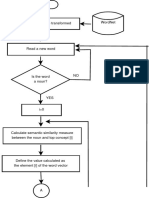
You might also like
- Text Detection and Recognition For Semantic Mapping in Indoor NavigationDocument4 pagesText Detection and Recognition For Semantic Mapping in Indoor Navigationnadeemp78No ratings yet
- Text Color ImagesDocument6 pagesText Color ImagesvandanaNo ratings yet
- Automatically Detect and Recognize Text in Natural ImagesDocument19 pagesAutomatically Detect and Recognize Text in Natural ImagesStudent 188X1A04D0No ratings yet
- Stroke Width TransformDocument8 pagesStroke Width TransformStrider_17No ratings yet
- Cohesive Multi-Oriented Text Detection and Recognition Structure in Natural Scene Images Regions Has ExposedDocument15 pagesCohesive Multi-Oriented Text Detection and Recognition Structure in Natural Scene Images Regions Has ExposedijdpsNo ratings yet
- REF2 Icpr 2010Document4 pagesREF2 Icpr 2010EmrahBaba SerpilHatunNo ratings yet
- Text Detection and Localization in Natural Scene Images Using MSER and Fast Guided FilterDocument6 pagesText Detection and Localization in Natural Scene Images Using MSER and Fast Guided FilterParul NarulaNo ratings yet
- Zhang Look More Than Once An Accurate Detector For Text of CVPR 2019 PaperDocument10 pagesZhang Look More Than Once An Accurate Detector For Text of CVPR 2019 PaperVương Hoàng Phạm NguyễnNo ratings yet
- Matching Algorithm of 3D Point Clouds Based On Multiscale Features and Covariance Matrix DescriptorsDocument13 pagesMatching Algorithm of 3D Point Clouds Based On Multiscale Features and Covariance Matrix DescriptorsDr. Chekir AmiraNo ratings yet
- Miriam Leon, Veronica Vilaplana, Antoni Gasull, Ferran Marques (Veronica - Vilaplana, Antoni - Gasull, Ferran - Marques) @upc - EduDocument4 pagesMiriam Leon, Veronica Vilaplana, Antoni Gasull, Ferran Marques (Veronica - Vilaplana, Antoni - Gasull, Ferran - Marques) @upc - EduAbdulrahman Al-MolijyNo ratings yet
- Text DetectionDocument17 pagesText DetectionKrishna ShettyNo ratings yet
- Axioms 11 00112Document23 pagesAxioms 11 00112nach456No ratings yet
- 03 Filter Pas IfDocument5 pages03 Filter Pas IfBasha TahamalNo ratings yet
- Script Independent Multi-Oriented Text DetectionDocument37 pagesScript Independent Multi-Oriented Text DetectionSunil ChaluvaiahNo ratings yet
- Scene Text Recognition by Using EE-MSER and Optical Character Recognition For Natural Images-35843Document5 pagesScene Text Recognition by Using EE-MSER and Optical Character Recognition For Natural Images-35843Editor IJAERDNo ratings yet
- Remote Sensing Image Segmentation by Combining Spectral and Texture FeaturesDocument9 pagesRemote Sensing Image Segmentation by Combining Spectral and Texture Featuresrupa surekhaNo ratings yet
- Journal Pre-ProofDocument41 pagesJournal Pre-ProofHARE KRISHNANo ratings yet
- X2 - Text Recognition PDFDocument14 pagesX2 - Text Recognition PDFMohammed A IsaNo ratings yet
- Improving Multimedia Retrieval With A Video OCRDocument12 pagesImproving Multimedia Retrieval With A Video OCRSujayCjNo ratings yet
- Enhancement and Segmentation of Historical RecordsDocument19 pagesEnhancement and Segmentation of Historical RecordsCS & ITNo ratings yet
- Ijetr022734 PDFDocument3 pagesIjetr022734 PDFerpublicationNo ratings yet
- Ijecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)Document8 pagesIjecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)IAEME PublicationNo ratings yet
- Title: Spatial Cohesion Refers To The Fact That TextDocument6 pagesTitle: Spatial Cohesion Refers To The Fact That TextVigneshInfotechNo ratings yet
- Model Globally, Match Locally: Efficient and Robust 3D Object RecognitionDocument8 pagesModel Globally, Match Locally: Efficient and Robust 3D Object RecognitionBích Lâm NgọcNo ratings yet
- Text Detection and Recognition A ReviewDocument10 pagesText Detection and Recognition A ReviewIJRASETPublicationsNo ratings yet
