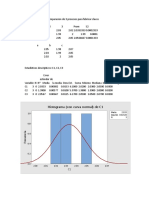
You might also like
- Econometría Aplicada I PDFDocument27 pagesEconometría Aplicada I PDFRAY VEGANo ratings yet
- CAPITULO 2 2da EdDocument38 pagesCAPITULO 2 2da EdRobert GRNo ratings yet
- Onocc - Econometria IiDocument7 pagesOnocc - Econometria IiMiracle EdisonNo ratings yet
- Modelos de RegresiónDocument34 pagesModelos de Regresiónnataly chNo ratings yet
- Practica 1 PDFDocument9 pagesPractica 1 PDFKaren HerreraNo ratings yet
- Deber ValidacionDocument4 pagesDeber ValidacionLukas GalarzaNo ratings yet
- Regresión Lineal SimpleDocument12 pagesRegresión Lineal SimpleJordy Bravo50% (4)
- Prácticas Gretl Bloque 3 - Estimación MCODocument26 pagesPrácticas Gretl Bloque 3 - Estimación MCOPablo RedondoNo ratings yet
- Material de EconometriaDocument135 pagesMaterial de EconometriaRicardo Andres Ahumada Leiva100% (1)
- Ema5. Diagnosis y Validación Del Modelo de Regresión Lineal MúltiplepdfDocument28 pagesEma5. Diagnosis y Validación Del Modelo de Regresión Lineal MúltiplepdfEliana MendozaNo ratings yet
- Transparencias Tema II: Modelo Básico de Regresión Lineal MúltipleDocument50 pagesTransparencias Tema II: Modelo Básico de Regresión Lineal MúltipleEmilyNo ratings yet
- 3 Aea4257 C9 ApunteacademicoDocument15 pages3 Aea4257 C9 ApunteacademicoSolange DíazNo ratings yet
- 03 Violacion Gauss-MarkovDocument6 pages03 Violacion Gauss-MarkovSantiago Castro MartinNo ratings yet
- Apuntes Clase Econometria IDocument68 pagesApuntes Clase Econometria ITeresalinapNo ratings yet
- Romero Pérez Neftalí SintesisDocument4 pagesRomero Pérez Neftalí Sintesismario silvaNo ratings yet
- An Álisis de Regresión y Correlación Múltiple Modelo de Regresi Ón Lineal MúltipleDocument3 pagesAn Álisis de Regresión y Correlación Múltiple Modelo de Regresi Ón Lineal MúltipleKarina MarisolNo ratings yet
- Tema 4 RLSDocument20 pagesTema 4 RLSEmilyNo ratings yet
- El Modelo de Regresion Lineal Multiple Con StataDocument14 pagesEl Modelo de Regresion Lineal Multiple Con StataSergio Luis OlivoNo ratings yet
- 8regresión Lineal MultipleDocument14 pages8regresión Lineal MultipleDEIYA BAUTISTANo ratings yet
- Modelo de Regresión MultipleDocument21 pagesModelo de Regresión MultipleRudy Estefany Risco Ancajima100% (1)
- DocumentoDocument4 pagesDocumentomonicaNo ratings yet
- Modelos de Ecuaciones SimultáneasDocument7 pagesModelos de Ecuaciones SimultáneasenriqbunburyNo ratings yet
- Analisis de Regresion MultipleDocument20 pagesAnalisis de Regresion MultipleLoyda AlejandroNo ratings yet
- 6 Regresión Lineal PDFDocument102 pages6 Regresión Lineal PDFJose David Jiménez TolozaNo ratings yet
- Análisis Del Método de Regresión Lineal Simple.Document12 pagesAnálisis Del Método de Regresión Lineal Simple.alberto100% (1)
- Tarea Semana 11 - Grupo 3 - Analisis de Regresión IiDocument28 pagesTarea Semana 11 - Grupo 3 - Analisis de Regresión IiVerónica Garcia RosasNo ratings yet
- Tema 1Document21 pagesTema 1Laura CedrónNo ratings yet
- CAPITULO 3-Analisis de Regresion Múltiple - EstimaciónDocument40 pagesCAPITULO 3-Analisis de Regresion Múltiple - EstimaciónARony JoNo ratings yet
- Tarea 1. EconometricsDocument3 pagesTarea 1. EconometricsObedRománNo ratings yet
- Contenido Activador Unidad 3 EconometríaDocument22 pagesContenido Activador Unidad 3 Econometríaalmendra4943No ratings yet
- Minimos Cuadrados PDFDocument22 pagesMinimos Cuadrados PDFelpobrepabloNo ratings yet
