You might also like
- 201 - 04 - 01 - Bijma An Introduction To Mathematical Statistics 2017Document380 pages201 - 04 - 01 - Bijma An Introduction To Mathematical Statistics 2017Srinivasa100% (2)
- Chapter 5Document5 pagesChapter 5hussein mohammedNo ratings yet
- 1 Basic Geometric Intuition: For Example, See Theorems 6.3.8 and 6.3.9 in Lay's Linear Algebra Book On The SyllabusDocument3 pages1 Basic Geometric Intuition: For Example, See Theorems 6.3.8 and 6.3.9 in Lay's Linear Algebra Book On The SyllabusKadirNo ratings yet
- 統計摘要Document12 pages統計摘要harrison61704No ratings yet
- ECE 3040 Lecture 18: Curve Fitting by Least-Squares-Error RegressionDocument38 pagesECE 3040 Lecture 18: Curve Fitting by Least-Squares-Error RegressionKen ZhengNo ratings yet
- Univariate and Bivariate Data Analysis + ProbabilityDocument5 pagesUnivariate and Bivariate Data Analysis + ProbabilityBasoko_Leaks100% (1)
- Estimation of Mean Vector and Variance Covariance Matrix PDFDocument7 pagesEstimation of Mean Vector and Variance Covariance Matrix PDFMohammed AdelNo ratings yet
- Linear RegressionDocument34 pagesLinear RegressionRaksa KunNo ratings yet
- Book DownDocument17 pagesBook DownProf. Madya Dr. Umar Yusuf MadakiNo ratings yet
- L 02 HuehuehueDocument7 pagesL 02 HuehuehueVishnu SankarNo ratings yet
- Multiple Linear RegressionDocument17 pagesMultiple Linear Regressionismael kenedyNo ratings yet
- Mathematics Promotional Exam Cheat SheetDocument8 pagesMathematics Promotional Exam Cheat SheetAlan AwNo ratings yet
- Tarea 1Document6 pagesTarea 1jorge esteban guerraNo ratings yet
- L-25 Parameter EstimationDocument11 pagesL-25 Parameter EstimationAnisha GargNo ratings yet
- Chapter Seven: Solution of Pdes. by Using Finite Difference Method 7.1 Partial Differential EquationsDocument10 pagesChapter Seven: Solution of Pdes. by Using Finite Difference Method 7.1 Partial Differential EquationsMohamed MuayidNo ratings yet
- Correlation in Random VariablesDocument6 pagesCorrelation in Random VariablesMadhu Babu SikhaNo ratings yet
- Classical Multiple RegressionDocument5 pagesClassical Multiple Regression13sandipNo ratings yet
- Dif Cal - Module 2 - Limits and ContinuityDocument17 pagesDif Cal - Module 2 - Limits and ContinuityRainNo ratings yet
- CH 8Document22 pagesCH 8aju michaelNo ratings yet
- 04 LinearModelsDocument28 pages04 LinearModelsalokNo ratings yet
- Roots of EquationsDocument8 pagesRoots of EquationsrawadNo ratings yet
- E7 2021 FinalReviewDocument85 pagesE7 2021 FinalReviewkongNo ratings yet
- Lecture 29 Exponential Function - 446459516Document6 pagesLecture 29 Exponential Function - 446459516Jannatul FerdousNo ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Chapter 3Document75 pagesChapter 3Logan HooverNo ratings yet
- Minimum Variance Unbiased Estimation: ExampleDocument4 pagesMinimum Variance Unbiased Estimation: ExampleÖmer Faruk DemirNo ratings yet
- Quetions For Top Students PDFDocument2 pagesQuetions For Top Students PDFharuhi.karasunoNo ratings yet
- MathDocument8 pagesMathAalyyah C.No ratings yet
- Module 1 - Domain and RangeDocument3 pagesModule 1 - Domain and RangeSteve RogersNo ratings yet
- Unit 4Document8 pagesUnit 4Kamlesh PariharNo ratings yet
- Reliability Theory and Survival Analysis FinalDocument12 pagesReliability Theory and Survival Analysis FinalAyushi jainNo ratings yet
- Mean Absolute Deviation About Median As A Tool ofDocument7 pagesMean Absolute Deviation About Median As A Tool ofMuhammad SatriyoNo ratings yet
- Xi - Mat - Vol I & II - RRDocument57 pagesXi - Mat - Vol I & II - RRSpedNo ratings yet
- AE 5332 - Professor Dora E. Musielak: Residue Theorem and Solution of Real Indefinite IntegralsDocument12 pagesAE 5332 - Professor Dora E. Musielak: Residue Theorem and Solution of Real Indefinite IntegralsJohnNo ratings yet