- High-Performance OCR For Printed English and Fraktur Using LSTM NetworksDocument5 pagesHigh-Performance OCR For Printed English and Fraktur Using LSTM NetworksGoogle OutboxNo ratings yet
- Ok - IET Image Processing - 2016 - Belhedi - Adaptive Scene Text Binarisation On Images Captured by Smartphones - XDocument9 pagesOk - IET Image Processing - 2016 - Belhedi - Adaptive Scene Text Binarisation On Images Captured by Smartphones - Xsantiago gonzalezNo ratings yet
- Optical Character Recognition For Devanagari ScriptDocument5 pagesOptical Character Recognition For Devanagari ScriptAmol BhilareNo ratings yet
- DownloadDocument5 pagesDownloadsantiago gonzalezNo ratings yet
- Real-Time Semantic Slam With DCNN-based Feature Point Detection, Matching and Dense Point Cloud AggregationDocument6 pagesReal-Time Semantic Slam With DCNN-based Feature Point Detection, Matching and Dense Point Cloud AggregationJUAN CAMILO TORRES MUNOZNo ratings yet
- Ancient Text Character Recognition Using Deep Learning: Shikhachadha, Dr. Sonumittal and Dr. Vivek SinghalDocument8 pagesAncient Text Character Recognition Using Deep Learning: Shikhachadha, Dr. Sonumittal and Dr. Vivek SinghalHarish GanapathyNo ratings yet
- Robust Text Detection in Natural Images With Edge-Enhanced Maximally Stable Extremal RegionsDocument4 pagesRobust Text Detection in Natural Images With Edge-Enhanced Maximally Stable Extremal Regionssatishkumar697No ratings yet
- Student AttendanceDocument50 pagesStudent AttendanceHarikrishnan ShunmugamNo ratings yet
- Recognition of Multi-Oriented, Multi-Sized, and Curved TextDocument5 pagesRecognition of Multi-Oriented, Multi-Sized, and Curved Textcnrk777No ratings yet
- 09 - S. Kim, S. Nowozin, P. Kohli, and C. D. Yoo, Higher-Order Correlation Clustering For Image SegmentationDocument14 pages09 - S. Kim, S. Nowozin, P. Kohli, and C. D. Yoo, Higher-Order Correlation Clustering For Image SegmentationBruno TondinNo ratings yet
- Extracting Text From VideosDocument11 pagesExtracting Text From VideosAbhijeet ChattarjeeNo ratings yet
- Pattern Recognition Letters: Ákos Kiss, Tamás SzirányiDocument9 pagesPattern Recognition Letters: Ákos Kiss, Tamás SzirányiSonia R. BaldárragoNo ratings yet
- Politecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSDocument7 pagesPolitecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSraisin netsNo ratings yet
- Object Classification of Aerial Images With Bag-of-Visual WordsDocument5 pagesObject Classification of Aerial Images With Bag-of-Visual Wordsakumar5189No ratings yet
- NeurIPS 2019 Image Captioning Transforming Objects Into Words PaperDocument11 pagesNeurIPS 2019 Image Captioning Transforming Objects Into Words Paperyazhini shanmugamNo ratings yet
- Curved Scene Text Detection Based On Mask R-CNNDocument13 pagesCurved Scene Text Detection Based On Mask R-CNNRajeshwari R PNo ratings yet
- System For Identifying Texts Written in Kazakh LanguageDocument5 pagesSystem For Identifying Texts Written in Kazakh LanguageInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Politecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSDocument7 pagesPolitecnico Di Torino Repository ISTITUZIONALE: Loop Detection in Robotic Navigation Using MPEG CDVSPepe MNo ratings yet
- Region-Based Moving Shadow DetectionDocument53 pagesRegion-Based Moving Shadow DetectionAbdul RazzakNo ratings yet
- Robust Planar Target Tracking and Pose Estimation From A Single ConcavityDocument7 pagesRobust Planar Target Tracking and Pose Estimation From A Single ConcavitydharmithNo ratings yet
- IJCSNS International Journal of Computer Science and Network Security, VOL.8Document6 pagesIJCSNS International Journal of Computer Science and Network Security, VOL.8activation12No ratings yet
- NeRF - NavigationDocument8 pagesNeRF - NavigationBach NguyenNo ratings yet
