You might also like
- MIT18 05S14 ps9 Solutions PDFDocument5 pagesMIT18 05S14 ps9 Solutions PDFMd CassimNo ratings yet
- Population Mean (Known Variance)Document5 pagesPopulation Mean (Known Variance)Aditya MishraNo ratings yet
- Homework 12 Solution Key InsightsDocument9 pagesHomework 12 Solution Key InsightsLoy NasNo ratings yet
- Sample Applied Statistics and Probability For EngineersDocument7 pagesSample Applied Statistics and Probability For EngineersALBERT DAODANo ratings yet
- Confidence Intervals (WithSolutions)Document24 pagesConfidence Intervals (WithSolutions)Martina ManginiNo ratings yet
- 728HW2 GodkinDocument3 pages728HW2 GodkinAhsen KamalNo ratings yet
- MAT2379 - Assignment #4 SolutionsDocument3 pagesMAT2379 - Assignment #4 SolutionsAshNo ratings yet
- Chapter 8 EstimationDocument4 pagesChapter 8 EstimationĐạt TôNo ratings yet
- CH 06 SolutionsDocument8 pagesCH 06 SolutionsS.L.L.CNo ratings yet
- Homework 8 SolutionDocument7 pagesHomework 8 SolutionTACN-2T?-19ACN Nguyen Dieu Huong LyNo ratings yet
- Statistics Assignment PDFDocument3 pagesStatistics Assignment PDFpawir97576No ratings yet
- Sociology 592 - Research Statistics I Exam 1 Answer Key - DRAFT September 24, 2004Document8 pagesSociology 592 - Research Statistics I Exam 1 Answer Key - DRAFT September 24, 2004stephen562001No ratings yet
- Practice Set 3 SolutionsDocument2 pagesPractice Set 3 SolutionsRoopsi GargNo ratings yet
- CS 3341 HW SolutionsDocument3 pagesCS 3341 HW Solutionso3428No ratings yet
- Chapter 4 L1 L2Document7 pagesChapter 4 L1 L2SeMi NazarenoNo ratings yet
- Let,, ., Be A Random Sample From ( ,) - Construct A (1) Confidence Interval ForDocument5 pagesLet,, ., Be A Random Sample From ( ,) - Construct A (1) Confidence Interval ForRayan H BarwariNo ratings yet
- Confidence Interval For Variance (Problems)Document13 pagesConfidence Interval For Variance (Problems)utkucam2No ratings yet
- ConfIint (Problems)Document9 pagesConfIint (Problems)utkucam2No ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Fstats ch2 PDFDocument0 pagesFstats ch2 PDFsound05No ratings yet
- Running Head: Problem Solving AssignmentDocument11 pagesRunning Head: Problem Solving AssignmentKashémNo ratings yet
- Goal:: Estimation of ParametersDocument7 pagesGoal:: Estimation of ParametersJasper GabrielNo ratings yet
- Survey Reveals Awareness of Legislator's Abortion Funding PositionDocument3 pagesSurvey Reveals Awareness of Legislator's Abortion Funding PositionÁngel Enrique Cabarcas MendozaNo ratings yet
- KK MathDocument13 pagesKK Mathm-3977431No ratings yet
- Exercises Lecture 5 Including SolutionsDocument3 pagesExercises Lecture 5 Including SolutionsAsad ShahbazNo ratings yet
- Stat Handout 2Document11 pagesStat Handout 2cmacblue42No ratings yet
- Chem 206 Lab ManualDocument69 pagesChem 206 Lab ManualDouglas DlutzNo ratings yet
- Tugas Kuliah StatistikaDocument4 pagesTugas Kuliah StatistikaCEOAmsyaNo ratings yet
- Fstats ch2 PDFDocument16 pagesFstats ch2 PDFSachin DhimanNo ratings yet
- Confidence Intervals for Means and ProportionsDocument8 pagesConfidence Intervals for Means and ProportionsSiu Lung HongNo ratings yet
- Assignment02 - 60162020005 - Daud Wahyu Imani - Tugas Uji HipotesisDocument27 pagesAssignment02 - 60162020005 - Daud Wahyu Imani - Tugas Uji HipotesisDaud WahyuNo ratings yet
- 39 2 Norm Approx Bin PDFDocument8 pages39 2 Norm Approx Bin PDFsound05No ratings yet
- Sunil Testing HypothesisDocument39 pagesSunil Testing Hypothesisprayag DasNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Point Estimate vs Confidence IntervalDocument41 pagesPoint Estimate vs Confidence IntervalArslan ArshadNo ratings yet
