You might also like
- Lecture 4: Linear Systems of Equations and Cramer's Rule: Zhenning Cai September 2, 2019Document5 pagesLecture 4: Linear Systems of Equations and Cramer's Rule: Zhenning Cai September 2, 2019Liu JianghaoNo ratings yet
- (A K Ray S K Gupta) Mathematical Methods in ChemiDocument53 pages(A K Ray S K Gupta) Mathematical Methods in ChemiKapilSahuNo ratings yet
- Convex Optimization Homework 1Document2 pagesConvex Optimization Homework 1gmw172No ratings yet
- Numerical Linear Algebra University of Edinburgh Past Paper 2019-2020Document5 pagesNumerical Linear Algebra University of Edinburgh Past Paper 2019-2020Jonathan SamuelsNo ratings yet
- Numerical Linear Algebra University of Edinburgh Past Paper 2021-2022Document5 pagesNumerical Linear Algebra University of Edinburgh Past Paper 2021-2022Jonathan SamuelsNo ratings yet
- EE364a Homework 1 Solutions: N 1 K 1 K I 1 K 1 1 K KDocument37 pagesEE364a Homework 1 Solutions: N 1 K 1 K I 1 K 1 1 K KAnkit BhattNo ratings yet
- Lecture 4Document32 pagesLecture 4Meenakshi JayarajNo ratings yet
- Ra2 2015Document43 pagesRa2 2015KAMAL SINGHNo ratings yet
- 3.3. K-Way Clustering Using Normalized Cuts 79Document37 pages3.3. K-Way Clustering Using Normalized Cuts 79maxxagainNo ratings yet
- Indian Institute of Technology, Bombay Chemical Engineering Cl603, Optimization Endsem, 27 April 2018Document3 pagesIndian Institute of Technology, Bombay Chemical Engineering Cl603, Optimization Endsem, 27 April 2018Lakshay ChhajerNo ratings yet
- Ellipse Fitting PDFDocument23 pagesEllipse Fitting PDFShabeeb Ali Oruvangara100% (1)
- i iπxl LDocument3 pagesi iπxl LAdarsh BandiNo ratings yet
- HW 1Document8 pagesHW 1BenNo ratings yet
- Ma214 S23 Part05Document12 pagesMa214 S23 Part05PrateekNo ratings yet
- P3 Chapter1 AlgebraDocument31 pagesP3 Chapter1 AlgebraJonathan LeeNo ratings yet
- CALCULUS II PROJECT ON AREAS BY INTEGRATIONDocument14 pagesCALCULUS II PROJECT ON AREAS BY INTEGRATIONBunny DummyNo ratings yet
- Math 122, Solution Set No. 1: 1 Chapter 1.1 Problem 16Document91 pagesMath 122, Solution Set No. 1: 1 Chapter 1.1 Problem 16homanho2021No ratings yet
- Energy Band Structure BasicsDocument13 pagesEnergy Band Structure BasicsAye Thein MaungNo ratings yet
- Sparse Regression and Dictionary LearningDocument14 pagesSparse Regression and Dictionary LearningmamurtazaNo ratings yet
- Classical Differential Geometry of Two-Dimensional Surfaces: 1 Basic DefinitionsDocument11 pagesClassical Differential Geometry of Two-Dimensional Surfaces: 1 Basic DefinitionsAhsan HayatNo ratings yet
- TensorsDocument4 pagesTensorsIpsita MandalNo ratings yet
- Techniques of IntegrationDocument89 pagesTechniques of IntegrationTarek ElheelaNo ratings yet
- 2018 MYE Suggested SolutionsDocument21 pages2018 MYE Suggested Solutionsclarissay_1No ratings yet
- LinAlg 2012june11Document14 pagesLinAlg 2012june11RJ DianaNo ratings yet
- Optimization MSDocument22 pagesOptimization MSDini NovialisaNo ratings yet
- Ghosh: CHM 112M: Lecture 4Document6 pagesGhosh: CHM 112M: Lecture 4zafuhyziNo ratings yet
- 2 KNVKSDVDocument5 pages2 KNVKSDVTeal TealyNo ratings yet
- Theorist's Toolkit Lecture 8: High Dimensional Geometry and Geometric Random WalksDocument8 pagesTheorist's Toolkit Lecture 8: High Dimensional Geometry and Geometric Random WalksJeremyKunNo ratings yet
- LAG24en v7 PDFDocument5 pagesLAG24en v7 PDFMert OzcanNo ratings yet
- Vector Calculus - GATE Study Material in PDFDocument10 pagesVector Calculus - GATE Study Material in PDFSupriya Santre100% (1)
