You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Construction Tender Price IndexDocument356 pagesConstruction Tender Price IndexSwain Niranjan100% (1)
- Decision Tree AssignmentDocument5 pagesDecision Tree AssignmentBHAGWAT GEETANo ratings yet
- Aedes Aegypti Size, Reserves, Survival, and Flight PotentialDocument11 pagesAedes Aegypti Size, Reserves, Survival, and Flight PotentialAnirudh AcharyaNo ratings yet
- ETL Design and Code Guidelines V1Document18 pagesETL Design and Code Guidelines V1jazz440100% (1)
- Unit 2 Collection, Classification, and Presentation of Data: StructureDocument20 pagesUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440No ratings yet
- Unit 9final 1Document21 pagesUnit 9final 1jazz440No ratings yet
- Bba103 MQP KeysDocument15 pagesBba103 MQP KeysDr. Smita ChoudharyNo ratings yet
- Schedule Week4 Nov 2014 For StudentsDocument6 pagesSchedule Week4 Nov 2014 For Studentsjazz440No ratings yet
- Economic Systems in Business EnvironmentDocument17 pagesEconomic Systems in Business Environmentjazz440No ratings yet
- JavaDocument1 pageJavaNajib AbdillahNo ratings yet
- A High-Performance Telecommunications Data Warehouse Using DB2 For LinuxDocument17 pagesA High-Performance Telecommunications Data Warehouse Using DB2 For Linuxjazz440No ratings yet
- CodeDocument1,672 pagesCodejazz440No ratings yet
- Unit 2 Collection, Classification, and Presentation of Data: StructureDocument20 pagesUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440No ratings yet
- Unit 6finalDocument20 pagesUnit 6finalAnonymous bTh744z7E6No ratings yet
- Ewr Terminal BDocument1 pageEwr Terminal Bjazz440No ratings yet
- BDE IPConfigOutputDocument1 pageBDE IPConfigOutputjazz440No ratings yet
- Legal Environment of Business in IndiaDocument17 pagesLegal Environment of Business in Indiajazz440No ratings yet
- Unit 7 Index Numbers: StructureDocument27 pagesUnit 7 Index Numbers: Structurejazz440No ratings yet
- Unit 6finalDocument24 pagesUnit 6finaljazz440No ratings yet
- Canada MigrationDocument14 pagesCanada Migrationjazz440No ratings yet
- FDA Forms For Medicines Shipments Only To USADocument2 pagesFDA Forms For Medicines Shipments Only To USAjazz440No ratings yet
- (IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFDocument26 pages(IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFblackbacNo ratings yet
- Gotham Deep Square Pan CookbookDocument38 pagesGotham Deep Square Pan Cookbookjazz440No ratings yet
- Research Method Test1-AugDocument2 pagesResearch Method Test1-Augjazz440No ratings yet
- Listening Answer SheetDocument1 pageListening Answer Sheetjazz440No ratings yet
- Monthly calendar 2017Document12 pagesMonthly calendar 2017jazz440No ratings yet
- 32 Ielts Essay Samples Band 9Document34 pages32 Ielts Essay Samples Band 9mh73% (26)
- Express Entry System: Information For Skilled Foreign WorkersDocument16 pagesExpress Entry System: Information For Skilled Foreign WorkersTitoFernandezNo ratings yet
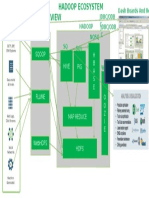
- Hadoop Ecosystem PresentationDocument1 pageHadoop Ecosystem Presentationjazz440No ratings yet
- Linux Basic Commands GuideDocument26 pagesLinux Basic Commands GuidedhivyaNo ratings yet
- Hadoop SetupDocument43 pagesHadoop Setupjazz440No ratings yet
- Bigtable: A Distributed Storage System For Structured DataDocument14 pagesBigtable: A Distributed Storage System For Structured DataMax ChiuNo ratings yet
- Statistics Analysis Scientific DataDocument308 pagesStatistics Analysis Scientific Datayonaye100% (3)
- The Calculation of The Dosage - Mortality Curve - BLISS 1935Document34 pagesThe Calculation of The Dosage - Mortality Curve - BLISS 1935Camilla Karen Fernandes CarneiroNo ratings yet
- Saphir NL PTA Tutorial 1 PDFDocument17 pagesSaphir NL PTA Tutorial 1 PDFAnonymous Vbv8SHv0bNo ratings yet
