You might also like
- Supply Chain Vulnerabilities Impacting Commercial AviationFrom EverandSupply Chain Vulnerabilities Impacting Commercial AviationNo ratings yet
- REPORT On Time Flights PerformanceDocument9 pagesREPORT On Time Flights PerformanceGeorge PligoropoulosNo ratings yet
- AirlineMitigationOfPropagatedDelays PreviewDocument53 pagesAirlineMitigationOfPropagatedDelays PreviewWinston YangNo ratings yet
- Air Crash Investigations - The Crash Of Embraer 500 (N100EQ) Gaithersburg, MarylandFrom EverandAir Crash Investigations - The Crash Of Embraer 500 (N100EQ) Gaithersburg, MarylandNo ratings yet
- Flight Delays and Passenger Preferences: An Axiomatic ApproachDocument25 pagesFlight Delays and Passenger Preferences: An Axiomatic ApproachpmacastroNo ratings yet
- KrishnaBathula 1Document6 pagesKrishnaBathula 1Basit OnaopepoNo ratings yet
- Airline Crew Scheduling Under Uncertainty: Corresponding Author. Schaefer@engrng - Pitt.eduDocument31 pagesAirline Crew Scheduling Under Uncertainty: Corresponding Author. Schaefer@engrng - Pitt.edusssstanleyNo ratings yet
- Why Airlines Schedule Flights to Arrive LateDocument50 pagesWhy Airlines Schedule Flights to Arrive LateVidhi YadavNo ratings yet
- ReportDocument5 pagesReportMadhu SNo ratings yet
- Internalization of Airport Congestion: How Carriers Account for Congestion ImpactsDocument7 pagesInternalization of Airport Congestion: How Carriers Account for Congestion ImpactsHarshit SharmaNo ratings yet
- Weather PerformanceDocument6 pagesWeather PerformanceIvan DavidovicNo ratings yet
- Case Study - Flight DelayDocument8 pagesCase Study - Flight DelayHarshit AroraNo ratings yet
- ServiceCompetitionInTheAirlineIndus PreviewDocument45 pagesServiceCompetitionInTheAirlineIndus PreviewMaryrose A. DivinagraciaNo ratings yet
- Research Article: A Method of Reducing Flight Delay by Exploring Internal Mechanism of Flight DelaysDocument9 pagesResearch Article: A Method of Reducing Flight Delay by Exploring Internal Mechanism of Flight Delaysemailku 1No ratings yet
- J15 Robust Airline Scheduling Under Block-Time Uncertainty. Transportation ScienceDocument15 pagesJ15 Robust Airline Scheduling Under Block-Time Uncertainty. Transportation ScienceSTLiNo ratings yet
- Northwest Airlines Report Group No. 9Document8 pagesNorthwest Airlines Report Group No. 9Arun MundheNo ratings yet
- IMPACTS OF EXTREME WEATHER ON AVIATIONDocument15 pagesIMPACTS OF EXTREME WEATHER ON AVIATIONputri wulandariNo ratings yet
- Flight operations recovery considering passenger recoveryDocument20 pagesFlight operations recovery considering passenger recoveryAli RajaNo ratings yet
- Cause Identification From Aviation Safety Incident Reports Via Weakly Supervised Semantic Lexicon ConstructionDocument63 pagesCause Identification From Aviation Safety Incident Reports Via Weakly Supervised Semantic Lexicon Construction18rosa18No ratings yet
- Predicting Flight Delay Based On Multiple Linear RDocument8 pagesPredicting Flight Delay Based On Multiple Linear RAlexandros ChatzipetrosNo ratings yet
- Data Visualization in TableauDocument1 pageData Visualization in TableauAbhishek MishraNo ratings yet
- Modeling Passenger Travel and Delays in The National Air Transportation SystemDocument36 pagesModeling Passenger Travel and Delays in The National Air Transportation SystemkhanNo ratings yet
- Flight Delay Prediction Team3Document8 pagesFlight Delay Prediction Team3Khang Nguyễn HoàngNo ratings yet
- An Analysis of The Causes of Flight DelaysDocument9 pagesAn Analysis of The Causes of Flight DelaysRaouf NacefNo ratings yet
