You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Unit 9final 1Document21 pagesUnit 9final 1jazz440No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Unit 6finalDocument20 pagesUnit 6finalAnonymous bTh744z7E6No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Bba103 MQP KeysDocument15 pagesBba103 MQP KeysDr. Smita ChoudharyNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- A High-Performance Telecommunications Data Warehouse Using DB2 For LinuxDocument17 pagesA High-Performance Telecommunications Data Warehouse Using DB2 For Linuxjazz440No ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- BDE IPConfigOutputDocument1 pageBDE IPConfigOutputjazz440No ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- JavaDocument1 pageJavaNajib AbdillahNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- CodeDocument1,672 pagesCodejazz440No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Unit 7 Legal Environment: StructureDocument17 pagesUnit 7 Legal Environment: Structurejazz440No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Unit 7 Index Numbers: StructureDocument27 pagesUnit 7 Index Numbers: Structurejazz440No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Unit 2 Collection, Classification, and Presentation of Data: StructureDocument20 pagesUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440No ratings yet
- Unit 2final 1Document19 pagesUnit 2final 1jazz440No ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Unit 5final 1Document17 pagesUnit 5final 1jazz440No ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Unit 2 Collection, Classification, and Presentation of Data: StructureDocument20 pagesUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Unit 6finalDocument24 pagesUnit 6finaljazz440No ratings yet
- FDA Forms For Medicines Shipments Only To USADocument2 pagesFDA Forms For Medicines Shipments Only To USAjazz440No ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- (IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFDocument26 pages(IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFblackbacNo ratings yet
- Ewr Terminal BDocument1 pageEwr Terminal Bjazz440No ratings yet
- Research Method Test1-AugDocument2 pagesResearch Method Test1-Augjazz440No ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Schedule Week4 Nov 2014 For StudentsDocument6 pagesSchedule Week4 Nov 2014 For Studentsjazz440No ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Listening Answer SheetDocument1 pageListening Answer Sheetjazz440No ratings yet
- January 2017: Sunday Monday Tuesday Wednesday Thursday Friday SaturdayDocument12 pagesJanuary 2017: Sunday Monday Tuesday Wednesday Thursday Friday Saturdayjazz440No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Canada MigrationDocument14 pagesCanada Migrationjazz440No ratings yet
- Gotham Deep Square Pan CookbookDocument38 pagesGotham Deep Square Pan Cookbookjazz440No ratings yet
- Express Entry System: Information For Skilled Foreign WorkersDocument16 pagesExpress Entry System: Information For Skilled Foreign WorkersTitoFernandezNo ratings yet
- Linux CommndDocument26 pagesLinux CommnddhivyaNo ratings yet
- 32 Ielts Essay Samples Band 9Document34 pages32 Ielts Essay Samples Band 9mh73% (26)
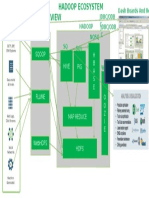
- Hadoop Ecosystem PresentationDocument1 pageHadoop Ecosystem Presentationjazz440No ratings yet
- Bigtable: A Distributed Storage System For Structured DataDocument14 pagesBigtable: A Distributed Storage System For Structured DataMax ChiuNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Hadoop SetupDocument43 pagesHadoop Setupjazz440No ratings yet
