You might also like
- Instructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYFrom EverandInstructor's Manual to Accompany CALCULUS WITH ANALYTIC GEOMETRYNo ratings yet
- CISC Steel ShapetablesDocument481 pagesCISC Steel ShapetablesShreedharNo ratings yet
- Answers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesFrom EverandAnswers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesRating: 1.5 out of 5 stars1.5/5 (2)
- Math6 q2 Mod8of8 Basic Operations On Integers and Problem Solving v2Document25 pagesMath6 q2 Mod8of8 Basic Operations On Integers and Problem Solving v2olivia pollosoNo ratings yet
- Philosophy of Mind (Jenkins & Sullivan) (2012)Document199 pagesPhilosophy of Mind (Jenkins & Sullivan) (2012)Claudenicio Ferreira100% (2)
- Digital Electronics For Engineering and Diploma CoursesFrom EverandDigital Electronics For Engineering and Diploma CoursesNo ratings yet
- Chaos. Making A New Science James GleickDocument20 pagesChaos. Making A New Science James GleickmitchxpNo ratings yet
- TIMO Selection Primary 5Document2 pagesTIMO Selection Primary 5Qurniawan Agung Putra100% (5)
- Matrix Algebra Slides Class Notes V5 S010 Week 13 B Apr 8Document22 pagesMatrix Algebra Slides Class Notes V5 S010 Week 13 B Apr 8Taylor BeautrandNo ratings yet
- 1.-Definimos El Sistema Q-D y Q-D: SoluciónDocument8 pages1.-Definimos El Sistema Q-D y Q-D: SoluciónGian SanchezNo ratings yet
- Descripción Del Ejercicio 4: Estudiante ADocument2 pagesDescripción Del Ejercicio 4: Estudiante Aarley franco ruizNo ratings yet
- Jan 2015 - Mock Paper - Solution Q3-5Document5 pagesJan 2015 - Mock Paper - Solution Q3-5jimmychillsNo ratings yet
- ECON1101Document4 pagesECON1101Helen ToNo ratings yet
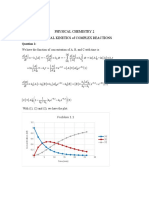
- Chem Kinetic (Complex)Document5 pagesChem Kinetic (Complex)Trung VõNo ratings yet
- Lab Report 2 - Energy and MotionDocument7 pagesLab Report 2 - Energy and MotionDawood SulemanNo ratings yet
- AssignmentDocument3 pagesAssignmentAnonymous cKV7P2magXNo ratings yet
- Quiz 11 - Section 2 #0000002539 - On May 4, 2017 15:49: ProcessingDocument3 pagesQuiz 11 - Section 2 #0000002539 - On May 4, 2017 15:49: Processingtunahan küçükerNo ratings yet
- ĐSTT bài tậpDocument7 pagesĐSTT bài tậpHoang Mai Dung K17 HLNo ratings yet
- ABCSGSGDocument114 pagesABCSGSGLordesNo ratings yet
- No 2 Soal PSD Dengan PlotDocument3 pagesNo 2 Soal PSD Dengan PlotKintania Sisca Rivana Part IINo ratings yet
- Control (1) Group Assignment No.#3: (B:) F (T) + F(S) F(S)Document8 pagesControl (1) Group Assignment No.#3: (B:) F (T) + F(S) F(S)Elzubair EljaaliNo ratings yet
- Algebra LinealDocument3 pagesAlgebra LinealPAU' GALVIZNo ratings yet
- Andini Tugas Aljabar 2022010003Document3 pagesAndini Tugas Aljabar 2022010003Andini tri Yulistiya04No ratings yet
- 7Document2 pages7juwa12588No ratings yet
- Tugas MekanikaDocument12 pagesTugas MekanikaGalang DargiNo ratings yet
- SodapdfDocument23 pagesSodapdfhamzaijazpythonNo ratings yet
- Homwork On Chapter 3Document6 pagesHomwork On Chapter 3معدات مواقع انشائيهNo ratings yet
- Chapter 1: Matrices and Matrix Operations.: DefinitionsDocument7 pagesChapter 1: Matrices and Matrix Operations.: DefinitionsAmirul SyahidinNo ratings yet
- Structural Analysis FEA AnalysisDocument19 pagesStructural Analysis FEA AnalysiseleonorNo ratings yet
- Essel Kofi Fosu - 3583418 - Comp Eng 3Document9 pagesEssel Kofi Fosu - 3583418 - Comp Eng 3Reagan TorbiNo ratings yet
- Digital Logic AssignmentDocument20 pagesDigital Logic AssignmentBikram TuladharNo ratings yet
- 10.1201 9780203491997-7 PDFDocument2 pages10.1201 9780203491997-7 PDFWilson NaranjoNo ratings yet
- 10.1201 9780203491997-7 PDFDocument2 pages10.1201 9780203491997-7 PDFWilson NaranjoNo ratings yet
