You might also like
- Two-Degree-of-Freedom Control Systems: The Youla Parameterization ApproachFrom EverandTwo-Degree-of-Freedom Control Systems: The Youla Parameterization ApproachNo ratings yet
- RoprobitDocument6 pagesRoprobitAmoussouNo ratings yet
- Constraint Networks: Targeting Simplicity for Techniques and AlgorithmsFrom EverandConstraint Networks: Targeting Simplicity for Techniques and AlgorithmsNo ratings yet
- RmprobitDocument8 pagesRmprobitlompoNo ratings yet
- Poisson RegressionDocument10 pagesPoisson RegressionUNLV234No ratings yet
- RlrtestDocument10 pagesRlrtestFiraa'ol GizaachooNo ratings yet
- RtobitDocument7 pagesRtobitvolkanNo ratings yet
- XtxttobitDocument9 pagesXtxttobitGuivis ZeufackNo ratings yet
- RbiprobitDocument8 pagesRbiprobitDaniel Redel SaavedraNo ratings yet
- Bivariate Probit RegressionDocument7 pagesBivariate Probit RegressionnovanikarineNo ratings yet
- SAS Annotated OutputDocument8 pagesSAS Annotated OutputzknightvnNo ratings yet
- TsvarDocument12 pagesTsvartayson1212No ratings yet
- Logit MultinomialDocument16 pagesLogit MultinomialBruno BaiaNo ratings yet
- Regression models: ∼ N (µ, φ) µ Y ∼ P (µ, φ) g (µ) = XβDocument6 pagesRegression models: ∼ N (µ, φ) µ Y ∼ P (µ, φ) g (µ) = XβokeitNo ratings yet
- RfrontierDocument15 pagesRfrontierzainurihanifNo ratings yet
- 91 OrdlogisticDocument4 pages91 OrdlogisticChristian Bosch TaylanNo ratings yet
- Xtregar - Fixed-And Random-Effects Linear Models With An AR (1) DisturbanceDocument15 pagesXtregar - Fixed-And Random-Effects Linear Models With An AR (1) DisturbanceDiego Armando Pérez ReséndizNo ratings yet
- R MaximizeDocument7 pagesR MaximizeMariia SungatullinaNo ratings yet
- Rologit PDFDocument9 pagesRologit PDFAnonymous rqqljZ5No ratings yet
- Simulation of Insurance Data With ActuarDocument14 pagesSimulation of Insurance Data With ActuarLuis MoreyraNo ratings yet
- Ayuda Comandos Stata MetaDocument42 pagesAyuda Comandos Stata Metaread03541No ratings yet
- Regression Diagnostics With R: Anne BoomsmaDocument23 pagesRegression Diagnostics With R: Anne BoomsmagredondoNo ratings yet
- RstepwiseDocument11 pagesRstepwisePROUD THE LEGENDSNo ratings yet
- Getting Started in Logit and Ordered Logit Regression: (Ver. 3.1 Beta)Document14 pagesGetting Started in Logit and Ordered Logit Regression: (Ver. 3.1 Beta)Siti MasfiahNo ratings yet
- XtxtmlogitDocument31 pagesXtxtmlogitAmoussouNo ratings yet
- Unit 6Document9 pagesUnit 6satish kumarNo ratings yet
- PSF Models in StataDocument14 pagesPSF Models in StataalkrasNo ratings yet
- CH 07Document92 pagesCH 07Chafia ChabiNo ratings yet
- Marginal EffectsDocument16 pagesMarginal EffectsAmol GajdhaneNo ratings yet
- Simulate - Monte Carlo Simulations: FilenameDocument7 pagesSimulate - Monte Carlo Simulations: FilenameAndxp51No ratings yet
- RzinbDocument9 pagesRzinbGeetha JayaramanNo ratings yet
- Unit 6Document8 pagesUnit 6Mahesh GandikotaNo ratings yet
- Cens RegDocument12 pagesCens RegLucía AndreozziNo ratings yet
- CHAPTER 3 Multiple Linear RegressionDocument35 pagesCHAPTER 3 Multiple Linear RegressionFakhrulShahrilEzanieNo ratings yet
- RbetaregDocument10 pagesRbetaregBaron BulayaNo ratings yet
- Advanced RegressionDocument13 pagesAdvanced RegressionDaniel N Sherine FooNo ratings yet
- 8 Probability Distributions: 8.1 R As A Set of Statistical TablesDocument6 pages8 Probability Distributions: 8.1 R As A Set of Statistical TablessansantoshNo ratings yet