- XG BoostDocument5 pagesXG Boostola moviesNo ratings yet
- Accurate Forecasting Determines Inventory Levels in The Supply Chain - Continuous ReplenishmentDocument54 pagesAccurate Forecasting Determines Inventory Levels in The Supply Chain - Continuous ReplenishmentHimawan TanNo ratings yet
- Linear Panel Data Models in R - The PLM Package - R-BloggersDocument7 pagesLinear Panel Data Models in R - The PLM Package - R-Bloggersjcgutz3No ratings yet
- Attachment 1Document6 pagesAttachment 1muhammad saadNo ratings yet
- Beth Mukui Gretsa University-Past TenseDocument41 pagesBeth Mukui Gretsa University-Past TenseDenis MuiruriNo ratings yet
- The Moderating Effect of Intellectual Capital On The Relationship Between Corporate Governance and Companies Performance in PakistanDocument11 pagesThe Moderating Effect of Intellectual Capital On The Relationship Between Corporate Governance and Companies Performance in PakistanDharmiani DharmiNo ratings yet
- Bme Midterms KeyDocument9 pagesBme Midterms KeyLady PilaNo ratings yet
- Permeability Prediction Using Projection Pursuit Regression in The Abadi FieldDocument13 pagesPermeability Prediction Using Projection Pursuit Regression in The Abadi FieldTeja MulyawanNo ratings yet
- AnalytixLabs - Data Science Using Python9Document15 pagesAnalytixLabs - Data Science Using Python9pundirsandeepNo ratings yet
- Shivani Pandey TSFDocument32 pagesShivani Pandey TSFShivich10100% (1)
- Does Recognition Versus Disclosure Really Matter?: Flora Niu and Bixia XuDocument20 pagesDoes Recognition Versus Disclosure Really Matter?: Flora Niu and Bixia XuMrl 2701No ratings yet
- Introml 02 Regression Annotated PDFDocument26 pagesIntroml 02 Regression Annotated PDFMark NamNo ratings yet
- Do Certificate-of-Need Laws Increase Indigent Care?Document32 pagesDo Certificate-of-Need Laws Increase Indigent Care?Mercatus Center at George Mason UniversityNo ratings yet
- Analysis of Industrial Slabs-On-groundDocument273 pagesAnalysis of Industrial Slabs-On-groundbatteekhNo ratings yet
- Bayesian Analysis of Working Capital Management On Corporate Profitability: Evidence From IndiaDocument19 pagesBayesian Analysis of Working Capital Management On Corporate Profitability: Evidence From IndiaHargobind CoachNo ratings yet
- Correlation and LinearDocument27 pagesCorrelation and LinearAdinaan ShaafiiNo ratings yet
- AN20221226 862 RevisedDocument19 pagesAN20221226 862 RevisedKainat NasirNo ratings yet
- Effects of Discipline Management On Employee Performance in An Organization: The Case of County Education Office Human Resource Department, Turkana CountyDocument18 pagesEffects of Discipline Management On Employee Performance in An Organization: The Case of County Education Office Human Resource Department, Turkana CountyCoffeebay GraceNo ratings yet
- Multinomial Logit ModelsDocument6 pagesMultinomial Logit ModelsRicardo Campos EspinozaNo ratings yet
- Machine Learning Methods To Weather Forecasting To Predict Apparent TemperatureDocument11 pagesMachine Learning Methods To Weather Forecasting To Predict Apparent TemperatureIJRASETPublications100% (1)
- ID Dampak Teknologi Modern Terhadap Kearifan Lokal Budaya Batobo Di Desa Air TirisDocument13 pagesID Dampak Teknologi Modern Terhadap Kearifan Lokal Budaya Batobo Di Desa Air TirisRiyan Pratama AndallasNo ratings yet
- Cambridge University Letter On AS LevelsDocument3 pagesCambridge University Letter On AS LevelsKevin Brennan MPNo ratings yet
- AI-GEOSTATS - The Central Information Server For Geostatistics and Spatial STDocument13 pagesAI-GEOSTATS - The Central Information Server For Geostatistics and Spatial STCatherine MunroNo ratings yet
- Cost behavior graphs and analysisDocument3 pagesCost behavior graphs and analysisRidho FitriantoNo ratings yet