You might also like
- Finding Your Roots: The Official Companion to the PBS SeriesFrom EverandFinding Your Roots: The Official Companion to the PBS SeriesRating: 5 out of 5 stars5/5 (1)
- Long Etal 2009Document12 pagesLong Etal 2009stephenc144No ratings yet
- Mitochondrial Diversity in Amerindian Kichwa and Mestizo Populations From EcuadorDocument4 pagesMitochondrial Diversity in Amerindian Kichwa and Mestizo Populations From EcuadorjohnkalespiNo ratings yet
- Aryan Invasion Debunking Part - 1 - Genetics - and - Anthropology1Document43 pagesAryan Invasion Debunking Part - 1 - Genetics - and - Anthropology1Aditya SinghNo ratings yet
- Y ChromosomeDocument33 pagesY Chromosomeifrahkhalid52No ratings yet
- Bryc, K. & Al. 2015. "The Genetic Ancestry of African Americans, Latinos, and European Americans Across The United States"Document17 pagesBryc, K. & Al. 2015. "The Genetic Ancestry of African Americans, Latinos, and European Americans Across The United States"YmeNo ratings yet
- TMP B1 DEDocument11 pagesTMP B1 DEFrontiersNo ratings yet
- 1 s2.0 S0888754310001552 Main PDFDocument12 pages1 s2.0 S0888754310001552 Main PDFAnonymous sF4FmENo ratings yet
- Evaluating The X Chromosome-Specific Diversity of Colombian Populations Using Insertion/Deletion PolymorphismsDocument10 pagesEvaluating The X Chromosome-Specific Diversity of Colombian Populations Using Insertion/Deletion PolymorphismsAdrianaAlexandraIbarraRodríguezNo ratings yet
- Mexico City AncestryDocument32 pagesMexico City AncestrylpyotsubaNo ratings yet
- Y-Chromosome Biallelic Polymorphisms and Native American Population StructureDocument5 pagesY-Chromosome Biallelic Polymorphisms and Native American Population StructureMar CeloNo ratings yet
- Physical Anthropology and Ethnicity in Asia: The Transition From Anthropometry To Genome-Based StudiesDocument6 pagesPhysical Anthropology and Ethnicity in Asia: The Transition From Anthropometry To Genome-Based StudiesJan KowalskiNo ratings yet
- Final Draft Anth 790Document11 pagesFinal Draft Anth 790inqu1ryNo ratings yet
- Complete Week 2 Assignment Correction With in Text CitationDocument7 pagesComplete Week 2 Assignment Correction With in Text CitationRhonda ReedNo ratings yet
- SNPforID 52plex-2013Document7 pagesSNPforID 52plex-2013AdrianaAlexandraIbarraRodríguezNo ratings yet
- Cavalli-Sforza Et Al 1988 Reconstruction of Human Evolution - Bringing Together Genetic, Archaeological, and Linguistic Data PDFDocument6 pagesCavalli-Sforza Et Al 1988 Reconstruction of Human Evolution - Bringing Together Genetic, Archaeological, and Linguistic Data PDF赵权No ratings yet
- Autosomal, MtDNA, and Y-Chromosome Diversity in Amerinds - Pre - and Post-Columbian Patterns of Gene Flow in South America - Mesa 2000Document10 pagesAutosomal, MtDNA, and Y-Chromosome Diversity in Amerinds - Pre - and Post-Columbian Patterns of Gene Flow in South America - Mesa 2000spanishvcuNo ratings yet
- 50 Great Myths of Human Evolution: Understanding Misconceptions about Our OriginsFrom Everand50 Great Myths of Human Evolution: Understanding Misconceptions about Our OriginsNo ratings yet
- Ethnicity and Human Genetic Linkage MapsDocument15 pagesEthnicity and Human Genetic Linkage Mapsnindy kadirNo ratings yet
- Felkl et al, 2023. Ancestry resolution of South Brazilians by forensic 165 ancestry-informative SNPs panelDocument9 pagesFelkl et al, 2023. Ancestry resolution of South Brazilians by forensic 165 ancestry-informative SNPs panelAlineNo ratings yet
- Permanent Markers: Race, Ancestry, and the Body after the GenomeFrom EverandPermanent Markers: Race, Ancestry, and the Body after the GenomeNo ratings yet
- Dogs & Wolves Have A Shorter Genetic Distance Between Each Other Than Negroids & Non-Negroids.Document7 pagesDogs & Wolves Have A Shorter Genetic Distance Between Each Other Than Negroids & Non-Negroids.Race-Realist67% (3)
