You might also like
- Android Application For Structural Health Monitoring and Data Analytics of Roads PDFDocument5 pagesAndroid Application For Structural Health Monitoring and Data Analytics of Roads PDFEngr Suleman MemonNo ratings yet
- Credit Card Fraud Detection Using Hidden Markov Model-A SurveyDocument3 pagesCredit Card Fraud Detection Using Hidden Markov Model-A SurveypayoxNo ratings yet
- Student Attendance System Via Face RecognitionDocument6 pagesStudent Attendance System Via Face RecognitionIJRASETPublicationsNo ratings yet
- Applied Sciences: Applications of Computer Vision in Automation and RoboticsDocument3 pagesApplied Sciences: Applications of Computer Vision in Automation and RoboticsNourhan FathyNo ratings yet
- Classification and Counting of Vehicle Using Image Processing TechniquesDocument10 pagesClassification and Counting of Vehicle Using Image Processing TechniquesIJRASETPublicationsNo ratings yet
- Non-Destructive Defect Detection Using MASK R-CNN On Industrial Radiography of MachinesDocument17 pagesNon-Destructive Defect Detection Using MASK R-CNN On Industrial Radiography of MachinesIJRASETPublicationsNo ratings yet
- 28-04-2021-1619594381-6 - Ijcse-6. Ijcse - Defect Classification in Surface Structure of Steels Using Deep LearningDocument10 pages28-04-2021-1619594381-6 - Ijcse-6. Ijcse - Defect Classification in Surface Structure of Steels Using Deep Learningiaset123No ratings yet
- Automated Smart Attendance System Using Face RecognitionDocument8 pagesAutomated Smart Attendance System Using Face RecognitionIJRASETPublicationsNo ratings yet
- Dhanesh - N - Machine Vision SystemDocument23 pagesDhanesh - N - Machine Vision SystemAswin madhuNo ratings yet
- BdareportDocument15 pagesBdareportCoPratiksha AhireNo ratings yet
- Face Detection Tracking OpencvDocument6 pagesFace Detection Tracking OpencvMohamed ShameerNo ratings yet
- Smart MeteringDocument4 pagesSmart MeteringEighthSenseGroupNo ratings yet
- Journal - A Smart Attendance System Based On Face Recognition Challenges and EffectsDocument6 pagesJournal - A Smart Attendance System Based On Face Recognition Challenges and EffectsAbdulkadir Shehu bariNo ratings yet
- Enhanced Technique For Multiple Face Detection Based On LBPH (Local Binary Patterns Histograms) A ReviewDocument6 pagesEnhanced Technique For Multiple Face Detection Based On LBPH (Local Binary Patterns Histograms) A ReviewIJRASETPublicationsNo ratings yet
- A Research Study On Unsupervised Machine Learning Algorithms For Early Fault Detection in Predictive MaintenanceDocument7 pagesA Research Study On Unsupervised Machine Learning Algorithms For Early Fault Detection in Predictive MaintenanceSayan BhattacharyaNo ratings yet
- Implementation Paper On Network DataDocument6 pagesImplementation Paper On Network DataIJRASETPublicationsNo ratings yet
- Facial Recognition Attendance System Using Deep LearningDocument9 pagesFacial Recognition Attendance System Using Deep LearningIJRASETPublicationsNo ratings yet
- Face Recognition Based Automated Student Attendance SystemDocument4 pagesFace Recognition Based Automated Student Attendance SystemEditor IJTSRDNo ratings yet
- Computer VisionDocument4 pagesComputer Visionpurvi srivastavaNo ratings yet
- Auto Attendance SystemDocument7 pagesAuto Attendance SystemIJRASETPublicationsNo ratings yet
- Digital Forensics Based Defence Security SystemDocument8 pagesDigital Forensics Based Defence Security SystemIJRASETPublicationsNo ratings yet
- Date Fruit Classification ProjectDocument11 pagesDate Fruit Classification ProjectMohammad Faraz FarooqiNo ratings yet
- A Novel Scheme For Accurate Remaining Useful Life Prediction For Industrial IoTs by Using Deep Neural NetworkDocument9 pagesA Novel Scheme For Accurate Remaining Useful Life Prediction For Industrial IoTs by Using Deep Neural NetworkAdam HansenNo ratings yet
- Information and Measurement Technologies in Mechatronics and RoboticsDocument7 pagesInformation and Measurement Technologies in Mechatronics and RoboticsviktorNo ratings yet