- Least - Squares Approximation Print FixedDocument17 pagesLeast - Squares Approximation Print Fixedadinda salshabilla yudhaNo ratings yet
- Lecture 6. Random Variable and Its DistributionDocument7 pagesLecture 6. Random Variable and Its Distributionkatherineoden14No ratings yet
- Week 5 Lecture Q ADocument14 pagesWeek 5 Lecture Q AHuma RehmanNo ratings yet
- Differential Calculus Module 1Document9 pagesDifferential Calculus Module 1Norejun OsialNo ratings yet
- CCEA Formula SheetDocument4 pagesCCEA Formula SheetabsjonyNo ratings yet
- Neural Networks: 25 October, 2016Document44 pagesNeural Networks: 25 October, 2016Marius_2010100% (1)
- 2.1 Definition of The ProblemDocument6 pages2.1 Definition of The ProblemÖmer Faruk DemirNo ratings yet
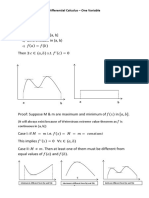
- Rolle's Theorem:: Differential Calculus - One VariableDocument7 pagesRolle's Theorem:: Differential Calculus - One VariableAnshul ModiNo ratings yet
- Common Probability Distributionsi Math 217/218 Probability and StatisticsDocument10 pagesCommon Probability Distributionsi Math 217/218 Probability and StatisticsGrace nyangasiNo ratings yet
- Statistical Inference 2 Note 02Document7 pagesStatistical Inference 2 Note 02ElelanNo ratings yet
- H2 Maths - Statistics - SummaryDocument18 pagesH2 Maths - Statistics - SummarynicNo ratings yet
- Chapter 12Document6 pagesChapter 12Asad SaeedNo ratings yet
- Gen Math Mod 3Document21 pagesGen Math Mod 3Alessandra Marie PlatonNo ratings yet
- Gradient Of A Function هّلادلا رادحنإDocument11 pagesGradient Of A Function هّلادلا رادحنإGafeer FableNo ratings yet
- A Proximal Method Solve Quasiconvex-UltimoDocument6 pagesA Proximal Method Solve Quasiconvex-UltimoArturo Morales SolanoNo ratings yet
- DPBS 1203 Business and Economic StatisticsDocument21 pagesDPBS 1203 Business and Economic StatisticsJazlyn JasaNo ratings yet
- Notes About Numerical Methods With MatlabDocument50 pagesNotes About Numerical Methods With MatlabhugocronyNo ratings yet
- 3 - Annotated Notes - Variational Principles - Wed Sept 22, 2021Document8 pages3 - Annotated Notes - Variational Principles - Wed Sept 22, 2021Luay AlmniniNo ratings yet
- Genmathweek 3Document7 pagesGenmathweek 3Ricky LumantaNo ratings yet
- GMM Estimation PDFDocument35 pagesGMM Estimation PDFdamian camargoNo ratings yet
- ECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounDocument23 pagesECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounKen ZhengNo ratings yet
- Numerical Analysis in Engineering: Taylor SeriesDocument36 pagesNumerical Analysis in Engineering: Taylor SeriesCollano M. Noel RogieNo ratings yet
- Lecture 3 - Econometria IDocument46 pagesLecture 3 - Econometria ITassio Schiavetti RossiNo ratings yet
- PDF 4Document11 pagesPDF 4shrilaxmi bhatNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Yang, Logan & Coffey, 1995 - Mathematical Formulae For Calculating The Base Temperature For Growing Degree DaysDocument14 pagesYang, Logan & Coffey, 1995 - Mathematical Formulae For Calculating The Base Temperature For Growing Degree Daysromario_ccaNo ratings yet
- Logistic Regression and Regularization: Michael (Mike) GelbartDocument19 pagesLogistic Regression and Regularization: Michael (Mike) GelbartNourheneMbarekNo ratings yet
- Summer Training ReportDocument34 pagesSummer Training ReportPråshãnt ShärmãNo ratings yet
- Simple LR LectureDocument60 pagesSimple LR LectureEarl Kristof Li LiaoNo ratings yet
- AI-900 Exam Dumps - Study PDF Link - ExamTopics - Adi - Oct2020Document55 pagesAI-900 Exam Dumps - Study PDF Link - ExamTopics - Adi - Oct2020m3aistoreNo ratings yet
- Machine LearningDocument62 pagesMachine LearningDoan Hieu100% (1)