- T H G P: HE Uman Enome RojectDocument28 pagesT H G P: HE Uman Enome RojectUpendra Sharma Sulibele100% (1)
- Mind Maps Iin FixDocument16 pagesMind Maps Iin FixIndri RahmawatiNo ratings yet
- Grade 12 - Ls - Source Booklet - Part B - Case Study - 8 Feb 2024Document9 pagesGrade 12 - Ls - Source Booklet - Part B - Case Study - 8 Feb 2024Heinricht FourieNo ratings yet
- DNA Fingerprint Statistical AnalysisDocument4 pagesDNA Fingerprint Statistical AnalysisLauKingWeiNo ratings yet
- Classifying HumansDocument2 pagesClassifying HumansAnonymous uliBzsZrWNo ratings yet
- DNA barcodes identify mayfly speciesDocument17 pagesDNA barcodes identify mayfly speciesAdirfan PratomoNo ratings yet
- Genomics and Its Impact On Science and Society:: The Human Genome Project and BeyondDocument22 pagesGenomics and Its Impact On Science and Society:: The Human Genome Project and Beyondcm40% (1)
- The Human Genome ProjectDocument22 pagesThe Human Genome ProjectAashianaThiyam100% (1)
- Race and Genetics - Wiki..., The Free EncyclopediaDocument16 pagesRace and Genetics - Wiki..., The Free EncyclopediaLakshmiPriyaNo ratings yet
- Genetic evidence for two founding populations of the AmericasDocument17 pagesGenetic evidence for two founding populations of the AmericasArturo Salvador Canseco NavaNo ratings yet
- Genomics - 2023 - TaggedDocument59 pagesGenomics - 2023 - TaggedRitwik DasNo ratings yet
- Reduced Genetic Structure of the Iberian Peninsula Revealed by Y-Chromosome AnalysisDocument9 pagesReduced Genetic Structure of the Iberian Peninsula Revealed by Y-Chromosome AnalysisVolinthosNo ratings yet
- Human Genome ProjectDocument17 pagesHuman Genome Projectanon_306048523No ratings yet
- Exome Capture From SalivaDocument17 pagesExome Capture From SalivaJobin John PR15BI1001No ratings yet
- Novel North American Hominins Final PDF DownloadDocument41 pagesNovel North American Hominins Final PDF DownloadRichard Bachman100% (1)
- Genetic Variation and Population Structure - Wang Et Al 777Document19 pagesGenetic Variation and Population Structure - Wang Et Al 777Michael TipswordNo ratings yet
- G000895589 AncestrumDocument53 pagesG000895589 Ancestrumpedromarreiros84No ratings yet
- Human Genetics Describes The Study of Inheritance As It Occurs inDocument18 pagesHuman Genetics Describes The Study of Inheritance As It Occurs inMayur BhakreNo ratings yet
- The Human Genome ProjectsDocument4 pagesThe Human Genome ProjectsMurugesan PalrajNo ratings yet
- Genetic Relationship of Populations in ChinaDocument6 pagesGenetic Relationship of Populations in ChinaKien TranNo ratings yet
- Kim Et Al QuestionsDocument2 pagesKim Et Al QuestionsStephanie SmithNo ratings yet
- Black & White Deliver Card (1) - WPS OfficeDocument28 pagesBlack & White Deliver Card (1) - WPS Officelinkgogo69No ratings yet
- Project PaperDocument12 pagesProject Paperop gamerNo ratings yet
- Note Jan 30 2014Document8 pagesNote Jan 30 2014api-243334077No ratings yet
- Genome Mapping and Genomics in AnimalsDocument289 pagesGenome Mapping and Genomics in AnimalsCarmenNo ratings yet
- Evidencia Centéfica BigfootDocument24 pagesEvidencia Centéfica BigfootMarianCondeNo ratings yet
- Reconstructing NativeDocument7 pagesReconstructing NativeerikaNo ratings yet
- Human GenomeDocument8 pagesHuman GenomeKannanSubramanianNo ratings yet
- The Story of Zilphy Claud and My Family Tree.Document36 pagesThe Story of Zilphy Claud and My Family Tree.Timothy100% (3)
- Lecture 1: Introducing The Power and Scope of Genetics Learning GoalsDocument8 pagesLecture 1: Introducing The Power and Scope of Genetics Learning GoalsAngelica SmithNo ratings yet