- Sustainability 12 05512Document14 pagesSustainability 12 05512Nemanja IvanovićNo ratings yet
- A New Era For Crew Recovery at Continental AirlinesDocument18 pagesA New Era For Crew Recovery at Continental AirlinesMoises LimaNo ratings yet
- Region ExDocument54 pagesRegion ExishanNo ratings yet
- FAA Guide to Preflight Weather PlanningDocument37 pagesFAA Guide to Preflight Weather PlanningClaudia RodriguezNo ratings yet
- Airline Delay PredictionDocument6 pagesAirline Delay Predictionconsistent thoughtsNo ratings yet
- 49 Bookreview Gaurav Agarwal-Cheng-Lung Wu Airline Operations and Delay ManagementDocument2 pages49 Bookreview Gaurav Agarwal-Cheng-Lung Wu Airline Operations and Delay ManagementW.J. ZondagNo ratings yet
- (IJCST-V10I5P36) :mrs R Jhansi Rani, T Govardhan ReddyDocument5 pages(IJCST-V10I5P36) :mrs R Jhansi Rani, T Govardhan ReddyEighthSenseGroupNo ratings yet
- Ga Weather Decision MakingDocument37 pagesGa Weather Decision Makingdiana_veronicaNo ratings yet
- General Aviation Pilot's Guide To Preflight Weather Planning, Weather Self-Briefings, and Weather Decision MakingDocument37 pagesGeneral Aviation Pilot's Guide To Preflight Weather Planning, Weather Self-Briefings, and Weather Decision MakingzzudhirNo ratings yet
- Predicting Aircraft Trajectory Choice - A Nominal Route ApproachDocument8 pagesPredicting Aircraft Trajectory Choice - A Nominal Route ApproachMaria Del Mar Carrillo GaleraNo ratings yet
- DASC2018 Temme TienesDocument11 pagesDASC2018 Temme TienesRached LazregNo ratings yet
- Predicting Flight Delays With Error Calculation Using Machine Learned ClassifiersDocument6 pagesPredicting Flight Delays With Error Calculation Using Machine Learned Classifiersnikhil vardhanNo ratings yet
- GNR 652 Assignment 2 Report AnalysisDocument4 pagesGNR 652 Assignment 2 Report AnalysisSayan RakshitNo ratings yet
- Airline Crew Scheduling Models Algorithm PDFDocument27 pagesAirline Crew Scheduling Models Algorithm PDFPoli ValentinaNo ratings yet
- Data Mining Task Resume JurnalDocument28 pagesData Mining Task Resume JurnalChika E. SalsabillaNo ratings yet
- SCI - Volume 26 - Issue 5 - Pages 2689-2702Document14 pagesSCI - Volume 26 - Issue 5 - Pages 2689-2702Pratyush RaychaudhuriNo ratings yet
- The Effect of Airline Mergers On On-Time Performance: A Case Study of The Delta-Northwest MergerDocument21 pagesThe Effect of Airline Mergers On On-Time Performance: A Case Study of The Delta-Northwest Mergeranaconda060% (1)
- Air Traffic Control ThesisDocument4 pagesAir Traffic Control ThesisBuyResumePaperMiamiGardens100% (1)
- Flight Planning PDFDocument5 pagesFlight Planning PDFjunk5154No ratings yet
- Predicting Flight DelaysDocument7 pagesPredicting Flight Delays6653 - TasleemaNo ratings yet
- GA Weather Decision-Making Dec05 PDFDocument36 pagesGA Weather Decision-Making Dec05 PDFPete AndreNo ratings yet
- Satellite Transmission of Flight Data Recorder DataDocument15 pagesSatellite Transmission of Flight Data Recorder DatakhalilioNo ratings yet
- Level of Acceptance of Travelers on Reasons for Flight DelaysDocument33 pagesLevel of Acceptance of Travelers on Reasons for Flight DelaysMonikah Yeah SungNo ratings yet
- Airport Infrastructure Spillovers in A Network SystemDocument15 pagesAirport Infrastructure Spillovers in A Network Systemapi-3773283No ratings yet
- An Investigation Into The Determinants of Flight CancellationsDocument35 pagesAn Investigation Into The Determinants of Flight CancellationsKarthikeyan KolanjiNo ratings yet
