You might also like
- Math30-1 Workbook One PDFDocument257 pagesMath30-1 Workbook One PDFTuyếnĐặng100% (1)
- Understand DivisionDocument69 pagesUnderstand Divisiontau24No ratings yet
- Planet Maths 3rd - Sample PagesDocument32 pagesPlanet Maths 3rd - Sample PagesEdTech Folens78% (23)
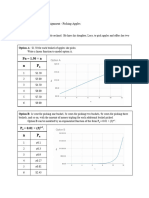
- Math 1030 - Growth Models Written Assignment Picking Apples - Mennetta Darci EcclesDocument2 pagesMath 1030 - Growth Models Written Assignment Picking Apples - Mennetta Darci Ecclesapi-710194376No ratings yet
- General Education Mathematics LET Reviewer 2Document4 pagesGeneral Education Mathematics LET Reviewer 2Iris JordanNo ratings yet
- Pms Past Papers AnalysisDocument6 pagesPms Past Papers Analysishadiwasim34No ratings yet
- Modeling and Controller Designing of Rotary Inverted Pendulum (RIP) - Comparison by Using Various Design MethodsDocument8 pagesModeling and Controller Designing of Rotary Inverted Pendulum (RIP) - Comparison by Using Various Design Methodskyaw phone htetNo ratings yet
- Ged 102 Mathematics in The Modern WorldDocument103 pagesGed 102 Mathematics in The Modern WorldCRISTINE JOY ATIENZA50% (2)
- Janella ShuDocument9 pagesJanella ShuDe Nicolas JaidarNo ratings yet
- Unit 4 - Continuous Random VariablesDocument35 pagesUnit 4 - Continuous Random VariablesShouq AbdullahNo ratings yet
- W4 May2022Document3 pagesW4 May2022naghulNo ratings yet
- 4.1 Probability Density Functions (PDFS) and Cumulative Distribution Functions (CDFS) For Continuous Random VariablesDocument4 pages4.1 Probability Density Functions (PDFS) and Cumulative Distribution Functions (CDFS) For Continuous Random VariablesJoséBorjNo ratings yet
- 3200chap3 wk6Document28 pages3200chap3 wk6Nuo XuNo ratings yet
- AdvStats - W4 - ContinousDocument24 pagesAdvStats - W4 - ContinousPedro FernandezNo ratings yet
- 4.1 - Probability Density Functions (PDFS) and Cumulative Distribution Functions (CDFS) For Continuous Random Variables - Statistics LibreTextsDocument4 pages4.1 - Probability Density Functions (PDFS) and Cumulative Distribution Functions (CDFS) For Continuous Random Variables - Statistics LibreTextsRaavi TiwariNo ratings yet
- c04 MathexpDocument8 pagesc04 MathexpCharleneMendozaEspirituNo ratings yet
- Chapter 2. Order StatisticsDocument30 pagesChapter 2. Order Statisticsমে হে দীNo ratings yet
- Generating Random VariablesDocument31 pagesGenerating Random VariablesylustNo ratings yet
- RM2Document102 pagesRM2Anonymous eWMnRr70qNo ratings yet
- UNIT II Probability TheoryDocument84 pagesUNIT II Probability TheoryaymanNo ratings yet
- AMA2104 Probability and Engineering Statistics 2 Probability DistributionDocument37 pagesAMA2104 Probability and Engineering Statistics 2 Probability DistributionYH CHENGNo ratings yet
- Continuity and Uniform ContinuityDocument8 pagesContinuity and Uniform Continuityaye pyoneNo ratings yet
- Slide Chap4Document19 pagesSlide Chap4dangxuanhuy3108No ratings yet
- Fourier Series: Differential EquationsDocument24 pagesFourier Series: Differential EquationsAlmer AndromedaNo ratings yet
- Lecture 5 - Fall 2023Document14 pagesLecture 5 - Fall 2023tarunya724No ratings yet
- Computational Astrophysics DerivativesDocument27 pagesComputational Astrophysics DerivativesJhon J Galan RNo ratings yet