- Capítulo Xvi Modelos de Ecuaciones Multiples Ii PDFDocument81 pagesCapítulo Xvi Modelos de Ecuaciones Multiples Ii PDFpolojorge200% (1)
- Cap7 843corregidoDocument16 pagesCap7 843corregidoRosa YudithqmNo ratings yet
- 1er Parcial Regresion Lineal SimpleDocument3 pages1er Parcial Regresion Lineal Simplemarcos daniel luca velaNo ratings yet
- Regresion Lineal MúltipleDocument17 pagesRegresion Lineal MúltipleMILEYNINo ratings yet
- Presentacion1 de Estadistica PDFDocument33 pagesPresentacion1 de Estadistica PDFjensy MataNo ratings yet
- Presentación1 de EstadisticaDocument33 pagesPresentación1 de Estadisticapanterayiyi0% (2)
- 2CORRE7E1Document10 pages2CORRE7E1Morel VillatoroNo ratings yet
- Minimos Cuadrados en La IngenieriaDocument7 pagesMinimos Cuadrados en La IngenieriaDavid DiazNo ratings yet
- Taller Final - Econometria IDocument35 pagesTaller Final - Econometria IMARIA CAMILA SOTO GARCIANo ratings yet
- Expo Metodos HoyDocument33 pagesExpo Metodos Hoyfrancisco fernandezNo ratings yet
- ARIMADocument8 pagesARIMARubénNo ratings yet
- Correlación Múltiple y LinealDocument8 pagesCorrelación Múltiple y LinealMaricel Anahi Carbajal SantacruzNo ratings yet
- Capítulo 7 Análisis de Regresión MúltipleDocument9 pagesCapítulo 7 Análisis de Regresión MúltipleLoyda AlejandroNo ratings yet
- Regresion Simple 2022 11Document27 pagesRegresion Simple 2022 11Dannis Omar Campos ZavaletaNo ratings yet
- Guia 1Document11 pagesGuia 1TeresalinapNo ratings yet
- Trabajo (3) Modelos de Regresion-CuadráticaDocument22 pagesTrabajo (3) Modelos de Regresion-CuadráticaPedro EspinozaNo ratings yet
- EstadisticaDocument5 pagesEstadisticamoisesNo ratings yet
- Problemática Modelo EconometriaDocument10 pagesProblemática Modelo EconometriaRobert MellaNo ratings yet
- Evaluacion de Supuestos PDFDocument27 pagesEvaluacion de Supuestos PDFDante Palacios ValdiviezoNo ratings yet
- Microsoft Word - CEDEAC-03Document39 pagesMicrosoft Word - CEDEAC-03Angie AlarconNo ratings yet
- Multiplicadores de Lagrange y Ajustes de CurvasDocument15 pagesMultiplicadores de Lagrange y Ajustes de CurvasMajo :3No ratings yet
- PortafolioU2HCIQ7WP 20041167GarcíaYeimiDocument30 pagesPortafolioU2HCIQ7WP 20041167GarcíaYeimiYeimi Alejandra García RodríguezNo ratings yet
- Clase 9 Modelos de Ecuaciones SimultaneasDocument34 pagesClase 9 Modelos de Ecuaciones Simultaneaswill_ich23No ratings yet
- Tarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadDocument6 pagesTarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadmargaritaNo ratings yet
- Taller EconometriaDocument8 pagesTaller EconometriaDayana HernandezNo ratings yet
- Transformación lineal directa: Aplicaciones prácticas y técnicas en visión por computadora.From EverandTransformación lineal directa: Aplicaciones prácticas y técnicas en visión por computadora.No ratings yet
- Matriz de ConsistenciaDocument2 pagesMatriz de ConsistenciahotmailNo ratings yet
- Sap InformaticaDocument88 pagesSap InformaticahotmailNo ratings yet
- Nic 12Document25 pagesNic 12hotmail100% (1)
- Fundamento Teorico Referido Al SoftwareDocument17 pagesFundamento Teorico Referido Al SoftwarehotmailNo ratings yet
- Contrato Modelo Alquiler Plaza GarajeDocument6 pagesContrato Modelo Alquiler Plaza GarajeJoseNo ratings yet
- Sabina Araos S, Tarea Semana 6 EstadisticaDocument6 pagesSabina Araos S, Tarea Semana 6 Estadisticasabina araosNo ratings yet