- Continuum Mechanics and PlasticityDocument2 pagesContinuum Mechanics and PlasticityWilson NaranjoNo ratings yet
- System of CirclesDocument3 pagesSystem of CirclesKarthik BingiNo ratings yet
- A A A A A A A A: A Matrix Is A Rectangular Array of Elements (Scalars) From A Field. The Size of A MatrixDocument18 pagesA A A A A A A A: A Matrix Is A Rectangular Array of Elements (Scalars) From A Field. The Size of A Matrixغيث منعمNo ratings yet
- FormulasDocument3 pagesFormulasgeorgebuhay_666No ratings yet
- 1 Level:: 2.1 Material PropertiesDocument4 pages1 Level:: 2.1 Material PropertiesMai CồNo ratings yet
- Differential and Integrated Rate Laws: K DT D (A) DT K D (A) DT K D (A) T K (A) - (A) (T) T K (A) (A) (T)Document6 pagesDifferential and Integrated Rate Laws: K DT D (A) DT K D (A) DT K D (A) T K (A) - (A) (T) T K (A) (A) (T)Mahmoud AyadNo ratings yet
- Pe TT01 Group05Document34 pagesPe TT01 Group05nguyenleducphat1306No ratings yet
- Victor SolverDocument15 pagesVictor SolverAnonymous UaUr6mVwJNo ratings yet
- W41-T Class ExerciseDocument3 pagesW41-T Class Exercisevilinorgelive.noNo ratings yet
- 3-Creating Arrays - For Students - Mid TermDocument36 pages3-Creating Arrays - For Students - Mid TermMuhammad RashidNo ratings yet
- Solution1 VaDocument4 pagesSolution1 VamarshadjaferNo ratings yet
- SE - 2010 Question Paper SetDocument687 pagesSE - 2010 Question Paper SetBhargava S Padmashali100% (1)
- A A M WMC C 1) A WMC WMC A M Ma Mca Ma Mca Ma Ma Mca Mca Ma A WMC M + ( 2 M + MC WMC) A MC+ Ma) A M MC) A MC 2 M WMC) A MDocument4 pagesA A M WMC C 1) A WMC WMC A M Ma Mca Ma Mca Ma Ma Mca Mca Ma A WMC M + ( 2 M + MC WMC) A MC+ Ma) A M MC) A MC 2 M WMC) A Mtahirtp02No ratings yet
- Pattern Recognition: Fisher's Discriminant AnalysisDocument37 pagesPattern Recognition: Fisher's Discriminant AnalysisArunima DoluiNo ratings yet
- Aporte 1Document6 pagesAporte 1Vladimir Rivera BarreraNo ratings yet
- Two-Dimensional ArrayDocument6 pagesTwo-Dimensional ArrayJezzamine GomezNo ratings yet
- Matrices DPPDocument3 pagesMatrices DPPNitisha GuptaNo ratings yet
- Fem ReviewDocument31 pagesFem Reviewnuuheila.hjNo ratings yet
- Ex 2024Document7 pagesEx 2024nuuheila.hjNo ratings yet
- EE210 S22 LecSlides 12 2ppDocument18 pagesEE210 S22 LecSlides 12 2ppMarcel HuberNo ratings yet
- SolutionsDocument15 pagesSolutionsjayangceNo ratings yet
- Midterm Questions SL 123Document5 pagesMidterm Questions SL 123tumblrtia101No ratings yet
- Applications of DerivativesDocument26 pagesApplications of Derivativesomkar kale techanicalNo ratings yet
- Tutorial Chapter 6Document1 pageTutorial Chapter 6Ee Hong BinNo ratings yet
- Avance Fundamental 2 CODocument3 pagesAvance Fundamental 2 COSerna ReynaNo ratings yet
- 2022 - Ms p2 - (A'level - Statistics) - MR Share and Tuks. (t.1 2 Testing) - 1Document23 pages2022 - Ms p2 - (A'level - Statistics) - MR Share and Tuks. (t.1 2 Testing) - 1rudomposiNo ratings yet
- Equivalent Moment of InertiaDocument12 pagesEquivalent Moment of InertiaYasiru KaluarachchiNo ratings yet
- Sistema de Ecuaciones en DiferenciaDocument3 pagesSistema de Ecuaciones en Diferenciawilson QuispeNo ratings yet
- Assignment 2Document7 pagesAssignment 2sanaullah sanyNo ratings yet
- DSA MK Lect7 PDFDocument77 pagesDSA MK Lect7 PDFAnkit PriyarupNo ratings yet
- Greedy Methods: Manoj Kumar DTU, DelhiDocument44 pagesGreedy Methods: Manoj Kumar DTU, DelhiAnkit PriyarupNo ratings yet
- Red-Black Tree: Manoj Kumar DTU, DelhiDocument56 pagesRed-Black Tree: Manoj Kumar DTU, DelhiAnkit PriyarupNo ratings yet
- DSA MK Lect4 PDFDocument73 pagesDSA MK Lect4 PDFAnkit PriyarupNo ratings yet
- DSA MK Lect2 PDFDocument92 pagesDSA MK Lect2 PDFAnkit PriyarupNo ratings yet