- Accuracy Augmentation of Tamil OCR Using Algorithm FusionDocument6 pagesAccuracy Augmentation of Tamil OCR Using Algorithm FusionsubakishaanNo ratings yet
- Sensors 23 04364Document19 pagesSensors 23 04364mujahid naumanNo ratings yet
- Pattern Recognition: Xijian Fan, Tardi TjahjadiDocument8 pagesPattern Recognition: Xijian Fan, Tardi TjahjadiSabha NayaghamNo ratings yet
- Orientación Basado en Kinect Robusto y Posicionamiento de Un Robot Multidireccional Mediante El Reconocimiento Log-AbDocument12 pagesOrientación Basado en Kinect Robusto y Posicionamiento de Un Robot Multidireccional Mediante El Reconocimiento Log-AbtoranagasanNo ratings yet
- Interacting-Enhancing Feature Transformer For Cross-Modal Remote-Sensing Image and Text RetrievalDocument15 pagesInteracting-Enhancing Feature Transformer For Cross-Modal Remote-Sensing Image and Text RetrievalZahra WaheedNo ratings yet
- TLGAN: Efficient text localization using generative adversarial networksDocument17 pagesTLGAN: Efficient text localization using generative adversarial networksMinh Đinh NhậtNo ratings yet
- Joint Detection and TrackingDocument7 pagesJoint Detection and TrackingEngr EbiNo ratings yet
- Optics Communications: Di Guo, Jingwen Yan, Xiaobo QuDocument7 pagesOptics Communications: Di Guo, Jingwen Yan, Xiaobo QuWafa BenzaouiNo ratings yet
- MMSP SubmittedDocument7 pagesMMSP SubmittedShopnil SarkarNo ratings yet
- Scene Text Detection Using Machine Learning ClassifiersDocument5 pagesScene Text Detection Using Machine Learning ClassifiersijsretNo ratings yet
- TCS OcrDocument39 pagesTCS OcrThrow AwayNo ratings yet
- 3 s2.0 B9780124406513500055 MainDocument1 page3 s2.0 B9780124406513500055 MainlikufaneleNo ratings yet
- 3 s2.0 B9780124055315000237 MainDocument2 pages3 s2.0 B9780124055315000237 MainlikufaneleNo ratings yet
- Advisory Board: Gerard Alberts, Hans Van Der Meer, Donn Parker, Martin RudnerDocument1 pageAdvisory Board: Gerard Alberts, Hans Van Der Meer, Donn Parker, Martin RudnerlikufaneleNo ratings yet
- 3 s2.0 B9781843340454500046 MainDocument1 page3 s2.0 B9781843340454500046 MainlikufaneleNo ratings yet
- 3 s2.0 B9780124047020100308 MainDocument1 page3 s2.0 B9780124047020100308 MainlikufaneleNo ratings yet
- 3 s2.0 B9780124045767099871 MainDocument1 page3 s2.0 B9780124045767099871 MainlikufaneleNo ratings yet
- 3 s2.0 B9780124047020050011 MainDocument1 page3 s2.0 B9780124047020050011 MainlikufaneleNo ratings yet
- 3 s2.0 B978012416602809988X MainDocument1 page3 s2.0 B978012416602809988X MainlikufaneleNo ratings yet
- Yoshida Kyodai - HishoeDocument1 pageYoshida Kyodai - HishoelikufaneleNo ratings yet
- Information Retrieval: Documents That Contain The Information WeDocument4 pagesInformation Retrieval: Documents That Contain The Information WelikufaneleNo ratings yet
- Postdoctoral Fellow Positions 2010.9.6Document3 pagesPostdoctoral Fellow Positions 2010.9.6likufaneleNo ratings yet
- Trigram Eps Converted ToDocument1 pageTrigram Eps Converted TolikufaneleNo ratings yet
- Preface: Conference ChairDocument4 pagesPreface: Conference ChairlikufaneleNo ratings yet
- Conflict of InterestDocument1 pageConflict of InterestlikufaneleNo ratings yet
- 3 s2.0 B9780124055315000213 MainDocument1 page3 s2.0 B9780124055315000213 MainlikufaneleNo ratings yet
- Vec CreationDocument1 pageVec CreationlikufaneleNo ratings yet
- Dr. Jason Andress Security Expert Author BioDocument1 pageDr. Jason Andress Security Expert Author BiolikufaneleNo ratings yet
- Natural Language Processing II (SC674: Contents of CourseDocument4 pagesNatural Language Processing II (SC674: Contents of CourselikufaneleNo ratings yet
- Ciarp AttachmentDocument1 pageCiarp AttachmentlikufaneleNo ratings yet
- Templates and KeywordsDocument8 pagesTemplates and KeywordslikufaneleNo ratings yet
- Response To ReviewersDocument1 pageResponse To ReviewerslikufaneleNo ratings yet
- Uni Gram Ass in TresDocument1 pageUni Gram Ass in TreslikufaneleNo ratings yet