- A Review of Basic Statistical Concepts: Answers To Problems and Cases 1Document227 pagesA Review of Basic Statistical Concepts: Answers To Problems and Cases 1Thiên BìnhNo ratings yet
- Original PDFDocument6 pagesOriginal PDFjoshuaNo ratings yet
- Lecture 5: Statistical Inference by Dr. Javed IqbalDocument4 pagesLecture 5: Statistical Inference by Dr. Javed IqbalHamna AghaNo ratings yet
- Ie208 QuestionsDocument8 pagesIe208 QuestionsEren GüngörNo ratings yet
- Uncertainties From LABBOOK2022Document4 pagesUncertainties From LABBOOK2022katethekat2.0No ratings yet
- Selected Problem Solutions from Chapter 8 on Confidence Intervals and Tolerance IntervalsDocument6 pagesSelected Problem Solutions from Chapter 8 on Confidence Intervals and Tolerance IntervalsSergio A. Florez BNo ratings yet
- OC3140 HW/Lab 7 Estimation: of METOC Mean and VariabilityDocument4 pagesOC3140 HW/Lab 7 Estimation: of METOC Mean and VariabilityStevy CahyaNo ratings yet
- Contol of QuairyststaeDocument2 pagesContol of Quairyststaeaskazy007No ratings yet
- Handout 4 - Statistical IntervalDocument13 pagesHandout 4 - Statistical Intervalabrilapollo.siaNo ratings yet
- MAT 540 Statistical Concepts For ResearchDocument24 pagesMAT 540 Statistical Concepts For Researchnequwan79No ratings yet
- Aplikasi Statistika & Probabilitas - GroupA - Ade Klarissa MartantiDocument17 pagesAplikasi Statistika & Probabilitas - GroupA - Ade Klarissa MartantiMartanti Aji PangestuNo ratings yet
- Design and Analysis of ExperimentsDocument12 pagesDesign and Analysis of Experimentsnilesh291No ratings yet
- Lesson Note Unit 8Document5 pagesLesson Note Unit 8ye yeNo ratings yet
- Calcium concentration confidence intervalDocument6 pagesCalcium concentration confidence intervalSatria PanduNo ratings yet
- Estimating Population Mean When σ is Unknown LESSON PLANDocument3 pagesEstimating Population Mean When σ is Unknown LESSON PLANMichael Manipon Segundo100% (2)
- STAT 2300 Exam 2 Confidence Intervals and Hypothesis TestsDocument14 pagesSTAT 2300 Exam 2 Confidence Intervals and Hypothesis TestsMohammad MazenNo ratings yet
- SQC 7001 Assignment 1Document3 pagesSQC 7001 Assignment 1YAMUNAAH A/P KRISHNANMURTYNo ratings yet
- Math Lesson 2 C2 and Mini Task 2Document4 pagesMath Lesson 2 C2 and Mini Task 2Philip AmelingNo ratings yet
- (Solutions Manual) Applied Statistics and Probability For Engineers 3rd Ed. Douglas C Montgomery, George C. Runger - Solutions by Chapter - Solutions by Chapter - ch8Document32 pages(Solutions Manual) Applied Statistics and Probability For Engineers 3rd Ed. Douglas C Montgomery, George C. Runger - Solutions by Chapter - Solutions by Chapter - ch8Nithya Sethuganapathy100% (3)
- ClassyFish's Clinical Chemistry Quality ControlDocument3 pagesClassyFish's Clinical Chemistry Quality ControlDIEGO RAFAEL ESPIRITUNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- FULLTEXT01Document45 pagesFULLTEXT01IslamSharafNo ratings yet
- Productivity Improvement of A Special Purpose MachineDocument14 pagesProductivity Improvement of A Special Purpose MachineIslamSharafNo ratings yet
- Applying Six Sigma To The ManagementDocument20 pagesApplying Six Sigma To The ManagementIslamSharafNo ratings yet
- A026201011 PDFDocument11 pagesA026201011 PDFPavithran KrishnanNo ratings yet
- Bab Ice Anu 2006Document21 pagesBab Ice Anu 2006IslamSharafNo ratings yet
- Prioritizing Improvement Projects Baenfits and Effort AnalysisiDocument1 pagePrioritizing Improvement Projects Baenfits and Effort AnalysisiIslamSharafNo ratings yet