- 05 Diagnostic Test of CLRM 2Document39 pages05 Diagnostic Test of CLRM 2Inge AngeliaNo ratings yet
- R Heck Man Post EstimationDocument6 pagesR Heck Man Post EstimationRaul GonzalesNo ratings yet
- Simulation of Compound Hierarchical ModelsDocument9 pagesSimulation of Compound Hierarchical ModelsEdwin Quevedo QuispeNo ratings yet
- Logit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaDocument24 pagesLogit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaManoj PaliwalNo ratings yet
- Using R For Linear RegressionDocument9 pagesUsing R For Linear RegressionMohar SenNo ratings yet
- Logit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaDocument27 pagesLogit, Probit and Multinomial Logit Models in R: Oscar Torres-ReynaEsperanzaDazaNo ratings yet
- Sensitivity Analysis Toolbox For DYNAREDocument12 pagesSensitivity Analysis Toolbox For DYNARESEBASTIAN DAVID GARCIA ECHEVERRYNo ratings yet
- UsersGuide BayesFactorBinaryDocument10 pagesUsersGuide BayesFactorBinaryAri Surya AbdiNo ratings yet
- The Mvtnorm Package: R Topics DocumentedDocument12 pagesThe Mvtnorm Package: R Topics DocumentedDavid HumphreyNo ratings yet
- Cheat Sheet FinalDocument7 pagesCheat Sheet Finalkookmasteraj100% (2)
- Chapter 7. Software ApplicationDocument43 pagesChapter 7. Software Applicationberhanu seyoumNo ratings yet
- Lab4 Orthogonal Contrasts and Multiple ComparisonsDocument14 pagesLab4 Orthogonal Contrasts and Multiple ComparisonsjorbelocoNo ratings yet
- Fortran 2023Document25 pagesFortran 2023Jose ArceNo ratings yet
- Estimating A VAR - GretlDocument9 pagesEstimating A VAR - Gretlkaddour7108No ratings yet
- The LIFEREG ProcedureDocument39 pagesThe LIFEREG ProcedurekishoreparasaNo ratings yet
- 5 RegressionDocument48 pages5 RegressionRosemary BorgesNo ratings yet
- BayesbayesxtregDocument4 pagesBayesbayesxtregBelaynehYitayewNo ratings yet
- Package Fanc': R Topics DocumentedDocument9 pagesPackage Fanc': R Topics DocumentedRonan ReisNo ratings yet
- Package CMPRSK': R Topics DocumentedDocument13 pagesPackage CMPRSK': R Topics DocumentedNavnath GodseNo ratings yet
- Linear and Generalized Linear Models: Nicholas Christian BIOST 2094 Spring 2011Document22 pagesLinear and Generalized Linear Models: Nicholas Christian BIOST 2094 Spring 2011Sandeep PanNo ratings yet
- Lectura 3 MLEDocument33 pagesLectura 3 MLEAlejandro MarinNo ratings yet
- Using More Than One Explanatory Variable (Ch. 4)Document5 pagesUsing More Than One Explanatory Variable (Ch. 4)jessicaNo ratings yet
- CLM ArticleDocument40 pagesCLM Articlerico.caballero7No ratings yet
- What Is Earnings SeasonDocument4 pagesWhat Is Earnings SeasonUNLV234No ratings yet
- What Is The SampP 500 How Does It WorkDocument5 pagesWhat Is The SampP 500 How Does It WorkUNLV234No ratings yet
- Fixed-Income Basics What Is A BondDocument7 pagesFixed-Income Basics What Is A BondUNLV234No ratings yet
- Earnings Reports What Do Quarterly Earnings Tell YouDocument5 pagesEarnings Reports What Do Quarterly Earnings Tell YouUNLV234No ratings yet
- Building A First Year Information Literacy Experience in - 2011 - The Journal oDocument12 pagesBuilding A First Year Information Literacy Experience in - 2011 - The Journal oUNLV234No ratings yet
- Change in Beliefs After First Year of Teaching - 2009 - International Journal oDocument10 pagesChange in Beliefs After First Year of Teaching - 2009 - International Journal oUNLV234No ratings yet
