You might also like
- Table of Contents - LatestDocument5 pagesTable of Contents - LatestGaurav ManglaNo ratings yet
- R Graphics Essentials For Great Data Visualization 9781979748100 CDocument257 pagesR Graphics Essentials For Great Data Visualization 9781979748100 CGuangping QieNo ratings yet
- GARCH Models in Python 1Document31 pagesGARCH Models in Python 1visNo ratings yet
- Univariate Time Series Analysis With Matlab - M. PerezDocument147 pagesUnivariate Time Series Analysis With Matlab - M. Perezvincus27No ratings yet
- SolutionsShumway PDFDocument82 pagesSolutionsShumway PDFjuve A.No ratings yet
- Modelling Non-Stationary Times SeriesDocument263 pagesModelling Non-Stationary Times SeriesFAUSTINOESTEBAN100% (1)
- Brinson Fachler 1985 Multi Currency PADocument4 pagesBrinson Fachler 1985 Multi Currency PAGeorgi MitovNo ratings yet
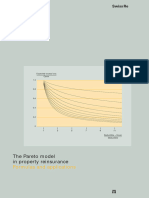
- Pub Pareto Model in Property Reinsurance enDocument33 pagesPub Pareto Model in Property Reinsurance enAnissa TataNo ratings yet
- Applied Linear Regression Models 4th Ed NoteDocument46 pagesApplied Linear Regression Models 4th Ed Noteken_ng333No ratings yet
- Practical Signal PDFDocument486 pagesPractical Signal PDFSakthivel Ganesan100% (3)
- Week02 - Bracketing MethodsDocument24 pagesWeek02 - Bracketing MethodsInunHazwaniKhairuddin100% (2)
- Project Euler ProblemsDocument214 pagesProject Euler Problemspeter100% (1)
- Section 11-4 & 11-6 WorksheetDocument2 pagesSection 11-4 & 11-6 WorksheetsdenoyerNo ratings yet
- Python For EconomistsDocument34 pagesPython For EconomistsquoroNo ratings yet
- Summary Applied Econometric Time SeriesDocument10 pagesSummary Applied Econometric Time SeriesRashidAliNo ratings yet
- PanelDocument93 pagesPaneljjanggu100% (1)
- SOA Exam CDocument6 pagesSOA Exam CNoDriverNo ratings yet
- Chapter 7 - TThe Box-Jenkins Methodology For ARIMA ModelsDocument205 pagesChapter 7 - TThe Box-Jenkins Methodology For ARIMA Modelsnkminh19082003No ratings yet
- Ayuda AmplDocument11 pagesAyuda AmplpegoroNo ratings yet
- Shiny Cheatsheet PDFDocument2 pagesShiny Cheatsheet PDFAnto PadaunanNo ratings yet
- Stochastic Differential Equations: An Introduction with Applications in Population Dynamics ModelingFrom EverandStochastic Differential Equations: An Introduction with Applications in Population Dynamics ModelingNo ratings yet
- Pension Finance: Putting the Risks and Costs of Defined Benefit Plans Back Under Your ControlFrom EverandPension Finance: Putting the Risks and Costs of Defined Benefit Plans Back Under Your ControlNo ratings yet
- Lahore University of Management Sciences ECON 330 - EconometricsDocument3 pagesLahore University of Management Sciences ECON 330 - EconometricsshyasirNo ratings yet
- Phoebus J. Dhrymes (Auth.) - Introductory Econometrics-Springer-Verlag New York (1978) PDFDocument435 pagesPhoebus J. Dhrymes (Auth.) - Introductory Econometrics-Springer-Verlag New York (1978) PDFMelissa OrozcoNo ratings yet
- BOOK-Soner-Stochastic Optimal Control in FinanceDocument67 pagesBOOK-Soner-Stochastic Optimal Control in FinancefincalNo ratings yet
- A Linear Model of Cyclical GrowthDocument14 pagesA Linear Model of Cyclical GrowthErick ManchaNo ratings yet
- Instrumental Variables PDFDocument11 pagesInstrumental Variables PDFduytueNo ratings yet
