You might also like
- Upload Final Stats 1040 Revised 1 0Document6 pagesUpload Final Stats 1040 Revised 1 0api-366026174No ratings yet
- Aaron Skittle Project FinalDocument14 pagesAaron Skittle Project Finalapi-326129923No ratings yet
- Statistics Skittles ProjectDocument7 pagesStatistics Skittles Projectapi-302339334No ratings yet
- Skittle NewDocument7 pagesSkittle Newapi-356508242No ratings yet
- Skittles Term ProjectDocument12 pagesSkittles Term Projectapi-429606575No ratings yet
- Skittles Term Project Final PaperDocument15 pagesSkittles Term Project Final Paperapi-339884559No ratings yet
- Topic03 Correlation RegressionDocument81 pagesTopic03 Correlation RegressionpradeepNo ratings yet
- Math 1030 Skittles Term ProjectDocument8 pagesMath 1030 Skittles Term Projectapi-340538273No ratings yet
- Skittles Proyect Part 5Document7 pagesSkittles Proyect Part 5api-509398997No ratings yet
- ADDITIONAL MATHEMATICS SBA 2019 (Cathiana Samaroo, Miranda Thomas, Rhea Sahai, Christal Craig)Document13 pagesADDITIONAL MATHEMATICS SBA 2019 (Cathiana Samaroo, Miranda Thomas, Rhea Sahai, Christal Craig)shakelNo ratings yet
- STAT 200 Week 6 HomeworkDocument11 pagesSTAT 200 Week 6 HomeworkAlex MunyaoNo ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
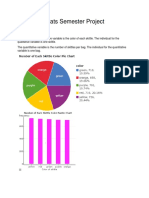
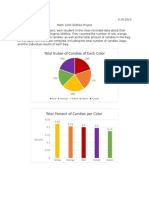
- Stats Semester ProjectDocument11 pagesStats Semester Projectapi-276989071No ratings yet
- T-TEST Sample Solved ProblemsDocument4 pagesT-TEST Sample Solved Problems玛丽亚No ratings yet
- Skittles Research Project StatisticsDocument6 pagesSkittles Research Project Statisticsapi-329181361No ratings yet
- SkittleDocument6 pagesSkittleapi-378470372No ratings yet
- Term Project - Skittles CollectionDocument11 pagesTerm Project - Skittles Collectionapi-365526530No ratings yet
- Students Sample Data To WorkDocument17 pagesStudents Sample Data To WorkJoanna AchemaNo ratings yet
- Year 7 MATHS Exam. Sem 1Document19 pagesYear 7 MATHS Exam. Sem 1elezabeth100% (1)
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623No ratings yet
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135No ratings yet
- Investigating Uneven Color Distribution in M&M's PacksDocument12 pagesInvestigating Uneven Color Distribution in M&M's Packsarilove rigsby83% (6)
- Pie Chart For The ProjectDocument7 pagesPie Chart For The Projectapi-325968264No ratings yet
- Skittles ReportDocument15 pagesSkittles Reportapi-271901299No ratings yet
- The Little ElfDocument7 pagesThe Little ElfSigal DayanNo ratings yet
- Tablas de MultiplicarDocument1 pageTablas de MultiplicarDaniel OteroNo ratings yet
- Skittles ReportDocument5 pagesSkittles Reportapi-242736484No ratings yet
- Las Tablas de MultiplicarDocument1 pageLas Tablas de Multiplicarjuan pablo vera meloNo ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Math 1040 Skittles Project Worksheet-2 1Document6 pagesMath 1040 Skittles Project Worksheet-2 1api-316476731No ratings yet
- Skittles Project Part 7Document4 pagesSkittles Project Part 7api-454435360No ratings yet
- Statistics AssignmentDocument7 pagesStatistics AssignmentAbdullateef AdedoyinNo ratings yet
