You might also like
- Lesson 23: Tests of Hypotheses - Small SamplesDocument5 pagesLesson 23: Tests of Hypotheses - Small SamplesWinny Shiru MachiraNo ratings yet
- A Confidence Interval Provides Additional Information About VariabilityDocument14 pagesA Confidence Interval Provides Additional Information About VariabilityShrey BudhirajaNo ratings yet
- Unit IvDocument25 pagesUnit Iv05Bala SaatvikNo ratings yet
- Review of StatisticsDocument36 pagesReview of StatisticsJessica AngelinaNo ratings yet
- Confidence Interval EstimationDocument62 pagesConfidence Interval EstimationVikrant LadNo ratings yet
- 05 Statistical Inference-2 PDFDocument14 pages05 Statistical Inference-2 PDFRama DulceNo ratings yet
- Statistical Analysis Data Treatment and EvaluationDocument55 pagesStatistical Analysis Data Treatment and EvaluationJyl CodeñieraNo ratings yet
- Hypothesis TestingDocument44 pagesHypothesis Testinganpyaa100% (1)
- T-Distributions Chapter 6Document15 pagesT-Distributions Chapter 6Bubulina grecaNo ratings yet
- Costructs T Distribution (Dianne)Document9 pagesCostructs T Distribution (Dianne)Dianne RuizNo ratings yet
- The t Distribution for Small Sample StatisticsDocument25 pagesThe t Distribution for Small Sample StatisticsJamhur StNo ratings yet
- The Parametic Test of Significance Test T - DistributionDocument43 pagesThe Parametic Test of Significance Test T - Distributionhaboc.kristine.eccinfotechNo ratings yet
- "Business Statistics For Managers" Unit 5Document34 pages"Business Statistics For Managers" Unit 5Suragiri VarshiniNo ratings yet
- Hypothesis Testing of Education Majors' GPAsDocument48 pagesHypothesis Testing of Education Majors' GPAsKen SisonNo ratings yet
- Understanding the t-Test in 38 CharactersDocument5 pagesUnderstanding the t-Test in 38 CharactersMeenalochini kannanNo ratings yet
- Statistc in ChemistryDocument13 pagesStatistc in Chemistrycinvehbi711No ratings yet
- Unit VDocument22 pagesUnit Vazly vanNo ratings yet
- Statistical Power Analysis: Density (Number/hectare) of P. Leucopus Present AbsentDocument7 pagesStatistical Power Analysis: Density (Number/hectare) of P. Leucopus Present Absentajax_telamonioNo ratings yet
- Statistical Inference FrequentistDocument25 pagesStatistical Inference FrequentistAnkita GhoshNo ratings yet
- 1 Estimation PDFDocument31 pages1 Estimation PDFDylan D'silvaNo ratings yet
- Chapter 8 and 9Document7 pagesChapter 8 and 9Ellii YouTube channelNo ratings yet
- Estimation of Population MeanDocument14 pagesEstimation of Population MeanAmartyaNo ratings yet
- Sampling Theory 2Document7 pagesSampling Theory 2naveen.mathsNo ratings yet
- Estimating Population Values PPT at BEC DOMSDocument50 pagesEstimating Population Values PPT at BEC DOMSBabasab Patil (Karrisatte)No ratings yet
- Chapter 4 Hypothesis TestingDocument40 pagesChapter 4 Hypothesis Testingmusiccharacter07No ratings yet
- Nonlife Actuarial Models: Model Estimation and Types of DataDocument35 pagesNonlife Actuarial Models: Model Estimation and Types of Datavoikien01No ratings yet
- Hypothesis TestingDocument23 pagesHypothesis TestingNidhiNo ratings yet
- Introduction of Testing of Hypothesis NotesDocument4 pagesIntroduction of Testing of Hypothesis NotesThammana Nishithareddy100% (1)
- Introduction To Hypothesis Testing: Print RoundDocument2 pagesIntroduction To Hypothesis Testing: Print RoundShubhashish PaulNo ratings yet