- Innovative Project: Flight Disruption AnalysisDocument17 pagesInnovative Project: Flight Disruption AnalysisAshi GuptaNo ratings yet
- Airline Scheduling PlanningDocument6 pagesAirline Scheduling PlanningoweysiNo ratings yet
- Designing Systems for Maximum AvailabilityDocument14 pagesDesigning Systems for Maximum Availabilitykrusha03No ratings yet
- Optimized Crew SchedulingDocument27 pagesOptimized Crew SchedulingAnkit PuriNo ratings yet
- Are Passengers Compensated For Incurring An Airport Layover - Estimating The Value of Layover Time in The U.S. Airline IndustryDocument13 pagesAre Passengers Compensated For Incurring An Airport Layover - Estimating The Value of Layover Time in The U.S. Airline IndustryCarlos PanaoNo ratings yet
- Flight DElay ReportDocument49 pagesFlight DElay ReportMadhanDhonianNo ratings yet
- Airspace Complexity Measutment - An Air Traffic Control SimulationDocument10 pagesAirspace Complexity Measutment - An Air Traffic Control Simulationodic2002No ratings yet
- Optimizing Plane RoutesDocument16 pagesOptimizing Plane RoutesagashNo ratings yet
- Weather Decision-Making GuideDocument37 pagesWeather Decision-Making GuideWilliam Rios100% (1)
- IET Intelligent Trans Sys - 2022 - Wang - Flight Delay Forecasting and Analysis of Direct and Indirect FactorsDocument18 pagesIET Intelligent Trans Sys - 2022 - Wang - Flight Delay Forecasting and Analysis of Direct and Indirect FactorsKarthikeyan KolanjiNo ratings yet
- The Fall of the House of UsherDocument25 pagesThe Fall of the House of UsherMedha ChatterjeeNo ratings yet
- A Fast 3D CNN For Hyperspectral Image Classification: Muhammad AhmadDocument5 pagesA Fast 3D CNN For Hyperspectral Image Classification: Muhammad AhmadNirmalendu KumarNo ratings yet
- Form 1Document1 pageForm 1Nirmalendu KumarNo ratings yet
- Midnight Study MatDocument1 pageMidnight Study MatNirmalendu KumarNo ratings yet
- PCX - ReportNewDocument16 pagesPCX - ReportNewNirmalendu KumarNo ratings yet
- Zecchini2010 - Chapter - DharmaReconsideredTheInapproprSarpa SatraDocument22 pagesZecchini2010 - Chapter - DharmaReconsideredTheInapproprSarpa SatraNirmalendu KumarNo ratings yet
- Midnight Study MatDocument1 pageMidnight Study MatNirmalendu KumarNo ratings yet
- Exploring the Labyrinth of Symbols in 'The Garden of Forking PathsDocument29 pagesExploring the Labyrinth of Symbols in 'The Garden of Forking PathsNirmalendu KumarNo ratings yet
- THE FALL OFHouseofUSERDocument26 pagesTHE FALL OFHouseofUSERNirmalendu KumarNo ratings yet
- Macrocosm Through Microcosm InSarpaSatraDocument8 pagesMacrocosm Through Microcosm InSarpaSatraNirmalendu KumarNo ratings yet
- Euro Tro Pology Philology World LiteratuDocument23 pagesEuro Tro Pology Philology World LiteratuNirmalendu KumarNo ratings yet
- Plagiarism Checker X Originality Report: Similarity Found: 26%Document16 pagesPlagiarism Checker X Originality Report: Similarity Found: 26%Nirmalendu KumarNo ratings yet
- Geoffrey Smapson - There Is No Language InstictDocument29 pagesGeoffrey Smapson - There Is No Language InstictLandoGuillénChávezNo ratings yet
- Language As Instinct A Socio-Cultural PerspectiveDocument7 pagesLanguage As Instinct A Socio-Cultural PerspectiveNirmalendu KumarNo ratings yet
- Jejuri: Arun KolatkarDocument17 pagesJejuri: Arun KolatkarNirmalendu KumarNo ratings yet
- PHAEDRA - PLAY SUMMARY & ANALYSIS - Seneca The YoungerDocument11 pagesPHAEDRA - PLAY SUMMARY & ANALYSIS - Seneca The YoungerNirmalendu KumarNo ratings yet
