PDFDocument6 pagesSubsea Control Systems SXGSSC PDFLimuel EspirituNo ratings yet
- Full Download Ebook Ebook PDF Mathematics in Action Algebraic Graphical and Trigonometric Problem Solving 5th Edition PDFDocument42 pagesFull Download Ebook Ebook PDF Mathematics in Action Algebraic Graphical and Trigonometric Problem Solving 5th Edition PDFwillie.ortiz343100% (41)
- Solving Problems by Searching: Artificial IntelligenceDocument43 pagesSolving Problems by Searching: Artificial IntelligenceDai TrongNo ratings yet
- Métodos de Fı́sica Teórica II - CF367 Lista de Exercı́cios I Dirac delta function propertiesDocument1 pageMétodos de Fı́sica Teórica II - CF367 Lista de Exercı́cios I Dirac delta function propertiesFernando Bazílio de LimaNo ratings yet
- Rangka Batang RhezaDocument11 pagesRangka Batang RhezaKABINET JALADARA NABDANo ratings yet
- Mathematics HL Paper 2 TZ2 PDFDocument16 pagesMathematics HL Paper 2 TZ2 PDFMADANNo ratings yet
- Sajc 2010 Prelim Math p2Document6 pagesSajc 2010 Prelim Math p2lauyongyiNo ratings yet
- IIR FILTER COEFFICIENTSDocument2 pagesIIR FILTER COEFFICIENTSharun or rashidNo ratings yet
- Javascript - Domain Fundamentals AssignmentsDocument43 pagesJavascript - Domain Fundamentals AssignmentsSana Fathima SanaNo ratings yet
- Water Refilling Station FeasibDocument10 pagesWater Refilling Station FeasibOman OpredoNo ratings yet
- Review Questions For COMALGEDocument9 pagesReview Questions For COMALGEKaye BaguilodNo ratings yet
- For Every Linear Programming Problem Whether Maximization or Minimization Has Associated With It Another Mirror Image Problem Based On Same DataDocument21 pagesFor Every Linear Programming Problem Whether Maximization or Minimization Has Associated With It Another Mirror Image Problem Based On Same DataAffu ShaikNo ratings yet
- BMS Sem 1 DSC Ge Sec Vac (Edit)Document27 pagesBMS Sem 1 DSC Ge Sec Vac (Edit)VISHESH 0009No ratings yet