- Term Project Part 8Document9 pagesTerm Project Part 8api-242224172No ratings yet
- Skittles FinalDocument7 pagesSkittles Finalapi-582864642No ratings yet
- Skittles Part 4Document3 pagesSkittles Part 4api-405527325No ratings yet
- 1040 Skittles ProjectDocument4 pages1040 Skittles Projectapi-279941094No ratings yet
- Abm Act1 Sub2 M1Document6 pagesAbm Act1 Sub2 M1alligerhi2007No ratings yet
- Introduction To Statistics CH 3Document81 pagesIntroduction To Statistics CH 3Leuleseged TsegayeNo ratings yet
- BBA 4th DDocument11 pagesBBA 4th DAleenaNo ratings yet
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- SemillanoMarvin Quiz3Document3 pagesSemillanoMarvin Quiz3Dhevin VergaraNo ratings yet
- MathskittleworksheetDocument3 pagesMathskittleworksheetapi-139252265No ratings yet
- Rick PDFDocument14 pagesRick PDFAlex FrancoNo ratings yet
- StatistikDocument16 pagesStatistikSyifa FauziyahNo ratings yet
- Mates ColoridasDocument31 pagesMates ColoridasPolvorillaNo ratings yet
- Group Project Part 6-E PortfolioDocument10 pagesGroup Project Part 6-E Portfolioapi-253208467No ratings yet
- 10 WargamulayaDocument27 pages10 WargamulayaIsuru Pethum AlwisNo ratings yet
- Summer 2000 Final Form 2Document6 pagesSummer 2000 Final Form 2carlvin96No ratings yet
- Annova and Chi-SquareDocument30 pagesAnnova and Chi-Squarevampire88100% (2)
- Calculating pirate gold standard deviationDocument9 pagesCalculating pirate gold standard deviationPresana VisionNo ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Daftar Pustaka dan Perhitungan Statistik untuk Analisis Empat Jenis SnackDocument5 pagesDaftar Pustaka dan Perhitungan Statistik untuk Analisis Empat Jenis SnacknailaamirotulummahNo ratings yet
- Science Quiz Bee Score Sheet Grade 6Document3 pagesScience Quiz Bee Score Sheet Grade 6Anna Sheryl DimacaliNo ratings yet
- BicyclesDocument9 pagesBicyclesSeptiya WulandariNo ratings yet
- Mathematics Card Kad Matematik: Tanda TandaDocument3 pagesMathematics Card Kad Matematik: Tanda TandananthiniNo ratings yet
- Kad Matematik 2017Document4 pagesKad Matematik 2017Sjkt Ldg Sagil JohorNo ratings yet
- AssignmentDocument12 pagesAssignmentVishal SinghNo ratings yet
- (Math 6 WK 9 L13) - Division of Decimal NumbersDocument62 pages(Math 6 WK 9 L13) - Division of Decimal NumbersRhea OciteNo ratings yet
- Mindful Maths 3: Use Your Statistics to Solve These Puzzling PicturesFrom EverandMindful Maths 3: Use Your Statistics to Solve These Puzzling PicturesNo ratings yet
- More Minute Math Drills, Grades 3 - 6: Multiplication and DivisionFrom EverandMore Minute Math Drills, Grades 3 - 6: Multiplication and DivisionRating: 5 out of 5 stars5/5 (1)
- Akuntansi RadikalDocument19 pagesAkuntansi RadikalPrayogo P HartoNo ratings yet
- 01 Ml-Overview SlidesDocument58 pages01 Ml-Overview Slidesashishamitav123No ratings yet
- Piu RajakDocument18 pagesPiu Rajakpiu_rajakNo ratings yet
- Business SimulationDocument27 pagesBusiness SimulationDanny HeldtNo ratings yet
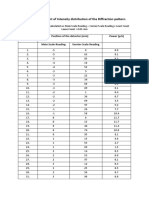
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- How To Be A Good ListenerDocument26 pagesHow To Be A Good ListenerHarmanjit Dhillon100% (1)
- MBR Lab Week 10-12-1Document65 pagesMBR Lab Week 10-12-1Sadaqat AliNo ratings yet