- Bhaja GovindamDocument37 pagesBhaja GovindamNirmalendu KumarNo ratings yet
- Guidelines For 8th Sem 2017Document12 pagesGuidelines For 8th Sem 2017Nirmalendu KumarNo ratings yet
- Document TMPDocument16 pagesDocument TMPNirmalendu KumarNo ratings yet
- Bhaja GovindamDocument38 pagesBhaja GovindamNirmalendu KumarNo ratings yet
- Deep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary ReviewDocument32 pagesDeep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary ReviewMohammadNo ratings yet
- Plagiarism Checker X Originality Report: Similarity Found: 26%Document16 pagesPlagiarism Checker X Originality Report: Similarity Found: 26%Nirmalendu KumarNo ratings yet
- Bhaja GovindamDocument37 pagesBhaja GovindamNirmalendu KumarNo ratings yet
- Skin Cancer Classification Using Convolutional Neural NetworksDocument8 pagesSkin Cancer Classification Using Convolutional Neural NetworksNirmalendu KumarNo ratings yet
- Managing Your Email: Configuring POP3/IMAP ClientDocument48 pagesManaging Your Email: Configuring POP3/IMAP ClientJagadeesh Kumar ReddyNo ratings yet
- Ehrms AprilDocument1 pageEhrms AprilNirmalendu KumarNo ratings yet
- English Model Question PapersDocument32 pagesEnglish Model Question PapersNirmalendu KumarNo ratings yet
- Ehrms AprilDocument1 pageEhrms AprilNirmalendu KumarNo ratings yet
- The Fall of The House of UsherDocument17 pagesThe Fall of The House of UsherNirmalendu KumarNo ratings yet
- Managing Your Email: Configuring POP3/IMAP ClientDocument48 pagesManaging Your Email: Configuring POP3/IMAP ClientJagadeesh Kumar ReddyNo ratings yet
- Mark Scheme (Results) January 2007: GCE Mathematics Statistics (6683)Document8 pagesMark Scheme (Results) January 2007: GCE Mathematics Statistics (6683)ashiqueNo ratings yet
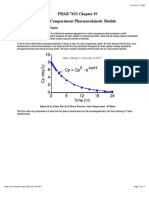
- PHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsDocument23 pagesPHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsBandameedi RamuNo ratings yet
- Exam Circular - HYE - C1 To 12, 2023-24Document26 pagesExam Circular - HYE - C1 To 12, 2023-24Aman ShethNo ratings yet
- Journal Test PostmaDocument17 pagesJournal Test PostmaOchima Walichi PrameswariNo ratings yet
- EGA Revisited: Key Concepts in Grothendieck's Foundational WorkDocument50 pagesEGA Revisited: Key Concepts in Grothendieck's Foundational WorkTomás CampoNo ratings yet
- SAS Certification Practice Exam - Base ProgrammingDocument18 pagesSAS Certification Practice Exam - Base ProgrammingArvind Shukla100% (1)
- Measures of Central Tendency and Position (Ungrouped Data) : Lesson 3Document19 pagesMeasures of Central Tendency and Position (Ungrouped Data) : Lesson 3Gemver Baula BalbasNo ratings yet
- 23 Response OptimizationDocument30 pages23 Response OptimizationafonsopilarNo ratings yet
- Time Series Modelling Using Eviews 2. Macroeconomic Modelling Using Eviews 3. Macroeconometrics Using EviewsDocument29 pagesTime Series Modelling Using Eviews 2. Macroeconomic Modelling Using Eviews 3. Macroeconometrics Using Eviewsshobu_iujNo ratings yet
- IIR FILTER COEFFICIENTSDocument2 pagesIIR FILTER COEFFICIENTSharun or rashidNo ratings yet
- Truncation Errors and The Taylor Series: Engr. Aure Flo A. Oraya, MSCEDocument29 pagesTruncation Errors and The Taylor Series: Engr. Aure Flo A. Oraya, MSCEHatsuieeNo ratings yet
- A Theory of Dynamic Oligopoly II Price Competition Kinked Demand Curves and Edgeworth CyclesDocument29 pagesA Theory of Dynamic Oligopoly II Price Competition Kinked Demand Curves and Edgeworth CyclesGiovanna Larissa MendesNo ratings yet