- Bao Zhen Qiang 2007Document6 pagesBao Zhen Qiang 2007IslamSharafNo ratings yet
- Cycle Time Improvement by A Six Sigma Project For The Increase of NewDocument15 pagesCycle Time Improvement by A Six Sigma Project For The Increase of NewIslamSharafNo ratings yet
- A Framework For The Selection of Six Sigma ProjectsDocument22 pagesA Framework For The Selection of Six Sigma ProjectsIslamSharafNo ratings yet
- Cost-Based Process Weights ForDocument15 pagesCost-Based Process Weights ForIslamSharafNo ratings yet
- A Mirian 2017Document22 pagesA Mirian 2017IslamSharafNo ratings yet
- Bingl I 2006Document5 pagesBingl I 2006IslamSharafNo ratings yet
- RTY Based Model For Organizational Perfor, Ance MeasurementDocument4 pagesRTY Based Model For Organizational Perfor, Ance MeasurementIslamSharafNo ratings yet
- Ass A Rza Degan 2017Document31 pagesAss A Rza Degan 2017IslamSharafNo ratings yet
- A Mirian 2018Document16 pagesA Mirian 2018IslamSharafNo ratings yet
- Chapter 3 Game Theory: 1.2 Definitions and Theories of Game Theory 1.3 Introduction To Software 1.4 ApplicationsDocument112 pagesChapter 3 Game Theory: 1.2 Definitions and Theories of Game Theory 1.3 Introduction To Software 1.4 ApplicationsIslamSharafNo ratings yet
- Decision Analysis and Decision Making: Instructor: Haiyan Xu (徐海燕) Email: xuhaiyan@nuaa.edu.cnDocument65 pagesDecision Analysis and Decision Making: Instructor: Haiyan Xu (徐海燕) Email: xuhaiyan@nuaa.edu.cnIslamSharafNo ratings yet
- Efficiency of International Business Undergraduate Education in NUAADocument24 pagesEfficiency of International Business Undergraduate Education in NUAAIslamSharafNo ratings yet
- Introduction To Data Envelopment Analysis (DEA)Document20 pagesIntroduction To Data Envelopment Analysis (DEA)IslamSharafNo ratings yet
- Introduction To Data Envelopment Analysis (DEA)Document60 pagesIntroduction To Data Envelopment Analysis (DEA)IslamSharafNo ratings yet
- DeapDocument50 pagesDeapJoseph Vásquez LoayzaNo ratings yet
- Evaluating Importance of Critical Success Factors in Successful Implementation of Lean Six Sigma Framework 2019)Document10 pagesEvaluating Importance of Critical Success Factors in Successful Implementation of Lean Six Sigma Framework 2019)IslamSharafNo ratings yet
- Multiple Criteria Decision Analysis (MCDA)Document51 pagesMultiple Criteria Decision Analysis (MCDA)IslamSharafNo ratings yet
- DA Exercise 1 2018Document5 pagesDA Exercise 1 2018IslamSharafNo ratings yet
- 22-Cost of QualityDocument18 pages22-Cost of QualityIslamSharafNo ratings yet
- 4-The Effect of 1 Sigma Jump in Apparel ManufacturingDocument6 pages4-The Effect of 1 Sigma Jump in Apparel ManufacturingIslamSharafNo ratings yet
- 5-Investigating The Relationship Between Quality and Cost of Quality in A Wholesale CompanyDocument13 pages5-Investigating The Relationship Between Quality and Cost of Quality in A Wholesale CompanyIslamSharafNo ratings yet
- 24-A Research of Trade of Relation With in Quality CostDocument12 pages24-A Research of Trade of Relation With in Quality CostIslamSharafNo ratings yet
- 17-Improving The Definition of Quanification of Quality CostDocument18 pages17-Improving The Definition of Quanification of Quality CostIslamSharafNo ratings yet
- 23-A Research On Measurement of Quality Cost in Turkey IndustriesDocument17 pages23-A Research On Measurement of Quality Cost in Turkey IndustriesIslamSharafNo ratings yet
- Solution Manual For A Second Course in Statistics Regression Analysis 8th Edition William Mendenhall Terry T SincichDocument34 pagesSolution Manual For A Second Course in Statistics Regression Analysis 8th Edition William Mendenhall Terry T SincichEricOrtegaizna100% (39)