- Basic Chemistry: A Foundation for Understanding Our Natural WorldDocument16 pagesBasic Chemistry: A Foundation for Understanding Our Natural WorldVanessa JabagatNo ratings yet
- A Level Psychology Practice Questions: Research MethodsDocument82 pagesA Level Psychology Practice Questions: Research Methodsjohn baptesNo ratings yet
- Annisa Khoirina Nurmadinah JournalDocument11 pagesAnnisa Khoirina Nurmadinah JournalAnnisa Khoirina NurMadinahNo ratings yet
- Measurement of Magnetic Fields: Physics 211LDocument5 pagesMeasurement of Magnetic Fields: Physics 211LElias HannaNo ratings yet
- Hypothesis-TestingDocument47 pagesHypothesis-TestingJOSE EPHRAIM MAGLAQUENo ratings yet
- Research Report On Solid Waste Management PDFDocument87 pagesResearch Report On Solid Waste Management PDFAnonymous OP6R1ZS100% (1)
- Critical AppraisalDocument11 pagesCritical Appraisalnadifamaulani08No ratings yet
- Martler Chaper - 1 PDFDocument31 pagesMartler Chaper - 1 PDFSigies GunsNo ratings yet
- HT3 Probability and Stats Test P2Document6 pagesHT3 Probability and Stats Test P2Jakub Kotas-CvrcekNo ratings yet
- Practical Research 1 M1Document4 pagesPractical Research 1 M1Ritney AgpalasinNo ratings yet
- Makerere University: College of Education and External Studies. School of EducationDocument4 pagesMakerere University: College of Education and External Studies. School of EducationKevin SkillzNo ratings yet
- Combining Normal Random VariablesDocument4 pagesCombining Normal Random Variablesabel mahendraNo ratings yet
- A Study On Customer Satisfaction of MAPRO Products in PUNEDocument40 pagesA Study On Customer Satisfaction of MAPRO Products in PUNETej GhareNo ratings yet
- Jurnal Efektivitas Model Pembelajaran Think Pair Share Ditinjau Dari Kemampuan Komunikasi Matematis SiswaDocument14 pagesJurnal Efektivitas Model Pembelajaran Think Pair Share Ditinjau Dari Kemampuan Komunikasi Matematis SiswaDila RizkianaNo ratings yet
- Consumer Behavior of Bottled WaterDocument55 pagesConsumer Behavior of Bottled Watersonia23singh247100% (1)
- Hypotheses and AssumptionsDocument2 pagesHypotheses and AssumptionsJulieta CarcoleNo ratings yet
- Stat-703 Final PaperDocument13 pagesStat-703 Final PaperʚAwais MirzaʚNo ratings yet
- Statistical Inference - MA252Document2 pagesStatistical Inference - MA252Mohammad JamilNo ratings yet
- Research Methods and AnalysisDocument146 pagesResearch Methods and AnalysisAsteway MesfinNo ratings yet
- Sharon Wynne-ICTS Science-Chemistry 106 Teacher Certification Test Prep Study Guide, 2nd Edition (XAM ICTS) - XAMOnline - Com (2007)Document464 pagesSharon Wynne-ICTS Science-Chemistry 106 Teacher Certification Test Prep Study Guide, 2nd Edition (XAM ICTS) - XAMOnline - Com (2007)Alazar BekeleNo ratings yet
- Biostatistics - Anr312 PWR PT Lecture (April, 2020)Document34 pagesBiostatistics - Anr312 PWR PT Lecture (April, 2020)Chileshe SimonNo ratings yet
- Methodology 2Document5 pagesMethodology 2Latest Jobs In PakistanNo ratings yet
- Representation and Summary of Data - Location (Questions)Document4 pagesRepresentation and Summary of Data - Location (Questions)Hassan HussainNo ratings yet