- Vector Calculus GATE Study Material in PDF 1Document10 pagesVector Calculus GATE Study Material in PDF 1nazeeraNo ratings yet
- HW1 SolDocument9 pagesHW1 SolTDLemonNhNo ratings yet
- Linear Project 1Document13 pagesLinear Project 1Megan WheelerNo ratings yet
- Lecture08 StudentDocument20 pagesLecture08 Student112304025No ratings yet
- NATIONAL BOARD FOR HIGHER MATHEMATICS M.A. AND M.SC. SCHOLARSHIP TESTDocument6 pagesNATIONAL BOARD FOR HIGHER MATHEMATICS M.A. AND M.SC. SCHOLARSHIP TESTRaj RoyNo ratings yet
- .Pre-Calculus 8416 02Document8 pages.Pre-Calculus 8416 02Yaman TahirNo ratings yet
- Homework 03 SolutionsDocument2 pagesHomework 03 SolutionsViral patelNo ratings yet
- MATH1.3 CALCULUS II - AY2020/21: Chapter 1: Functions of Several VariablesDocument123 pagesMATH1.3 CALCULUS II - AY2020/21: Chapter 1: Functions of Several VariablesLong NguyễnNo ratings yet
- 6 3partialfractionsDocument17 pages6 3partialfractionsRyo Geoffrey WidjajaNo ratings yet
- Signed Graphs: Negative Weights A Nega-Tive Weight Indicates Dissimilarity or DistanceDocument42 pagesSigned Graphs: Negative Weights A Nega-Tive Weight Indicates Dissimilarity or DistancemaxxagainNo ratings yet
- 5.2 Sigma Notation and Limits of Finite Sums 1Document3 pages5.2 Sigma Notation and Limits of Finite Sums 1black bloodNo ratings yet
- DeterminantDocument14 pagesDeterminantNindya SulistyaniNo ratings yet
- Vector Calculus GATE Study Material in PDFDocument9 pagesVector Calculus GATE Study Material in PDFkavinkumareceNo ratings yet
- JC2 Maths H1 2017 AndersonDocument16 pagesJC2 Maths H1 2017 AndersonBryanLiNo ratings yet
- Outline (Week 3) 3.1 Partial Fractions (8.6) 3.2 Numerical Integration (8.7)Document10 pagesOutline (Week 3) 3.1 Partial Fractions (8.6) 3.2 Numerical Integration (8.7)Yifei ChengNo ratings yet
- I Computing With Matrices: 1 What Is Numerical Analysis?Document19 pagesI Computing With Matrices: 1 What Is Numerical Analysis?Anonymous zXVPi2PlyNo ratings yet
- ProblemsDocument5 pagesProblemsAhasan RidoyNo ratings yet
- MA_214_Lecture_10Document98 pagesMA_214_Lecture_10Harsh ShahNo ratings yet
- Chapter3.2 Linear Algebraic Equation - LU in & Matrix InversionDocument33 pagesChapter3.2 Linear Algebraic Equation - LU in & Matrix InversionAhmad FadzlanNo ratings yet
- Final Slides HLDocument22 pagesFinal Slides HLapi-534815355No ratings yet
- MAT637 Practice ExaminationDocument9 pagesMAT637 Practice ExaminationTaffohouo Nwaffeu Yves ValdezNo ratings yet
- Spectral Max CutDocument6 pagesSpectral Max CutHui Han ChinNo ratings yet
- Cis515 15 Spectral Clust Chap6Document10 pagesCis515 15 Spectral Clust Chap6maxxagainNo ratings yet
- STEP Support Programme Assignment 21 Warm-UpDocument4 pagesSTEP Support Programme Assignment 21 Warm-UpMike16KNo ratings yet
- Math 270A Numerical Linear Algebra Practice Final ExamDocument4 pagesMath 270A Numerical Linear Algebra Practice Final ExamTalha EtnerNo ratings yet
- Problem SolvingDocument2 pagesProblem Solvingazs88.bscpe.amauniversityNo ratings yet
- A proof of Garfunkel inequality and related results in inner product spacesDocument10 pagesA proof of Garfunkel inequality and related results in inner product spacesFustei BogdanNo ratings yet
- SPM 2018Document6 pagesSPM 2018Hui JingNo ratings yet
- W10L2Document7 pagesW10L2Venkat ReddiNo ratings yet
- How To Draw Mini CharactersDocument184 pagesHow To Draw Mini CharactersLordy Amper100% (2)
- Gapped Core Current Transformer Characteristics and PerformanceDocument9 pagesGapped Core Current Transformer Characteristics and PerformanceBalajiNo ratings yet
- MINHATECA LivrosDocument1 pageMINHATECA LivrosmaxxagainNo ratings yet