- Basic Concepts of EstimationDocument17 pagesBasic Concepts of EstimationChristine Angel Dagsangan100% (1)
- ARDL Model Econometric AnalysisDocument2 pagesARDL Model Econometric AnalysisAsia ButtNo ratings yet
- Practice Questions - Multiple Linear RegressionDocument44 pagesPractice Questions - Multiple Linear Regressionmanish100% (7)
- How To Apply Panel ARDL Using EVIEWSDocument4 pagesHow To Apply Panel ARDL Using EVIEWSecobalas7100% (3)
- Curve FittingDocument43 pagesCurve Fittinglisna100% (1)
- Chapter10 HeteroskedasticityDocument44 pagesChapter10 HeteroskedasticityZiaNaPiramLi100% (1)
- OLS Estimation and Monte Carlo Simulation: Introductory Notes and CommentsDocument38 pagesOLS Estimation and Monte Carlo Simulation: Introductory Notes and CommentsTHINH LYNo ratings yet
- Statistics with Economics and Business Applications: Large-Sample Estimation of Means and ProportionsDocument31 pagesStatistics with Economics and Business Applications: Large-Sample Estimation of Means and ProportionsErlin SriwantiNo ratings yet
- Chapter 4. Gauss-Markov ModelDocument20 pagesChapter 4. Gauss-Markov ModelHông HoaNo ratings yet
- Design Analys Sample SurveyDocument13 pagesDesign Analys Sample SurveyEPAH SIRENGO100% (1)
- Panel Data Lecture RomeDocument47 pagesPanel Data Lecture RomeAndri_Ahmad_Na_5590No ratings yet
- Optimal Ridge Bias Selection for Linear RegressionDocument6 pagesOptimal Ridge Bias Selection for Linear RegressionAyesha ShahbazNo ratings yet
- Tut 5Document4 pagesTut 5gagandeepsinghgxdNo ratings yet
- Regresion Lineal Simple PDFDocument16 pagesRegresion Lineal Simple PDFCristian Diaz100% (1)
- Regression Analysis ExplainedDocument28 pagesRegression Analysis ExplainedRobin GuptaNo ratings yet
- Estimating R 2 Shrinkage in RegressionDocument6 pagesEstimating R 2 Shrinkage in RegressionInternational Jpurnal Of Technical Research And ApplicationsNo ratings yet
- Final Predictive Vaibhav 2020Document101 pagesFinal Predictive Vaibhav 2020sristi agrawalNo ratings yet
- 2019 48 Jan 2020 Core Course Elective BBADocument7 pages2019 48 Jan 2020 Core Course Elective BBAKhizar NiazNo ratings yet
- SPSS Uji TabletDocument17 pagesSPSS Uji TabletAdrianNo ratings yet
- National University of Modern Languages Lahore Campus TopicDocument5 pagesNational University of Modern Languages Lahore Campus Topicmuhammad ahmadNo ratings yet
- Lecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Document3 pagesLecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Amelia TranNo ratings yet
- Callaway & SantAnnaDocument31 pagesCallaway & SantAnnaVictor Maury SallucaNo ratings yet
- Analysis For Power System State EstimationDocument9 pagesAnalysis For Power System State EstimationAnonymous TJRX7CNo ratings yet
- Ekotrik KordouglassDocument6 pagesEkotrik KordouglassRauzah AmaliaNo ratings yet
- IT0089 (Fundamentals of Analytics Modeling) : ExerciseDocument6 pagesIT0089 (Fundamentals of Analytics Modeling) : ExerciseAshley De JesusNo ratings yet
- Chapter 1. Introduction and Review of Univariate General Linear ModelsDocument25 pagesChapter 1. Introduction and Review of Univariate General Linear Modelsemjay emjayNo ratings yet
- How Does An Outlier Affect The Least SquaresDocument12 pagesHow Does An Outlier Affect The Least SquaresDivit RajputNo ratings yet
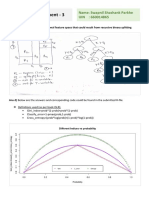
- IDS 575 Assignment - 3: Name: Swapnil Shashank Parkhe UIN: 660014865Document7 pagesIDS 575 Assignment - 3: Name: Swapnil Shashank Parkhe UIN: 660014865Swapnil ParkheNo ratings yet