- Fama Macbeth PDFDocument10 pagesFama Macbeth PDFfsfsefesfesNo ratings yet
- Econometría Bollerslev GARCH 1986Document21 pagesEconometría Bollerslev GARCH 1986Alejandro LopezNo ratings yet
- Monte Carlo Methods in Finance PDFDocument75 pagesMonte Carlo Methods in Finance PDFHasan SamiNo ratings yet
- Viscosity Measurement UsedDocument10 pagesViscosity Measurement Usedpiruthvi chendurNo ratings yet
- Quantlib ExercisesDocument71 pagesQuantlib ExercisesMauricio BedoyaNo ratings yet
- Solving DSGE Models Using DynareDocument11 pagesSolving DSGE Models Using DynarerudiminNo ratings yet
- Computational Finance Using MATLABDocument26 pagesComputational Finance Using MATLABpopoyboysNo ratings yet
- Tabout - Tutorial PDFDocument46 pagesTabout - Tutorial PDFAnonymous G1CGIybliTNo ratings yet
- Time Series Cheat SheetDocument2 pagesTime Series Cheat SheetAshkNo ratings yet
- A Document Class and A Package For Handling Multi-File ProjectsDocument14 pagesA Document Class and A Package For Handling Multi-File ProjectsRed OrangeNo ratings yet
- Lec06 - Panel DataDocument160 pagesLec06 - Panel DataTung NguyenNo ratings yet
- Dsur I Chapter 08 Logistic RegressionDocument41 pagesDsur I Chapter 08 Logistic RegressionDannyNo ratings yet
- Panel DataDocument13 pagesPanel DataAzime Hassen100% (1)
- A Energy Price ProcessesDocument5 pagesA Energy Price ProcessesEmily7959No ratings yet
- Tikz TutorialDocument14 pagesTikz Tutorialmitooquerer7260No ratings yet
- Unbalanced Panel Data PDFDocument51 pagesUnbalanced Panel Data PDFrbmalasaNo ratings yet
- Dickey-Fuller Unit Root TestDocument13 pagesDickey-Fuller Unit Root TestNouman ShafiqueNo ratings yet
- Takeshi Amemiya-Advanced Eco No MetricsDocument258 pagesTakeshi Amemiya-Advanced Eco No Metricsmalikaygusuz100% (1)
- PTC Mathcad Prime 3.1 Migration Guide PDFDocument58 pagesPTC Mathcad Prime 3.1 Migration Guide PDFJose DuarteNo ratings yet
- Calvo - Staggered Prices in A Utility-Maximizing FrameworkDocument16 pagesCalvo - Staggered Prices in A Utility-Maximizing Frameworkanon_78278064No ratings yet
- Macroeconomics: An Introduction to the Non-Walrasian ApproachFrom EverandMacroeconomics: An Introduction to the Non-Walrasian ApproachNo ratings yet
- CheatsheetOO LetterDocument4 pagesCheatsheetOO LetterniloyrayNo ratings yet
- Python Programming For Economics and FinanceDocument267 pagesPython Programming For Economics and FinanceMatheus TeixeiraNo ratings yet
- Arch Model and Time-Varying VolatilityDocument17 pagesArch Model and Time-Varying VolatilityJorge Vega RodríguezNo ratings yet
- R TutorialDocument26 pagesR TutorialkulchiNo ratings yet
- IEOR E4707 Spring 2016 SyllabusDocument2 pagesIEOR E4707 Spring 2016 SyllabusrrrreeeNo ratings yet
- Barro, Sala I Martin - 1992Document47 pagesBarro, Sala I Martin - 1992L Laura Bernal HernándezNo ratings yet
- Agent Based Simulation of A Financial MarketDocument21 pagesAgent Based Simulation of A Financial Marketmirando93No ratings yet
- AP Newsletter Q3 2019Document43 pagesAP Newsletter Q3 2019hadihadihaNo ratings yet
- Simulation and Monte Carlo: With Applications in Finance and MCMCFrom EverandSimulation and Monte Carlo: With Applications in Finance and MCMCNo ratings yet
- The Box-Jenkins MethodDocument14 pagesThe Box-Jenkins MethodAltaf KondakamaralaNo ratings yet