- Transmission Line Models PDFDocument17 pagesTransmission Line Models PDFDBachai84No ratings yet
- Introduction To Algorithms, Third EditionDocument3 pagesIntroduction To Algorithms, Third EditionInstrutor José NetoNo ratings yet
- TextoDocument1 pageTextomaxxagainNo ratings yet
- SpimwinDocument6 pagesSpimwinRusiawanNo ratings yet
- Chapter 13. Filter Inductor DesignDocument29 pagesChapter 13. Filter Inductor DesignNestor EspinozaNo ratings yet
- Signed Graphs: Negative Weights A Nega-Tive Weight Indicates Dissimilarity or DistanceDocument42 pagesSigned Graphs: Negative Weights A Nega-Tive Weight Indicates Dissimilarity or DistancemaxxagainNo ratings yet
- Dirichlet-Voronoi Diagrams and Delaunay Triangulations ExplainedDocument52 pagesDirichlet-Voronoi Diagrams and Delaunay Triangulations ExplainedmaxxagainNo ratings yet
- ZBus matrix building algorithmDocument10 pagesZBus matrix building algorithmsandeepbabu28No ratings yet
- Cis515 15 Spectral Clust Chap6Document10 pagesCis515 15 Spectral Clust Chap6maxxagainNo ratings yet
- Logarithms and Square Roots of Real Matrices Existence, Uniqueness, and Applications in Medical ImagingDocument44 pagesLogarithms and Square Roots of Real Matrices Existence, Uniqueness, and Applications in Medical ImagingmaxxagainNo ratings yet
- Snubber Design DR - Ray RidleyDocument7 pagesSnubber Design DR - Ray RidleyVitaliy_Tym100% (1)
- Dets Ala ArtinDocument36 pagesDets Ala ArtinmaxxagainNo ratings yet
- Cis515 15 Spectral Clust Chap1Document36 pagesCis515 15 Spectral Clust Chap1maxxagainNo ratings yet
- The Quaternions and The Spaces S, SU (2), SO (3), and RPDocument44 pagesThe Quaternions and The Spaces S, SU (2), SO (3), and RPmaxxagainNo ratings yet
- Cis515 15 Spectral Clust Chap3 4 PDFDocument43 pagesCis515 15 Spectral Clust Chap3 4 PDFmaxxagainNo ratings yet
- Singular Value Decomposition and Polar FormDocument24 pagesSingular Value Decomposition and Polar FormmaxxagainNo ratings yet
- Cis515 15 Spectral Clust Chap3 4 PDFDocument43 pagesCis515 15 Spectral Clust Chap3 4 PDFmaxxagainNo ratings yet
- 3.3. K-Way Clustering Using Normalized Cuts 79Document37 pages3.3. K-Way Clustering Using Normalized Cuts 79maxxagainNo ratings yet
- Basics of Hermitian Geometry: Vector Spaces Over The Complex Numbers Complex ConjugationDocument52 pagesBasics of Hermitian Geometry: Vector Spaces Over The Complex Numbers Complex ConjugationmaxxagainNo ratings yet
- Cis515 15 sl13 PDFDocument42 pagesCis515 15 sl13 PDFmaxxagainNo ratings yet
- Cis515 15 Spectral Clust Chap2Document18 pagesCis515 15 Spectral Clust Chap2maxxagainNo ratings yet
- Cis515 15 Spectral Clust AppADocument11 pagesCis515 15 Spectral Clust AppAmaxxagainNo ratings yet
- Minimizing Quadratic Functions with ConstraintsDocument39 pagesMinimizing Quadratic Functions with ConstraintsmaxxagainNo ratings yet
- Cis515 15 sl13 PDFDocument42 pagesCis515 15 sl13 PDFmaxxagainNo ratings yet
- QR-Decomposition For Arbitrary Matrices: ProjectionDocument14 pagesQR-Decomposition For Arbitrary Matrices: ProjectionmaxxagainNo ratings yet
- Spectral Theorems in Euclidean and Hermitian Spaces: 12.1 Normal Linear MapsDocument44 pagesSpectral Theorems in Euclidean and Hermitian Spaces: 12.1 Normal Linear MapsmaxxagainNo ratings yet
- Aircraft Flight Dynamics 2015 - 04 - 13 PDFDocument34 pagesAircraft Flight Dynamics 2015 - 04 - 13 PDFShoeb Ahmed SyedNo ratings yet
- AL6061 SiCDocument36 pagesAL6061 SiCmayankNo ratings yet
- Evidence My Presentation OutlineDocument6 pagesEvidence My Presentation OutlineJavier Alexis Herrera0% (1)