- Binomial Heaps: Manoj Kumar DTU, DelhiDocument36 pagesBinomial Heaps: Manoj Kumar DTU, DelhiAnkit PriyarupNo ratings yet
- DSA MK Lect3 PDFDocument75 pagesDSA MK Lect3 PDFAnkit PriyarupNo ratings yet
- The Complete Sonniss Catalog - 2016.CsvDocument29 pagesThe Complete Sonniss Catalog - 2016.CsvAnkit PriyarupNo ratings yet
- SEDocument197 pagesSEAnkit PriyarupNo ratings yet
- Graphs Topological Sort Single Source Shortest Path: Manoj Kumar DTU, DelhiDocument25 pagesGraphs Topological Sort Single Source Shortest Path: Manoj Kumar DTU, DelhiAnkit PriyarupNo ratings yet
- Monsters Tournament ChallengeDocument3 pagesMonsters Tournament ChallengeAnkit PriyarupNo ratings yet
- Monsters Tournament Challenge InfoDocument3 pagesMonsters Tournament Challenge InfoAnkit PriyarupNo ratings yet
- Advertising Appeal and Tone - Implications For Creative Strategy in TV CommercialsDocument16 pagesAdvertising Appeal and Tone - Implications For Creative Strategy in TV CommercialsCapitan SwankNo ratings yet
- Mechanics of Tooth Movement: or SmithDocument14 pagesMechanics of Tooth Movement: or SmithRamesh SakthyNo ratings yet
- (Semantic) - Word, Meaning and ConceptDocument13 pages(Semantic) - Word, Meaning and ConceptIan NugrahaNo ratings yet
- TMPG PPT Course Unit AssignmentDocument2 pagesTMPG PPT Course Unit AssignmentJusteen BalcortaNo ratings yet
- The Use of Gis in The Morphometrical of Ceahlau Mountain AnalysisDocument2 pagesThe Use of Gis in The Morphometrical of Ceahlau Mountain AnalysisLaurentiu Badescu100% (1)
- Data Analytics Kit 601Document2 pagesData Analytics Kit 601Mayank GuptaNo ratings yet
- Seismic Shear Strength of Columns With Interlocking Spiral Reinforcement Gianmario BenzoniDocument8 pagesSeismic Shear Strength of Columns With Interlocking Spiral Reinforcement Gianmario Benzonijuho jungNo ratings yet
- Intro To Modeling (CMM)Document36 pagesIntro To Modeling (CMM)api-3773589No ratings yet
- Array QuestionsDocument4 pagesArray QuestionsmazlinaNo ratings yet
- SVM Exam Paper For ABA Course To Be Returned With Answers Excel Exercise (25 Marks)Document12 pagesSVM Exam Paper For ABA Course To Be Returned With Answers Excel Exercise (25 Marks)Nabeel MohammadNo ratings yet
- Unit I PDFDocument32 pagesUnit I PDFmenaka67% (3)
- Engineering Economy 3Document37 pagesEngineering Economy 3Steven SengNo ratings yet
- HANAtization Checklist v1.0Document14 pagesHANAtization Checklist v1.0topankajsharmaNo ratings yet
- Stability Analysis Using MatlabDocument1 pageStability Analysis Using MatlabcdasNo ratings yet
- Queen's University Belfast: Phy3012 Solid State PhysicsDocument131 pagesQueen's University Belfast: Phy3012 Solid State PhysicsOğuz Alp KurucuNo ratings yet
- Year 6Document53 pagesYear 6Baiat FinutzNo ratings yet
- MODULE 3 and 4Document6 pagesMODULE 3 and 4Jellene Jem RonarioNo ratings yet
- Gaussian Beams 2019Document31 pagesGaussian Beams 2019Eduardo Casas MartínezNo ratings yet
- Ch-1 Measurement (Complete)Document13 pagesCh-1 Measurement (Complete)Mahendra ModiNo ratings yet
- Deterministic and Probabilistic Liquefac PDFDocument6 pagesDeterministic and Probabilistic Liquefac PDFFarras Puti DzakirahNo ratings yet
- Simple Braced Non-SwayDocument23 pagesSimple Braced Non-SwaydineshNo ratings yet
- Sum of Series PDFDocument4 pagesSum of Series PDFmgazimaziNo ratings yet
- (Loría y Salas, 2012) Crucial Exchange Rate Parity. Evidence For MexicoDocument12 pages(Loría y Salas, 2012) Crucial Exchange Rate Parity. Evidence For Mexicobilly jimenezNo ratings yet
- XRIO User ManualDocument38 pagesXRIO User ManualicovinyNo ratings yet
- Tu 5 Mechanics PDFDocument4 pagesTu 5 Mechanics PDFJyotish VudikavalasaNo ratings yet