- Week2 Lecture1 PDFDocument25 pagesWeek2 Lecture1 PDFAbdullah AloglaNo ratings yet
- Slide Chap4Document19 pagesSlide Chap4Ton Khanh LinhNo ratings yet
- Screenshot 2023-10-07 at 4.48.58 PMDocument26 pagesScreenshot 2023-10-07 at 4.48.58 PMyosalkaabiNo ratings yet
- MATH10BDIS0321SOLNSDocument6 pagesMATH10BDIS0321SOLNSKarimaNo ratings yet
- DerivativesDocument5 pagesDerivativesnochekervinpaulNo ratings yet
- Continuous Functions ExplainedDocument28 pagesContinuous Functions ExplainedDikshaNo ratings yet
- Week 4 Continuous Probability Distribution PDFDocument40 pagesWeek 4 Continuous Probability Distribution PDFloompapasNo ratings yet
- WebDocument329 pagesWebDon ShineshNo ratings yet
- Mca4020 SLM Unit 02Document27 pagesMca4020 SLM Unit 02AppTest PINo ratings yet
- Interpolation PolynomialDocument30 pagesInterpolation PolynomialBeckham ChaileNo ratings yet
- Week - 2Document58 pagesWeek - 2riotseeker12No ratings yet
- Properties of MLE: Consistency, Asymptotic Normality. Fisher InformationDocument7 pagesProperties of MLE: Consistency, Asymptotic Normality. Fisher InformationMuhammad AliNo ratings yet
- Pairs of Random VariablesDocument69 pagesPairs of Random Variablest_man222No ratings yet
- Polynomial InterpolationDocument21 pagesPolynomial InterpolationmayankNo ratings yet
- Sol 1Document5 pagesSol 1Dinesh KumarNo ratings yet
- 11 Exponential and JointDocument2 pages11 Exponential and JointSayantan HaldarNo ratings yet
- Ma691 ch1 PDFDocument14 pagesMa691 ch1 PDFham.karimNo ratings yet
- Eec 161 ch04Document82 pagesEec 161 ch04Hanna ShuiNo ratings yet
- Chapter Two-MATH122Document21 pagesChapter Two-MATH122Josiah GyanNo ratings yet
- Total Probability TheoremDocument9 pagesTotal Probability TheoremjedacobNo ratings yet
- 2023spring CAL I WK4 THR v3Document19 pages2023spring CAL I WK4 THR v3권종욱No ratings yet
- Lecture Notes On Distributions: Hasse CarlssonDocument83 pagesLecture Notes On Distributions: Hasse CarlssonRajesh MondalNo ratings yet
- Lecture 7 - Fall 2023Document28 pagesLecture 7 - Fall 2023tarunya724No ratings yet
- Stat 110 Strategic Practice 4, Fall 2011Document16 pagesStat 110 Strategic Practice 4, Fall 2011nxp HeNo ratings yet
- Midterm On Oct 13Document31 pagesMidterm On Oct 13Tina ChenNo ratings yet
- Lecture04 Continuous Random Variables Ver1Document35 pagesLecture04 Continuous Random Variables Ver1Hongjiang ZhangNo ratings yet
- AxdifDocument38 pagesAxdifPeter NewmanNo ratings yet
- Appendix5 RandomVariablesDocument26 pagesAppendix5 RandomVariablesWu WeimingNo ratings yet
- Continuous Distributions ChapterDocument24 pagesContinuous Distributions Chaptercharu.iitdNo ratings yet
- Convex ProblemsDocument48 pagesConvex ProblemsAdrian GreenNo ratings yet
- LectureNotes CIMPAABIDJAN2014 PDFDocument30 pagesLectureNotes CIMPAABIDJAN2014 PDFPeronNo ratings yet
- Chapitre2 Quadrature ADocument13 pagesChapitre2 Quadrature Asalma LabbaneNo ratings yet
- Fourier Lect#1Document11 pagesFourier Lect#1Hasibur RahmanNo ratings yet
- Chapter 2B - Continuous: Random VariablesDocument20 pagesChapter 2B - Continuous: Random VariablesAhmad AiNo ratings yet
- 1.017/1.010 Class 7 Random Variables and Probability DistributionsDocument3 pages1.017/1.010 Class 7 Random Variables and Probability DistributionsDr. Ir. R. Didin Kusdian, MT.No ratings yet