- PeopleSoft CMS Student Self ServiceDocument106 pagesPeopleSoft CMS Student Self ServiceJunaid AhmedNo ratings yet
- Write An Ioctl Command To Sort The First Quantum of The First Sculldev in Scull Device (Modify Main.c)Document7 pagesWrite An Ioctl Command To Sort The First Quantum of The First Sculldev in Scull Device (Modify Main.c)Kingpin VnyNo ratings yet
- Sage X3 - User Guide - HTG-ADC PDFDocument24 pagesSage X3 - User Guide - HTG-ADC PDFcaplusinc75% (4)
- Get started-WPS OfficeDocument14 pagesGet started-WPS OfficeAli ShaikhNo ratings yet
- Module 3 Basic Computer ConceptsDocument23 pagesModule 3 Basic Computer ConceptsKen Mark YoungNo ratings yet
- OpenMRS Presentation 2Document14 pagesOpenMRS Presentation 2Pratik MandrekarNo ratings yet
- Module 1-85206-1Document5 pagesModule 1-85206-1Erick MeguisoNo ratings yet
- bcsl-063 Solved Lab ManualDocument196 pagesbcsl-063 Solved Lab Manuala bNo ratings yet
- Cisco 4000 Family Integrated Services Data Sheet PDFDocument26 pagesCisco 4000 Family Integrated Services Data Sheet PDFsrujanNo ratings yet
- Access Control List: ACL'sDocument31 pagesAccess Control List: ACL'sTolosa TafeseNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Free Multiple Choice Question of Computer Science, Banking - ExamrocksDocument4 pagesFree Multiple Choice Question of Computer Science, Banking - ExamrocksRanita BanerjeeNo ratings yet
- CPP TutorialDocument231 pagesCPP Tutorialapi-265571646No ratings yet
- External Design: Topic ListDocument17 pagesExternal Design: Topic ListbinsalweNo ratings yet
- CPT 168 HW#9 Answer KeyDocument14 pagesCPT 168 HW#9 Answer KeyJordan50% (4)
- VDR HLD-S - Technical ManualDocument150 pagesVDR HLD-S - Technical ManualTuấn Lê MinhNo ratings yet
- Computer Abbrevations-Mcq'S: 1. What Is Full Form of BMP ? Byte Map Byte Map Process Bit Map ProcessDocument6 pagesComputer Abbrevations-Mcq'S: 1. What Is Full Form of BMP ? Byte Map Byte Map Process Bit Map ProcessAdesh Partap SinghNo ratings yet
- Red Tact OnDocument12 pagesRed Tact Onnavita466No ratings yet
- 10 KV Digital Insulation TesterDocument2 pages10 KV Digital Insulation TesterELECTROMECANICA CADMA S.R.L.No ratings yet
- Huawei AirEngine 8760-X1-PRO Access Point DatasheetDocument15 pagesHuawei AirEngine 8760-X1-PRO Access Point DatasheetZekariyas GirmaNo ratings yet
- Fast Phrase Search For Encrypted Cloud StorageDocument50 pagesFast Phrase Search For Encrypted Cloud Storagekrishna reddyNo ratings yet
- Nmea Signals Multiplexer Snmea6: Enamor Products Nmea Modules FamilyDocument1 pageNmea Signals Multiplexer Snmea6: Enamor Products Nmea Modules FamilyRadekNo ratings yet
- Final Rajat Mini ProjectDocument50 pagesFinal Rajat Mini ProjectRamanNo ratings yet
- Marketing Masters EbookDocument560 pagesMarketing Masters EbookNikola Lukac100% (1)
- Xeon 5400 AnimatedDocument12 pagesXeon 5400 AnimatedkshehzadNo ratings yet
- Final Research Paper On HrisDocument28 pagesFinal Research Paper On Hrispink_bhat50% (2)
- Beginner's Guide To IOS 11 App Development Using Swift 4Document215 pagesBeginner's Guide To IOS 11 App Development Using Swift 4Franklin morelNo ratings yet
- Difference Between Managed and Unmanaged CodeDocument3 pagesDifference Between Managed and Unmanaged CodechristinesharonNo ratings yet
- nRF9160 PS v1.2Document404 pagesnRF9160 PS v1.2gobind raiNo ratings yet
- Nfsv4 Co-Existence With Cifs in A Multi-Protocol EnvironmentDocument19 pagesNfsv4 Co-Existence With Cifs in A Multi-Protocol EnvironmentFrez17No ratings yet
- Alcatel Lucent Alerts: Prior To Removing A SF/CPM Card Press The RESET ButtonDocument2 pagesAlcatel Lucent Alerts: Prior To Removing A SF/CPM Card Press The RESET ButtonMarkostobyNo ratings yet