- An Overview of Regression Analysis: Slides by Niels-Hugo Blunch Washington and Lee UniversityDocument31 pagesAn Overview of Regression Analysis: Slides by Niels-Hugo Blunch Washington and Lee UniversityLAMOUCHI RIMNo ratings yet
- Guide To Equilibrium DialysisDocument29 pagesGuide To Equilibrium DialysisHaripriya SantoshNo ratings yet
- Operation of Coal-Based Sponge Iron Rotary Kiln To Reduce Accretion Formation and Optimize Quality and Power GenerationDocument8 pagesOperation of Coal-Based Sponge Iron Rotary Kiln To Reduce Accretion Formation and Optimize Quality and Power GenerationJJNo ratings yet
- Highway NotesDocument111 pagesHighway NotesdzikrydsNo ratings yet
- A Class MTH302 MCQ's Solved by Rana Umair A KhanDocument14 pagesA Class MTH302 MCQ's Solved by Rana Umair A KhanRana Umair A Khan100% (3)
- Linear Regression Problems With SolutionDocument5 pagesLinear Regression Problems With SolutionMuhammad Naveed IkramNo ratings yet
- Chapter 3 - TestbankDocument62 pagesChapter 3 - TestbankPhan Thi Tuyet Nhung67% (3)
- A Medical Researcher Is Studying The Relationship Between Age (X Years) and VolumeDocument17 pagesA Medical Researcher Is Studying The Relationship Between Age (X Years) and VolumeHalal BoiNo ratings yet
- Pytorch Tutorial For Beginner: Department of Computer Science & Engineering University of WashingtonDocument11 pagesPytorch Tutorial For Beginner: Department of Computer Science & Engineering University of WashingtonAnon ImNo ratings yet
- Correlation Between Chinese Medicine Constitution and Skin Types: A Study On 187 Japanese WomenDocument6 pagesCorrelation Between Chinese Medicine Constitution and Skin Types: A Study On 187 Japanese Womenthichkhampha_py94No ratings yet
- Global Warming PDFDocument26 pagesGlobal Warming PDFshivam wadhwaNo ratings yet
- G David Garson GLM UNIVARIATE, ANOVA, AND ANCOVA 2013, StatisticalDocument159 pagesG David Garson GLM UNIVARIATE, ANOVA, AND ANCOVA 2013, StatisticalMohammed SoufiNo ratings yet
- The Influence of Principal Leadership and Organizational Culture On The Teachers' PerformanceDocument3 pagesThe Influence of Principal Leadership and Organizational Culture On The Teachers' PerformanceFirdausNo ratings yet
- Loop Length of Plain Single Weft Knitted Structure With ElastaneDocument11 pagesLoop Length of Plain Single Weft Knitted Structure With ElastaneNobodyNo ratings yet
- Management Science Chap15-ForecastingDocument86 pagesManagement Science Chap15-Forecastingtaylor swiftyyyNo ratings yet
- Engineering Statistics Handbook 3. Production Process CharacterizationDocument137 pagesEngineering Statistics Handbook 3. Production Process Characterizationagbas20026896No ratings yet
- (ARTIGO) PIERUCCINI-FARIA. 2021. Gait Variability Across Neurodegenerative and Cognitive DisordersDocument12 pages(ARTIGO) PIERUCCINI-FARIA. 2021. Gait Variability Across Neurodegenerative and Cognitive DisordersSaulo Eduardo RibeiroNo ratings yet
- Statistics LO1 LO4Document14 pagesStatistics LO1 LO4Omar El-TalNo ratings yet
- A Practical Method For Statistical Analysis of Strain-Life Fatigue DataDocument10 pagesA Practical Method For Statistical Analysis of Strain-Life Fatigue DatabloomdidoNo ratings yet
- Linear Regression Assumptions and Diagnostics in R - Essentials - Articles - STHDADocument21 pagesLinear Regression Assumptions and Diagnostics in R - Essentials - Articles - STHDAicen00bNo ratings yet
- Statistical Practice: Estimators of Relative Importance in Linear Regression Based On Variance DecompositionDocument9 pagesStatistical Practice: Estimators of Relative Importance in Linear Regression Based On Variance DecompositionLyly MagnanNo ratings yet
- L1.2010.GARP Practice Exam ADocument39 pagesL1.2010.GARP Practice Exam ABhabaniParidaNo ratings yet
- Econometrics II Handout For StudentsDocument29 pagesEconometrics II Handout For StudentsHABTEMARIAM ERTBANNo ratings yet