- Stat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.eduDocument35 pagesStat 110, Lecture 7 Continuous Probability Distributions: Bheavlin@stat - Stanford.edujamesyuNo ratings yet
- Module 32 2 PDFDocument39 pagesModule 32 2 PDFpankaj kumarNo ratings yet
- Differential Calculus: Function y F (X)Document18 pagesDifferential Calculus: Function y F (X)SilvaSunnyNo ratings yet
- Limits and Continuity ChapterDocument11 pagesLimits and Continuity ChapterSashaNo ratings yet
- Lecture 5Document2 pagesLecture 5anchal shuklaNo ratings yet
- Mvcalc Notes 2018 v2Document39 pagesMvcalc Notes 2018 v2Matthew LewingtonNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Top 100 CodesDocument94 pagesTop 100 CodesSURJIT VERMA100% (1)
- MSC 1 Sem Mathematics Numerical Analysis 11170 Summer 2019Document2 pagesMSC 1 Sem Mathematics Numerical Analysis 11170 Summer 201964210017No ratings yet
- Class 10 Pre Mid TermDocument8 pagesClass 10 Pre Mid TermGyan BardeNo ratings yet
- Math concepts and skillsDocument2 pagesMath concepts and skillsNANCITA O. PERLASNo ratings yet
- Lecturenotes Krs OR7Document25 pagesLecturenotes Krs OR7satish5269115No ratings yet
- Artin - Grothendieck TopologiesDocument95 pagesArtin - Grothendieck Topologiesusername6464No ratings yet
- CV of Great PDFDocument3 pagesCV of Great PDFAnimesh PariharNo ratings yet
- Undefined Terms CotDocument38 pagesUndefined Terms CotFunny Videos of all TimeNo ratings yet
- Analisis Isi Buku Matematika Kurikulum 2013 SMP Kelas Viii Semester 1 Berdasarkan Taksonomi TimssDocument12 pagesAnalisis Isi Buku Matematika Kurikulum 2013 SMP Kelas Viii Semester 1 Berdasarkan Taksonomi Timssgreen clothNo ratings yet
- Solutions to the 79th William Lowell Putnam Mathematical CompetitionDocument8 pagesSolutions to the 79th William Lowell Putnam Mathematical CompetitionWeihanZhang100% (1)
- Math 11 CORE Gen Math Q1 Week 8Document28 pagesMath 11 CORE Gen Math Q1 Week 8MeYo SanNo ratings yet
- What I Need To Know: Comparing Numbers Up To 10 000 Using Relation SymbolsDocument9 pagesWhat I Need To Know: Comparing Numbers Up To 10 000 Using Relation SymbolsJEZEBEL ASNENo ratings yet
- Math6 Q2Mod6 GEMDAS Rule Alvin G Biniahan Bgo v2Document21 pagesMath6 Q2Mod6 GEMDAS Rule Alvin G Biniahan Bgo v2Ronel TablanteNo ratings yet
- Basic Calculus Q3 W5Document6 pagesBasic Calculus Q3 W5Rufina RiveraNo ratings yet
- Edge Detection Using Fuzzy Logic: B. Govinda Lakshmi, B. HemalathaDocument3 pagesEdge Detection Using Fuzzy Logic: B. Govinda Lakshmi, B. HemalathaumeshgangwarNo ratings yet
- Power Query Cheat SheetDocument5 pagesPower Query Cheat SheetsharukhNo ratings yet
- Solved Simplex Problems PDFDocument5 pagesSolved Simplex Problems PDFSwati Sucharita DasNo ratings yet
- Math ScoreDocument5 pagesMath ScoreMaryNo ratings yet
- An Application of The Fermat-Torricelli PointDocument6 pagesAn Application of The Fermat-Torricelli PointDejan DjokićNo ratings yet
- Maths Class Xi Chapter 04 Complex Numbers Practice Paper 04Document3 pagesMaths Class Xi Chapter 04 Complex Numbers Practice Paper 04KavinNo ratings yet
- Fearful Symmetry Is God A Geometria PDFDocument2 pagesFearful Symmetry Is God A Geometria PDFJayNo ratings yet
- Modul 11: Matriks: (Bam) Modul Matematik SPMDocument2 pagesModul 11: Matriks: (Bam) Modul Matematik SPMbalkisNo ratings yet