- Box Jenkins MethodDocument14 pagesBox Jenkins MethodAbhishekSinghGaurNo ratings yet
- Lec1 09 PDFDocument21 pagesLec1 09 PDFSri RamNo ratings yet
- MATH 461: Fourier Series and Boundary Value Problems: Chapter I: The Heat EquationDocument60 pagesMATH 461: Fourier Series and Boundary Value Problems: Chapter I: The Heat EquationAkhil ANo ratings yet
- hw1 PDFDocument3 pageshw1 PDF何明涛No ratings yet
- ArimaDocument8 pagesArimamulyonosarpanNo ratings yet
- The Title of The BookDocument23 pagesThe Title of The BookDavid González GamboaNo ratings yet
- SPM Questions Transformations IIIDocument6 pagesSPM Questions Transformations IIIjuriah binti ibrahim0% (1)
- Mathematics 1Document22 pagesMathematics 1RubyJanePartosa100% (1)
- Integration Partial Fractions PDFDocument10 pagesIntegration Partial Fractions PDFrendie100% (1)
- The Binomial Expansion The Binomial and Normal Distribution: ObjectivesDocument38 pagesThe Binomial Expansion The Binomial and Normal Distribution: ObjectivesRafJanuaBercasioNo ratings yet
- 2011 (Engg-Mat) emDocument9 pages2011 (Engg-Mat) emGandla Ravi ThejaNo ratings yet
- QB PowerpointDocument20 pagesQB PowerpointLatha ParisiramNo ratings yet
- Gaussian Filtering 2upDocument8 pagesGaussian Filtering 2upAanNo ratings yet
- Example RT#001 Recruitment Test - Maths and Logic: (Print Your Name)Document5 pagesExample RT#001 Recruitment Test - Maths and Logic: (Print Your Name)muussaNo ratings yet
- Fabrication Calculation PDFDocument98 pagesFabrication Calculation PDFkumarNo ratings yet
- Mathematics DLL Grade 9 Integral ExponentDocument3 pagesMathematics DLL Grade 9 Integral ExponentJeric SandoyNo ratings yet
- Mark Scheme (Results) : Summer 2018Document17 pagesMark Scheme (Results) : Summer 2018John JohnsonNo ratings yet
- CPP: Parabola: X Y Ax A at at B at at Acab T T Y AxDocument3 pagesCPP: Parabola: X Y Ax A at at B at at Acab T T Y AxSamridh GuptaNo ratings yet
- Mathematical Olympiad 2018Document6 pagesMathematical Olympiad 2018Saksham100% (1)
- Calculating Factor ScoresDocument32 pagesCalculating Factor ScoresBorna sfmopNo ratings yet
- Unit - 6 P, NP, and NP-CompleteDocument26 pagesUnit - 6 P, NP, and NP-Complete21311a1993No ratings yet
- Chapter 7 Discrete ProbablityDocument24 pagesChapter 7 Discrete ProbablityMeketa WoldeslassieNo ratings yet
- 01-1 Finite Difference MethodDocument37 pages01-1 Finite Difference MethodMyher ChNo ratings yet
- Chapter 4 Lec4Document65 pagesChapter 4 Lec4lucky tubeNo ratings yet
- CL09 WS Coordinate Geometry SHAROL 2023-24Document5 pagesCL09 WS Coordinate Geometry SHAROL 2023-24JOEL SUNNYNo ratings yet
- Checklist Subject 2019 2020Document31 pagesChecklist Subject 2019 2020batchayNo ratings yet
- Mathematics P1 May-June 2023 MG Afr & EngDocument15 pagesMathematics P1 May-June 2023 MG Afr & Engmasibulele641No ratings yet
- Mobile Communications HandbookDocument14 pagesMobile Communications HandbookSai RamNo ratings yet
- Lec. 2 - Metric and Normed SpacesDocument207 pagesLec. 2 - Metric and Normed Spacesessi90No ratings yet
- Short Tricks of Multiplication PDFDocument8 pagesShort Tricks of Multiplication PDFRamesh KumarNo ratings yet
- Thesis Darshan RamasubramanianDocument75 pagesThesis Darshan RamasubramanianCarlos AlarconNo ratings yet