- The Relation Between Expressions for Time-Dependent Electromagnetic Fields Given by Jefimenko and Panofsky and PhillipsDocument8 pagesThe Relation Between Expressions for Time-Dependent Electromagnetic Fields Given by Jefimenko and Panofsky and PhillipsCarolina BouvierNo ratings yet
- Basic Concepts: Partial Differential Equations (Pde)Document19 pagesBasic Concepts: Partial Differential Equations (Pde)Aztec MayanNo ratings yet
- Campus News: Indian Institute of Technology MadrasDocument2 pagesCampus News: Indian Institute of Technology MadrasN Senthil Kumar VitNo ratings yet
- Strength of Materials - Torsion of Circular Cross Section - Hani Aziz AmeenDocument31 pagesStrength of Materials - Torsion of Circular Cross Section - Hani Aziz AmeenHani Aziz Ameen80% (15)
- The Universe As A HologramDocument8 pagesThe Universe As A HologramMichael Shain100% (1)
- PEDH Volume 1 2013-14 PDFDocument421 pagesPEDH Volume 1 2013-14 PDFSaurabh Gupta100% (2)
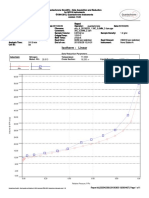
- GraphIsotherm Linear STTN - A - 20150226 - 1 30C - 0,5MM - 3 JamDocument1 pageGraphIsotherm Linear STTN - A - 20150226 - 1 30C - 0,5MM - 3 JamYunus HidayatNo ratings yet
- James Jeans: British Mathematician and AstrophysicistDocument4 pagesJames Jeans: British Mathematician and AstrophysicistMarcus AureliusNo ratings yet
- Advanced Carbonate Reservoir CharacterizationDocument5 pagesAdvanced Carbonate Reservoir CharacterizationAijaz AliNo ratings yet
- Behavior of Steel Under TensionDocument6 pagesBehavior of Steel Under TensionAshNo ratings yet
- Erico System 3000Document12 pagesErico System 3000Juan E Torres M67% (3)
- Chapter 8 - Center of Mass and Linear MomentumDocument21 pagesChapter 8 - Center of Mass and Linear MomentumAnagha GhoshNo ratings yet
- Analex RPDDocument16 pagesAnalex RPDpeach5100% (1)
- (Arfken) Mathematical Methods For Physicists 7th SOLUCIONARIO PDFDocument525 pages(Arfken) Mathematical Methods For Physicists 7th SOLUCIONARIO PDFJulian Montero100% (3)
- Gas Chromatography & Liquid Chromatography: Dr. Jenny Jacob School of Bioscience MacfastDocument31 pagesGas Chromatography & Liquid Chromatography: Dr. Jenny Jacob School of Bioscience MacfastJenny Jose100% (1)
- 1 Warning For Dealing With First FirstDocument3 pages1 Warning For Dealing With First FirstAngel RumboNo ratings yet
- Coefficient Estimation in The Dynamic Equations of Motion of An AUVDocument4 pagesCoefficient Estimation in The Dynamic Equations of Motion of An AUVanitapinkyNo ratings yet
- Map Projections and Coordinate SystemDocument7 pagesMap Projections and Coordinate SystemjparamNo ratings yet
- Reflectarray AntennaDocument27 pagesReflectarray AntennaVISHNU UNNIKRISHNANNo ratings yet
- Lifting AnalysisDocument7 pagesLifting AnalysissaharuiNo ratings yet
- Applied MechanicsDocument4 pagesApplied Mechanicszahin_132000% (1)
- Roger BakerDocument327 pagesRoger BakerfelipeplatziNo ratings yet
- Translation Table Annex VII of The CLP Regulation GodalaDocument37 pagesTranslation Table Annex VII of The CLP Regulation GodalaRiccardo CozzaNo ratings yet
- Turning FlightDocument12 pagesTurning FlightD ARUL KUMARESANNo ratings yet
- Finite Element Primer for Solving Diffusion ProblemsDocument26 pagesFinite Element Primer for Solving Diffusion Problemsted_kordNo ratings yet
- Field Density of Soils by The Core Cutter MethodDocument6 pagesField Density of Soils by The Core Cutter Methodzahari_pmuNo ratings yet
- PCA Chapter 15 - Specify, Design, ProportionDocument91 pagesPCA Chapter 15 - Specify, Design, Proportiongreat_triskelionNo ratings yet