- PACLIC23 Incover2Document1 pagePACLIC23 Incover2likufaneleNo ratings yet
- Web Site: Conference Program Management byDocument1 pageWeb Site: Conference Program Management bylikufaneleNo ratings yet
- Binary Entropy PlotDocument1 pageBinary Entropy PlotlikufaneleNo ratings yet
- A New Methodology For Criminal-Analysis, Based On Inductive Learning TechniquesDocument1 pageA New Methodology For Criminal-Analysis, Based On Inductive Learning TechniqueslikufaneleNo ratings yet
- PACLIC23 Incover2Document1 pagePACLIC23 Incover2likufaneleNo ratings yet
- TESAURO - SE1 Eps Converted ToDocument1 pageTESAURO - SE1 Eps Converted TolikufaneleNo ratings yet
- PDF Format For PaperDocument1 pagePDF Format For Paperal6ayebNo ratings yet
- BlankDocument1 pageBlanklikufaneleNo ratings yet
- Example of BVP ProblemsDocument3 pagesExample of BVP ProblemsAbhishek KumarNo ratings yet
- Performance Appraisal Form From IndustryDocument2 pagesPerformance Appraisal Form From IndustryJaspal SinghNo ratings yet
- Skynex SkyknightDocument2 pagesSkynex SkyknightMOHSENNo ratings yet
- HazMat DOTDocument48 pagesHazMat DOTRenalyn TorioNo ratings yet
- Flow Chart Fixed Column BasesDocument4 pagesFlow Chart Fixed Column BasesstycnikNo ratings yet
- Hydraulic Excavator GuideDocument9 pagesHydraulic Excavator Guidewritetojs100% (1)
- The Future of HovercraftDocument3 pagesThe Future of Hovercrafthovpod6214100% (4)
- Telepo SDK Develop Guide (Linux For TPS300) - v1.0Document10 pagesTelepo SDK Develop Guide (Linux For TPS300) - v1.0VKM2013No ratings yet
- PGCB ReportDocument36 pagesPGCB ReportNayemul Hasan NayemNo ratings yet
- Sixth Sense Technology: Submitted By: Sushma Singh EC (B) 0906831087Document23 pagesSixth Sense Technology: Submitted By: Sushma Singh EC (B) 0906831087Swechha KambojNo ratings yet
- MF1547Front Linkage - Seat PDFDocument18 pagesMF1547Front Linkage - Seat PDFAhmad Ali NursahidinNo ratings yet
- KTS Quotation Meidan Building Plumbing Works PDFDocument1 pageKTS Quotation Meidan Building Plumbing Works PDFShakeel Ahmad100% (1)
- Sensor Performance Characteristics DefinitionsDocument12 pagesSensor Performance Characteristics DefinitionsKhairul FahzanNo ratings yet
- Oracle PLSQL Best Practices and Tuning PDFDocument270 pagesOracle PLSQL Best Practices and Tuning PDFKeyur Pandya100% (1)
- REEM Document SubmissionDocument8 pagesREEM Document Submissionkiller120No ratings yet
- SwephprgDocument94 pagesSwephprgAbhisekAcharyaNo ratings yet
- Odometer Recording StrategiesDocument2 pagesOdometer Recording StrategiesFroilan CaoleNo ratings yet
- DesuperheatersDocument8 pagesDesuperheatersmuhdrijasmNo ratings yet
- Trajectory ClusteringDocument58 pagesTrajectory ClusteringPetrick Gonzalez PerezNo ratings yet
- Spare Parts List: Hydraulic Breakers RX6Document16 pagesSpare Parts List: Hydraulic Breakers RX6Sales AydinkayaNo ratings yet
- Fuels and Chemicals - Auto Ignition TemperaturesDocument5 pagesFuels and Chemicals - Auto Ignition TemperaturesyoesseoyNo ratings yet
- Bitsler DicebotDocument4 pagesBitsler DicebotShinsNo ratings yet
- Matriks Compressor 2023Document27 pagesMatriks Compressor 2023Puji RustantoNo ratings yet
- Honda General Pursone Engine Gx120k1Document215 pagesHonda General Pursone Engine Gx120k1Ricky VilNo ratings yet
- Ee8602 Protection and SwitchgearDocument2 pagesEe8602 Protection and SwitchgeararwinNo ratings yet
- Action Stories Lesson 2Document2 pagesAction Stories Lesson 2api-296427690No ratings yet
- CMM49 14 01 MtocDocument2 pagesCMM49 14 01 MtocMichail K100% (1)
- LOR Engineering Excellence Journal 2013Document77 pagesLOR Engineering Excellence Journal 2013marcinek77No ratings yet
- HVX200 LentesDocument2 pagesHVX200 Lentespink2004No ratings yet
- Engine and vehicle parameter monitoringDocument170 pagesEngine and vehicle parameter monitoringAlejandro Samuel100% (2)