- Sukkur IBA University Final Year Project on Date Fruit ClassificationDocument11 pagesSukkur IBA University Final Year Project on Date Fruit ClassificationMohammad Faraz FarooqiNo ratings yet
- Friction Welding-Edge Detection Using Python.Document11 pagesFriction Welding-Edge Detection Using Python.senthil muruganNo ratings yet
- Comparative Study of Human PoseDocument9 pagesComparative Study of Human PoseEswariah VannamNo ratings yet
- Covid Future Prediction Using Machine LearningDocument7 pagesCovid Future Prediction Using Machine LearningIJRASETPublications100% (1)
- Smart Checkout System For SupermarketDocument7 pagesSmart Checkout System For SupermarketIJRASETPublicationsNo ratings yet
- Ijettcs 2016 04 01 41Document7 pagesIjettcs 2016 04 01 41International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Customer Churn Prediction in Banking Sector - A Hybrid ApproachDocument6 pagesCustomer Churn Prediction in Banking Sector - A Hybrid ApproachIJRASETPublicationsNo ratings yet
- Implementation of Bootstrap Technique in Detection of Road Sign Using Machine LearningDocument8 pagesImplementation of Bootstrap Technique in Detection of Road Sign Using Machine LearningIJRASETPublicationsNo ratings yet
- Implementation of 3D Optical Scanning Technology ForDocument13 pagesImplementation of 3D Optical Scanning Technology ForDinesh KumarNo ratings yet
- Fabric Color and Design Identification For Vision ImpairedDocument6 pagesFabric Color and Design Identification For Vision ImpairedIJRASETPublicationsNo ratings yet
- A Novel Deep Learning Representation For Industrial Control System DataDocument15 pagesA Novel Deep Learning Representation For Industrial Control System Data胡浩No ratings yet
- A Review On Faulty Product Detection and Separation System For Measuring Accurate Weight of SOAPDocument5 pagesA Review On Faulty Product Detection and Separation System For Measuring Accurate Weight of SOAPIJRASETPublicationsNo ratings yet
- Ijcrcst January17 12Document4 pagesIjcrcst January17 12EdwardNo ratings yet
- End To End Car Selling Portal by Loan Prediction Using Machine LearningDocument13 pagesEnd To End Car Selling Portal by Loan Prediction Using Machine LearningIJRASETPublicationsNo ratings yet
- Data Analysis and Price Prediction of Black Friday Sales Using Machine Learning Techniques IJERTV10IS070271Document8 pagesData Analysis and Price Prediction of Black Friday Sales Using Machine Learning Techniques IJERTV10IS070271Prateek beheraNo ratings yet
- Smart Pricing Estimating Price of Car Using Enhanced Features and Knowledge-Based SystemDocument10 pagesSmart Pricing Estimating Price of Car Using Enhanced Features and Knowledge-Based SystemIJRASETPublicationsNo ratings yet
- Android Based Classic PARKADE SystemDocument5 pagesAndroid Based Classic PARKADE SystemIJRASETPublicationsNo ratings yet
- Research Paper On Machine VisionDocument5 pagesResearch Paper On Machine Visiongw259gj7100% (1)
- Machine Vision Technology: Past, Present, and FutureDocument12 pagesMachine Vision Technology: Past, Present, and FutureMekaTronNo ratings yet
- Robot Vision System Detects Speeding Vehicles Using Smart Card Tech (39Document14 pagesRobot Vision System Detects Speeding Vehicles Using Smart Card Tech (39TMDNo ratings yet
- fin_irjmets1646225071Document6 pagesfin_irjmets1646225071ToyeebNo ratings yet
- Churn Prediction Using Machine Learning ModelsDocument6 pagesChurn Prediction Using Machine Learning ModelsIJRASETPublicationsNo ratings yet
- Implementation of A Real-Time Vision Based Vehicle License Plate Recognition SystemDocument8 pagesImplementation of A Real-Time Vision Based Vehicle License Plate Recognition SystemIJRASETPublicationsNo ratings yet
- Industrial AIDocument29 pagesIndustrial AIVipparthy Sai EsvarNo ratings yet
- SynopsisDocument9 pagesSynopsisKiran SidhuNo ratings yet
- Prediction of Air Quality Index Using Supervised Machine LearningDocument14 pagesPrediction of Air Quality Index Using Supervised Machine LearningIJRASETPublicationsNo ratings yet
- LibroDocument8 pagesLibrosebastianmelo82181No ratings yet