- On The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsDocument11 pagesOn The Static Solutions in Gravity With Massive Scalar Field in Three DimensionsMojeime Igor NowakNo ratings yet
- Irace Comex TutorialDocument5 pagesIrace Comex TutorialOmarSerranoNo ratings yet
- Association Rule MiningDocument50 pagesAssociation Rule MiningbhargaviNo ratings yet
- S Parameter BasicsDocument11 pagesS Parameter Basicslancelot795No ratings yet
- Mathematics HL Paper 2 TZ2 PDFDocument16 pagesMathematics HL Paper 2 TZ2 PDFMADANNo ratings yet
- Powershape: Training CourseDocument18 pagesPowershape: Training CourseZulhendriNo ratings yet
- Renormalization Made Easy, BaezDocument11 pagesRenormalization Made Easy, BaezdbranetensionNo ratings yet
- Calculus SyllabusDocument7 pagesCalculus SyllabusRumarie de la CruzNo ratings yet
- 1e1: Engineering Mathematics I (5 Credits) LecturerDocument2 pages1e1: Engineering Mathematics I (5 Credits) LecturerlyonsvNo ratings yet
- Activity 2.1 MMWDocument1 pageActivity 2.1 MMWJ Saint BadeNo ratings yet
- Y V - J MVJ B - J ° - ) : 4.2. The Huron-Vidal (Hvo) ModelDocument8 pagesY V - J MVJ B - J ° - ) : 4.2. The Huron-Vidal (Hvo) ModelBruno Luiz Leite MartinsNo ratings yet
- The Cricket Winner Prediction With Applications of ML and Data AnalyticsDocument18 pagesThe Cricket Winner Prediction With Applications of ML and Data AnalyticsMuhammad SwalihNo ratings yet
- ATOA CAE Multiphysics and Multimaterial Design With COMSOL Webinar PDocument31 pagesATOA CAE Multiphysics and Multimaterial Design With COMSOL Webinar PRaj C ThiagarajanNo ratings yet
- Journal of Food Engineering: V.R. Vasquez, A. Braganza, C.J. CoronellaDocument12 pagesJournal of Food Engineering: V.R. Vasquez, A. Braganza, C.J. CoronellaRamiro De Aquino GarciaNo ratings yet
- Uranian PlanetsDocument12 pagesUranian PlanetsPongwuthNo ratings yet
- Quantitative Techniques for Management DecisionsDocument4 pagesQuantitative Techniques for Management DecisionsFiraa'ool Yusuf100% (1)
- Structure Chap-7 Review ExDocument7 pagesStructure Chap-7 Review Exabenezer g/kirstosNo ratings yet
- Minimum Cost Flow: A Minimum Cost Flow Problem Is A Optimization and Decision Problem To Find TheDocument3 pagesMinimum Cost Flow: A Minimum Cost Flow Problem Is A Optimization and Decision Problem To Find Thebishal maharjanNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (54)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- AI Money Machine: Unlock the Secrets to Making Money Online with AIFrom EverandAI Money Machine: Unlock the Secrets to Making Money Online with AINo ratings yet
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (12)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesFrom Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesNo ratings yet
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- The Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIFrom EverandThe Digital Mindset: What It Really Takes to Thrive in the Age of Data, Algorithms, and AIRating: 3.5 out of 5 stars3.5/5 (7)
- ChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceFrom EverandChatGPT 4 $10,000 per Month #1 Beginners Guide to Make Money Online Generated by Artificial IntelligenceNo ratings yet
- System Design Interview: 300 Questions And Answers: Prepare And PassFrom EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNo ratings yet
- Killer ChatGPT Prompts: Harness the Power of AI for Success and ProfitFrom EverandKiller ChatGPT Prompts: Harness the Power of AI for Success and ProfitRating: 2 out of 5 stars2/5 (1)