- Casanova Carranza-Examen GeoestadísticaDocument9 pagesCasanova Carranza-Examen GeoestadísticaCARLOS HARRISON CASANOVA CARRANZANo ratings yet
- Asimetria Curtosis Jarque BeraDocument12 pagesAsimetria Curtosis Jarque BeraSeidy SaraguroNo ratings yet
- Ejercicios de ANOVADocument9 pagesEjercicios de ANOVAAlonzo Vega MontezaNo ratings yet
- Triptico de EstadisticaDocument3 pagesTriptico de EstadisticaAlexis RNo ratings yet
- Modelo de Distribución de Pérdidas Agregadas PDFDocument25 pagesModelo de Distribución de Pérdidas Agregadas PDFBismarck RivasNo ratings yet
- Precisión y ExactitudDocument7 pagesPrecisión y ExactitudFernandoNo ratings yet
- 20130507-Syllabus 2012-2 Eco781 Econometria Avanzada Series de TiempoDocument22 pages20130507-Syllabus 2012-2 Eco781 Econometria Avanzada Series de TiempoGuillermo ApazaNo ratings yet
- Taller 9 Noviembre-2019 PDFDocument6 pagesTaller 9 Noviembre-2019 PDFAndres Felipe CamachoNo ratings yet
- Cronograma 2018-1: Probabilidad e Inferencia EstadísticaDocument1 pageCronograma 2018-1: Probabilidad e Inferencia EstadísticasamuelNo ratings yet
- Unidad IV Muestreo EstadisticoDocument60 pagesUnidad IV Muestreo EstadisticoCosmetic Elhen GLNo ratings yet
- Distribución T de StudentDocument6 pagesDistribución T de StudentGilberto CarbajalNo ratings yet
- 2017 - Estimasion de ParametrosDocument27 pages2017 - Estimasion de Parametrosyannick chavezNo ratings yet
- Aplicaciones Distribuciones de ProbabilidadDocument51 pagesAplicaciones Distribuciones de ProbabilidadCarlos JuárezNo ratings yet
- Estadistica InferenciaDocument17 pagesEstadistica Inferencia01-II-HU-KEVIN ALEX CAISAHUANA CAINICELANo ratings yet
- Fase 5 Preguntas Orientadoras LCDocument11 pagesFase 5 Preguntas Orientadoras LCAndres ManosalvaNo ratings yet
- Rene Araneda Control.7Document5 pagesRene Araneda Control.7Luciano AranedaNo ratings yet
- Ana Fact ClaseDocument62 pagesAna Fact ClaseAldo Martín FernándezNo ratings yet
- Estadistica EjerciciosDocument4 pagesEstadistica EjerciciosOscar RamosNo ratings yet
- LAB-8 Inductancia 2Document6 pagesLAB-8 Inductancia 2RICARDO SERGIO QUISBERT VILLCANo ratings yet
- Solucionario Practica Distribuciones de Probabilidad PDFDocument21 pagesSolucionario Practica Distribuciones de Probabilidad PDFIgnacio Cuevas RomaniNo ratings yet
- Tarea Unidad 2 Fase 3Document17 pagesTarea Unidad 2 Fase 3DALVER MORENONo ratings yet
- Binomial y Poisson-1Document96 pagesBinomial y Poisson-1Hiromi YacilaNo ratings yet
- Proyecto de IsabelDocument22 pagesProyecto de Isabelrene hackerproNo ratings yet
- 1 Estimación de Intervalos de Confianza y Prueba de HipotesisDocument73 pages1 Estimación de Intervalos de Confianza y Prueba de HipotesisKelly Johana Caicedo ZamoraNo ratings yet
- Trabajo Práctico en Equipo Nº7Document1 pageTrabajo Práctico en Equipo Nº7Ricardo MLNo ratings yet
- Gua 1.solucionario de Estadstica InferencialDocument17 pagesGua 1.solucionario de Estadstica Inferencialmstl777No ratings yet
- Clases13 14 Serie Tiempo1Document43 pagesClases13 14 Serie Tiempo1Matías SilvaNo ratings yet
- Ensayo Pruebas de Hipotesis y Intervalos de ConfianzaDocument22 pagesEnsayo Pruebas de Hipotesis y Intervalos de ConfianzaFocus Led SAS100% (1)
- Ejercicios Distribución Binomial PDFDocument3 pagesEjercicios Distribución Binomial PDFSalomon Jara SouzaNo ratings yet