- Detection of Broken Blister Using Canny and Rc-AlgorithmDocument4 pagesDetection of Broken Blister Using Canny and Rc-AlgorithmijsretNo ratings yet
- Editorial Article - Cs TrendsDocument4 pagesEditorial Article - Cs TrendsKholid BuiNo ratings yet
- Credit Card Transaction Using Face Recognition AuthenticationDocument7 pagesCredit Card Transaction Using Face Recognition AuthenticationRanjan BangeraNo ratings yet
- Traffic Density Detection Using Image ProcessingDocument80 pagesTraffic Density Detection Using Image ProcessingHarsh KatalkarNo ratings yet
- NonContactwhole Part Inspection FinalDocument10 pagesNonContactwhole Part Inspection Finalkranthi142434No ratings yet
- Biometric Recognition System ExplainedDocument5 pagesBiometric Recognition System ExplainedrajNo ratings yet
- Android Application For Meter Reading Using OCRDocument4 pagesAndroid Application For Meter Reading Using OCRAnwar PatelNo ratings yet
- Face Detection and Recognition on Mobile DevicesFrom EverandFace Detection and Recognition on Mobile DevicesRating: 1 out of 5 stars1/5 (1)
- Quickly detect high temperatures with handheld thermography cameraDocument4 pagesQuickly detect high temperatures with handheld thermography cameraMuhamamd Irshad MaanNo ratings yet
- Social EntrepreneurshipDocument21 pagesSocial EntrepreneurshipSyamila HusnaNo ratings yet
- Volume 103, Issue 15Document24 pagesVolume 103, Issue 15The TechniqueNo ratings yet
- Matsui 1409r TV SMDocument29 pagesMatsui 1409r TV SMGsmHelpNo ratings yet
- The Road To BerlinDocument49 pagesThe Road To Berlinweter44100% (9)
- Welcome To The Project Presentation On Number PlateDocument21 pagesWelcome To The Project Presentation On Number Plateapi-3696125100% (1)
- Vulcan: 1200mm Raven OctocopterDocument3 pagesVulcan: 1200mm Raven OctocopterMuhammedNayeemNo ratings yet
- WebtocDocument22 pagesWebtocOndineSelkieNo ratings yet
- Electronic television historyDocument3 pagesElectronic television historyfunmastiNo ratings yet
- Banner Vision SensorsDocument32 pagesBanner Vision SensorsMemik TylnNo ratings yet
- Guide D'utilisation de Virtual DubDocument9 pagesGuide D'utilisation de Virtual DubScribd ReaderNo ratings yet
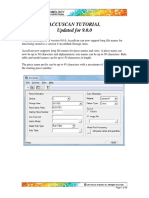
- Accuscan TutorialDocument36 pagesAccuscan Tutorialoniel40100% (1)
- Materi PoetryDocument36 pagesMateri PoetryYarmanto100% (1)
- Datenblatt M+ (Typ+240) eDocument3 pagesDatenblatt M+ (Typ+240) eDFNo ratings yet
- Cosmopolitan PH 2016Document137 pagesCosmopolitan PH 2016Max Dino0% (1)
- UntitledDocument16 pagesUntitledapi-145791059No ratings yet
- Baguio CityDocument7 pagesBaguio CityChristian Joseph GriñoNo ratings yet
- Activity 3 ScoresheetDocument2 pagesActivity 3 ScoresheetNorthwest FrancoNo ratings yet
- Manual Konica 7115-7118Document163 pagesManual Konica 7115-7118alelicuNo ratings yet
- Grand Opening FlyerDocument1 pageGrand Opening Flyerapi-313419441No ratings yet
- Basic Principles of Graphics and Layout InfographicDocument84 pagesBasic Principles of Graphics and Layout InfographicYvan PaezNo ratings yet
- WhenthewallswatchbyeDocument4 pagesWhenthewallswatchbyeapi-282835931No ratings yet
- 1.6 First Term - Exam - 42.95Document20 pages1.6 First Term - Exam - 42.95Lädy SalcedoNo ratings yet
- PitStop User Guide (EnUS)Document324 pagesPitStop User Guide (EnUS)Alexandre Gonçalves Pereda GonçalvesNo ratings yet
- How to Fix Poor Photos and Remove Unwanted ObjectsDocument18 pagesHow to Fix Poor Photos and Remove Unwanted Objectsdragan stanNo ratings yet
- Victor by Hasselblad Magazine Issue 09 2009Document126 pagesVictor by Hasselblad Magazine Issue 09 2009Paolo CaldarellaNo ratings yet
- Abstract - : Bhor - Dipali.A, Dr.G.U.KharatDocument5 pagesAbstract - : Bhor - Dipali.A, Dr.G.U.KharatArnav GudduNo ratings yet
- Mass Comm NDDocument85 pagesMass Comm NDVictor Emeka Azukwu100% (3)
- Mindset 1 Unit 7 Student Printable RLDocument10 pagesMindset 1 Unit 7 Student Printable RLTrang PhamNo ratings yet
- Leo Kwan Creating MingChaDocument20 pagesLeo Kwan Creating MingChaLeo CL KwanNo ratings yet