- Hypothesis HandoutsDocument17 pagesHypothesis HandoutsReyson PlasabasNo ratings yet
- Sampling Theory and Hypothesis TestingDocument21 pagesSampling Theory and Hypothesis TestingMahendranath RamakrishnanNo ratings yet
- Statistics Exercises - Solutions: Covariance, correlation, the t-testDocument2 pagesStatistics Exercises - Solutions: Covariance, correlation, the t-testMichel EbambaNo ratings yet
- BADM 572 - Stats Homework Answers 6Document7 pagesBADM 572 - Stats Homework Answers 6nicktimmonsNo ratings yet
- Hypothesis Testing: One-Sample Tests ExplainedDocument21 pagesHypothesis Testing: One-Sample Tests ExplainedHIMANSHU ATALNo ratings yet
- Sampling QBDocument24 pagesSampling QBSHREYAS TR0% (1)
- Testing of Hypothesis For Large SampleDocument11 pagesTesting of Hypothesis For Large Sample52 Shagun ChaudhariNo ratings yet
- T DistibutionDocument25 pagesT DistibutionFritz AstilloNo ratings yet
- Calculating Percentiles and T-values from the T-DistributionDocument35 pagesCalculating Percentiles and T-values from the T-DistributionRhea Rose AlmoguezNo ratings yet
- Testing Hypotheses: R. 3. 1. (Introduction)Document16 pagesTesting Hypotheses: R. 3. 1. (Introduction)Moha ShifNo ratings yet
- Hypothesis Testing: One Sample CasesDocument35 pagesHypothesis Testing: One Sample Casesdivya aryaNo ratings yet
- Chapter 8 - Confidence Intervals- Lecture NotesDocument12 pagesChapter 8 - Confidence Intervals- Lecture NoteskikinasawayaNo ratings yet
- Chapter 11Document24 pagesChapter 11nickcupoloNo ratings yet
- 10 Inferential StatisticsDocument39 pages10 Inferential StatisticsShams QureshiNo ratings yet
- Confidence Interval EstimationDocument32 pagesConfidence Interval EstimationmiloniysanghrajkaNo ratings yet
- Hypothesis Testing Lecture NotesDocument15 pagesHypothesis Testing Lecture NotesEdmond ZNo ratings yet
- Solved Examples of Cramer Rao Lower BoundDocument6 pagesSolved Examples of Cramer Rao Lower BoundIk RamNo ratings yet
- Basics of Hypothesis Testing: A Concise ReviewDocument4 pagesBasics of Hypothesis Testing: A Concise Reviewpawanshrestha1No ratings yet
- Chapters 10,11,12Document6 pagesChapters 10,11,12sarkarigamingytNo ratings yet
- Forms of Test StatisticsDocument16 pagesForms of Test StatisticsRayezeus Jaiden Del RosarioNo ratings yet
- toh solvedDocument37 pagestoh solvedpragatiindia0913No ratings yet
- How To Find Percentiles For A T-Distribution: Statistics For Dummies, 2nd EditionDocument5 pagesHow To Find Percentiles For A T-Distribution: Statistics For Dummies, 2nd EditionNielyn WPNo ratings yet
- Business Statistics and Management Science NotesDocument74 pagesBusiness Statistics and Management Science Notes0pointsNo ratings yet
- Physical Chemistry IIDocument11 pagesPhysical Chemistry IIMichelle ChicaizaNo ratings yet
- An Introduction To T-Tests: Statistical Test Means Hypothesis TestingDocument8 pagesAn Introduction To T-Tests: Statistical Test Means Hypothesis Testingshivani100% (1)
- Unit IVDocument58 pagesUnit IVSUDIPTA DAS DCENo ratings yet
- Schaum's Easy Outline of Probability and Statistics, Revised EditionFrom EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionNo ratings yet
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimNo ratings yet
- R Codes Germinate Seed Data AnalysisDocument1 pageR Codes Germinate Seed Data AnalysisTeflon SlimNo ratings yet
- Results FileDocument159 pagesResults FileTeflon SlimNo ratings yet