- Human Genome ProjectDocument57 pagesHuman Genome ProjectIsma Velasco100% (1)
- Man and Animals Are 96 Percent The SameDocument86 pagesMan and Animals Are 96 Percent The Samemaqsood hasniNo ratings yet
- The Landscape of Human STR VariationDocument12 pagesThe Landscape of Human STR VariationJuliana SiruffoNo ratings yet
- Glimpses of Human Genome ProjectDocument94 pagesGlimpses of Human Genome Projectsherfudeen75% (4)
- HUMAN GENOME PROJECT: KEY MILESTONES AND FUTURE CHALLENGESDocument23 pagesHUMAN GENOME PROJECT: KEY MILESTONES AND FUTURE CHALLENGESNishant ChandavarkarNo ratings yet
- Genetic Structure, Self-Identified Race/Ethnicity, and Confounding in Case-Control Association StudiesDocument8 pagesGenetic Structure, Self-Identified Race/Ethnicity, and Confounding in Case-Control Association StudiesFadhilla SetyaNo ratings yet
- Michael Cohen's Written Testimony To HouseDocument20 pagesMichael Cohen's Written Testimony To HouseCirca NewsNo ratings yet
- Michael Cohen Plea DocumentsDocument19 pagesMichael Cohen Plea DocumentsCirca NewsNo ratings yet
- Letter of PermissionDocument9 pagesLetter of PermissionCirca NewsNo ratings yet
- Apprehension, Processing, Care, and Custody of Alien Minors and Unaccompanied Alien ChildrenDocument203 pagesApprehension, Processing, Care, and Custody of Alien Minors and Unaccompanied Alien ChildrenCirca NewsNo ratings yet
- Nicholas Rakowsky Nikitovich v. TrumpDocument10 pagesNicholas Rakowsky Nikitovich v. TrumpCirca NewsNo ratings yet
- 2018-09-05 Sangamo Announces 16 Week Clinical Results 423Document5 pages2018-09-05 Sangamo Announces 16 Week Clinical Results 423Circa NewsNo ratings yet
- Nej Mo A 1808082Document10 pagesNej Mo A 1808082Circa NewsNo ratings yet
- Jeff Sessions Resignation LetterDocument1 pageJeff Sessions Resignation LetterCNBCDigitalNo ratings yet
- 2018 IPAWS National Test Fact SheetDocument2 pages2018 IPAWS National Test Fact SheetCirca News100% (1)
- HR 302 As Amended Summary FinalDocument5 pagesHR 302 As Amended Summary FinalCirca NewsNo ratings yet
- MCD FoodJourney Timeline v25cDocument1 pageMCD FoodJourney Timeline v25cCirca NewsNo ratings yet
- BillsDocument540 pagesBillsCirca NewsNo ratings yet
- More Than 75 Percent Decline Over 27 Years in Total Flying Insect Biomass in Protected AreasDocument21 pagesMore Than 75 Percent Decline Over 27 Years in Total Flying Insect Biomass in Protected AreasCirca NewsNo ratings yet
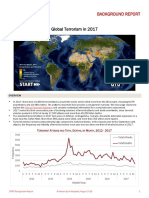
- START GTD Overview2017 July2018Document3 pagesSTART GTD Overview2017 July2018Circa NewsNo ratings yet
- Violent Threats and Incidents in SchoolsDocument16 pagesViolent Threats and Incidents in SchoolsCirca NewsNo ratings yet
- Execution LetterDocument1 pageExecution LetterCirca NewsNo ratings yet
- Store Closing ListDocument2 pagesStore Closing ListSteve HawkinsNo ratings yet
- 17-459 1o13Document43 pages17-459 1o13Circa NewsNo ratings yet
- Mollie Tibbetts Wiring InstructionsDocument1 pageMollie Tibbetts Wiring InstructionsCirca NewsNo ratings yet
- Troester v. StarbucksDocument35 pagesTroester v. StarbucksCirca NewsNo ratings yet
- Identity Theft IRS Needs To Strengthen Taxpayer Authentication EffortsDocument67 pagesIdentity Theft IRS Needs To Strengthen Taxpayer Authentication EffortsCirca NewsNo ratings yet
- Liquid Water On MarsDocument4 pagesLiquid Water On MarsCirca NewsNo ratings yet
- PJ 2017.02.09 Experiential FINALDocument41 pagesPJ 2017.02.09 Experiential FINALCirca NewsNo ratings yet
- 2018 07 02 Immigration Trend For ReleaseDocument8 pages2018 07 02 Immigration Trend For ReleaseCirca NewsNo ratings yet
- + Results Shown Reflect Responses Among Registered VotersDocument18 pages+ Results Shown Reflect Responses Among Registered VotersCirca NewsNo ratings yet