- Combined Diallel-W DataDocument703 pagesCombined Diallel-W DataTeflon SlimNo ratings yet
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimNo ratings yet
- Additive NonadditiveDocument1 pageAdditive NonadditiveTeflon SlimNo ratings yet
- Ideal Tester STR-BA1057Document7 pagesIdeal Tester STR-BA1057Teflon SlimNo ratings yet
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimNo ratings yet
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimNo ratings yet
- Hybrid Maize Yield and Trait DataDocument46 pagesHybrid Maize Yield and Trait DataTeflon SlimNo ratings yet
- Combining Ability of Extra-Early White Inbreds Final DraftDocument57 pagesCombining Ability of Extra-Early White Inbreds Final DraftTeflon SlimNo ratings yet
- GGE Biplot of GCA Stability AnalysisDocument24 pagesGGE Biplot of GCA Stability AnalysisTeflon SlimNo ratings yet
- SCA Effects of Grain Yield in Maize HybridsDocument1 pageSCA Effects of Grain Yield in Maize HybridsTeflon SlimNo ratings yet
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimNo ratings yet
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimNo ratings yet
- Table 2Document1 pageTable 2Teflon SlimNo ratings yet
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimNo ratings yet
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimNo ratings yet
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimNo ratings yet
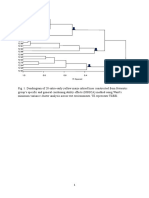
- Dendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodDocument1 pageDendrogram of 20 extra-early yellow maize inbred lines constructed from HSGCA methodTeflon SlimNo ratings yet
- Figure 1Document1 pageFigure 1Teflon SlimNo ratings yet
- Figure 5Document1 pageFigure 5Teflon SlimNo ratings yet
- Practical Session - Sample DataDocument21 pagesPractical Session - Sample DataTeflon SlimNo ratings yet
- Figure 4Document1 pageFigure 4Teflon SlimNo ratings yet
- Ba0727ik DataDocument12 pagesBa0727ik DataTeflon SlimNo ratings yet
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimNo ratings yet
- Figure 2Document1 pageFigure 2Teflon SlimNo ratings yet
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimNo ratings yet
- Data Analysis - Practical SessionDocument12 pagesData Analysis - Practical SessionTeflon SlimNo ratings yet
- Mathews Paul G. Design of Experiments With MINITAB PDFDocument521 pagesMathews Paul G. Design of Experiments With MINITAB PDFFernando Chavarria100% (2)
- Following Are The Measurement Values in Control Phase of The ProjectDocument9 pagesFollowing Are The Measurement Values in Control Phase of The ProjectSai Rama VizagNo ratings yet
- Duan and Bu 2017, Randomised Trial Investigating of A Single-Session Character-Strength-Based Cognitive Intervention On Freshman's AdaptabilityDocument11 pagesDuan and Bu 2017, Randomised Trial Investigating of A Single-Session Character-Strength-Based Cognitive Intervention On Freshman's AdaptabilityDiana ChenNo ratings yet
- Risk Management Practices of Conventional and Islamic Banks in BahrainDocument25 pagesRisk Management Practices of Conventional and Islamic Banks in Bahrainsajid bhattiNo ratings yet
- Probability Analitics For BusinessDocument57 pagesProbability Analitics For Businessvananova48No ratings yet
- Prepare for Probability and Statistics ExamDocument16 pagesPrepare for Probability and Statistics ExammariancantalNo ratings yet
- QAM - II Problem Set - 1 AnalysisDocument7 pagesQAM - II Problem Set - 1 AnalysisKartikey PandeyNo ratings yet
- Case Study - Risk & ReturnDocument6 pagesCase Study - Risk & ReturnSomyaNo ratings yet
- Random Variable N N Mean or Expected Value: Number of Ducks Type of Duck AmountDocument2 pagesRandom Variable N N Mean or Expected Value: Number of Ducks Type of Duck AmountAngie PastorNo ratings yet
- Thickness of Nonwoven Fabrics: Standard Test Method ForDocument4 pagesThickness of Nonwoven Fabrics: Standard Test Method ForJuanNo ratings yet
- Project Risk and Cost AnalysisDocument227 pagesProject Risk and Cost AnalysisRavi ValakrishnanNo ratings yet
- Regras Journal of Dairy ScienceDocument13 pagesRegras Journal of Dairy ScienceLuciana Paim PienizNo ratings yet
- ISOM 2700: Operations Management: Session 5. Quality Management II Acceptance Sampling & Six-SigmaDocument31 pagesISOM 2700: Operations Management: Session 5. Quality Management II Acceptance Sampling & Six-Sigmabwing yoNo ratings yet
- Sample OPMDocument110 pagesSample OPMnaveenNo ratings yet
- Reliability Based Design of Pile Raft FoundationDocument18 pagesReliability Based Design of Pile Raft FoundationSana UllahNo ratings yet
- Bivens Et Al. - 2007 - The Effectiveness of Equine-Assisted Experiential Therapy Results of An Open Clinical TrialDocument13 pagesBivens Et Al. - 2007 - The Effectiveness of Equine-Assisted Experiential Therapy Results of An Open Clinical Trialvulca0No ratings yet
- SMW FinalDocument13 pagesSMW FinalwaheedasabahatNo ratings yet
- Effects of Four Different Velocity-Based Training Programming Models On Strength Gains and Physical Performance.Document8 pagesEffects of Four Different Velocity-Based Training Programming Models On Strength Gains and Physical Performance.PabloAñonNo ratings yet
- ChitosanDocument8 pagesChitosanmaria dulceNo ratings yet
- Stat - Utility Posttest Day3Document6 pagesStat - Utility Posttest Day3Arei DomingoNo ratings yet
- Lab 430 1Document12 pagesLab 430 1LALANo ratings yet
- Ria LeptinDocument37 pagesRia Leptin1alfredo12100% (1)
- Chapter One Introduction To Business StatisticsDocument29 pagesChapter One Introduction To Business Statisticsአንተነህ የእናቱNo ratings yet
- Mindtree Company PROJECTDocument16 pagesMindtree Company PROJECTSanjay KuriyaNo ratings yet
- Traffic Engineering StudiesDocument45 pagesTraffic Engineering StudiesAbdulselam AbdurahmanNo ratings yet
- Generating Normally Distributed Random Numbers in ExcelDocument8 pagesGenerating Normally Distributed Random Numbers in Excelmuliawan_firdaus100% (1)
- Determinants of Ethiopian Bank ProfitabilityDocument16 pagesDeterminants of Ethiopian Bank Profitabilityberhanu geleboNo ratings yet
- Triathlon Bikes in The Age of Peak Aero - A ReportDocument19 pagesTriathlon Bikes in The Age of Peak Aero - A ReportKiley Austin-YoungNo ratings yet
- Ashraf Osmajurnaln Page 11 KoordinasiDocument54 pagesAshraf Osmajurnaln Page 11 KoordinasiCharles HolcombNo ratings yet
- The Unscrambler Method ReferencesDocument44 pagesThe Unscrambler Method ReferencesAlejandro RosalesNo ratings yet
- Stat 240 Quiz 3 KEY Answers Underlined and in Bold Questions 1-3 The Distribution of Systolic Blood Pressures Within A Certain Age Group Looks LikeDocument2 pagesStat 240 Quiz 3 KEY Answers Underlined and in Bold Questions 1-3 The Distribution of Systolic Blood Pressures Within A Certain Age Group Looks LikecatalinauroraNo ratings yet