- Dating of Wines With Cesium-137: Fukushima's ImprintDocument3 pagesDating of Wines With Cesium-137: Fukushima's ImprintCirca NewsNo ratings yet
- Prep101 Consumer InfoDocument2 pagesPrep101 Consumer InfoCirca NewsNo ratings yet
- Hiv Proven Prevention Methods 508Document2 pagesHiv Proven Prevention Methods 508Circa NewsNo ratings yet
- WWW - Commonsensemedia - OrgDocument3 pagesWWW - Commonsensemedia - Orgkbeik001No ratings yet
- Baobab MenuDocument4 pagesBaobab Menuperseverence mahlamvanaNo ratings yet
- Use Visual Control So No Problems Are Hidden.: TPS Principle - 7Document8 pagesUse Visual Control So No Problems Are Hidden.: TPS Principle - 7Oscar PinillosNo ratings yet
- Ansible Playbook for BeginnersDocument101 pagesAnsible Playbook for BeginnersFelix Andres Baquero Cubillos100% (1)
- Dance Appreciation and CompositionDocument1 pageDance Appreciation and CompositionFretz Ael100% (1)
- !!!Логос - конференц10.12.21 копіяDocument141 pages!!!Логос - конференц10.12.21 копіяНаталія БондарNo ratings yet
- Steps To Christ AW November 2016 Page Spreaad PDFDocument2 pagesSteps To Christ AW November 2016 Page Spreaad PDFHampson MalekanoNo ratings yet
- Exercise-01: JEE-PhysicsDocument52 pagesExercise-01: JEE-Physicsjk rNo ratings yet
- Pemaknaan School Well-Being Pada Siswa SMP: Indigenous ResearchDocument16 pagesPemaknaan School Well-Being Pada Siswa SMP: Indigenous ResearchAri HendriawanNo ratings yet
- Certification Presently EnrolledDocument15 pagesCertification Presently EnrolledMaymay AuauNo ratings yet
- Longman ESOL Skills For Life - ShoppingDocument4 pagesLongman ESOL Skills For Life - ShoppingAstri Natalia Permatasari83% (6)
- Trillium Seismometer: User GuideDocument34 pagesTrillium Seismometer: User GuideDjibril Idé AlphaNo ratings yet
- Beauty ProductDocument12 pagesBeauty ProductSrishti SoniNo ratings yet
- United-nations-Organization-uno Solved MCQs (Set-4)Document8 pagesUnited-nations-Organization-uno Solved MCQs (Set-4)SãñÂt SûRÿá MishraNo ratings yet
- Damcos Mas2600 Installation UsermanualDocument26 pagesDamcos Mas2600 Installation Usermanualair1111No ratings yet
- Revision Worksheet - Matrices and DeterminantsDocument2 pagesRevision Worksheet - Matrices and DeterminantsAryaNo ratings yet
- Srimanta Sankaradeva Universityof Health SciencesDocument3 pagesSrimanta Sankaradeva Universityof Health SciencesTemple RunNo ratings yet
- Sinclair User 1 Apr 1982Document68 pagesSinclair User 1 Apr 1982JasonWhite99No ratings yet
- Arta Kelmendi's resume highlighting education and work experienceDocument2 pagesArta Kelmendi's resume highlighting education and work experienceArta KelmendiNo ratings yet
- Extrajudicial Settlement of Estate Rule 74, Section 1 ChecklistDocument8 pagesExtrajudicial Settlement of Estate Rule 74, Section 1 ChecklistMsyang Ann Corbo DiazNo ratings yet
- Google Earth Learning Activity Cuban Missile CrisisDocument2 pagesGoogle Earth Learning Activity Cuban Missile CrisisseankassNo ratings yet
- C4 ISRchapterDocument16 pagesC4 ISRchapterSerkan KalaycıNo ratings yet
- Lecture NotesDocument6 pagesLecture NotesRawlinsonNo ratings yet
- Form 709 United States Gift Tax ReturnDocument5 pagesForm 709 United States Gift Tax ReturnBogdan PraščevićNo ratings yet
- Mobile ApplicationDocument2 pagesMobile Applicationdarebusi1No ratings yet
- Excess AirDocument10 pagesExcess AirjkaunoNo ratings yet
- Vector 4114NS Sis TDSDocument2 pagesVector 4114NS Sis TDSCaio OliveiraNo ratings yet
- Advantages of Using Mobile ApplicationsDocument30 pagesAdvantages of Using Mobile ApplicationsGian Carlo LajarcaNo ratings yet
- Gabinete STS Activity1Document2 pagesGabinete STS Activity1Anthony GabineteNo ratings yet
- Three Comparison of Homoeopathic MedicinesDocument22 pagesThree Comparison of Homoeopathic MedicinesSayeed AhmadNo ratings yet