- How Database B-Tree Indexing WorksDocument8 pagesHow Database B-Tree Indexing WorksUNLV234No ratings yet
- Association Between First Depressive Episode in The Sam 2020 Journal of AdolDocument6 pagesAssociation Between First Depressive Episode in The Sam 2020 Journal of AdolUNLV234No ratings yet
- A Comparison of On Campus First Year Undergraduate Nursing S 2006 Nurse EducDocument7 pagesA Comparison of On Campus First Year Undergraduate Nursing S 2006 Nurse EducUNLV234No ratings yet
- Teaching and Teacher Education: Kristine Høeg Karlsen, Virginia Lockhart-Pedersen, Gunhild Brænne BjørnstadDocument10 pagesTeaching and Teacher Education: Kristine Høeg Karlsen, Virginia Lockhart-Pedersen, Gunhild Brænne BjørnstadUNLV234No ratings yet
- Association Between First Depressive Episode in The Sam 2020 Journal of AdolDocument6 pagesAssociation Between First Depressive Episode in The Sam 2020 Journal of AdolUNLV234No ratings yet
- Book Review - The First Year Experience Cookbook R Pun - 2017 - The JournalDocument1 pageBook Review - The First Year Experience Cookbook R Pun - 2017 - The JournalUNLV234No ratings yet
- Challenging The Notion of The Transition Year TH - 2016 - International JournalDocument10 pagesChallenging The Notion of The Transition Year TH - 2016 - International JournalUNLV234No ratings yet
- A Survey of First Year Student Nurses Experiences of 2009 Nurse EducationDocument11 pagesA Survey of First Year Student Nurses Experiences of 2009 Nurse EducationUNLV234No ratings yet
- Australian Final Year Nursing Students and Registered Nurse 2018 Nurse EducDocument6 pagesAustralian Final Year Nursing Students and Registered Nurse 2018 Nurse EducUNLV234No ratings yet
- Are Digital Natives A World Wide Phenomenon An Investigation 2010 ComputersDocument9 pagesAre Digital Natives A World Wide Phenomenon An Investigation 2010 ComputersUNLV234No ratings yet
- Australian Final Year Nursing Students and Registered Nurse 2018 Nurse EducDocument6 pagesAustralian Final Year Nursing Students and Registered Nurse 2018 Nurse EducUNLV234No ratings yet
- Adverse Childhood Experiences ACEs Research A Bibliometri 2021 Child AbusDocument10 pagesAdverse Childhood Experiences ACEs Research A Bibliometri 2021 Child AbusUNLV234No ratings yet
- A Survey of First Year Student Nurses Experiences of 2009 Nurse EducationDocument11 pagesA Survey of First Year Student Nurses Experiences of 2009 Nurse EducationUNLV234No ratings yet
- A Novice Teachers Teacher Identity Construction During 2021 Learning CulturDocument12 pagesA Novice Teachers Teacher Identity Construction During 2021 Learning CulturUNLV234No ratings yet
- Architects Renovators Builders and Fragmenters A Mod 2019 The Journal ofDocument8 pagesArchitects Renovators Builders and Fragmenters A Mod 2019 The Journal ofUNLV234No ratings yet
- Book Review - The First Year Experience Cookbook R Pun - 2017 - The JournalDocument1 pageBook Review - The First Year Experience Cookbook R Pun - 2017 - The JournalUNLV234No ratings yet
- Amsterdam You Re Raining First Hand Experience in Twe 2021 Journal of PRDocument13 pagesAmsterdam You Re Raining First Hand Experience in Twe 2021 Journal of PRUNLV234No ratings yet
- Amsterdam You Re Raining First Hand Experience in Twe 2021 Journal of PRDocument13 pagesAmsterdam You Re Raining First Hand Experience in Twe 2021 Journal of PRUNLV234No ratings yet
- Sorkin CVDocument2 pagesSorkin CVUNLV234No ratings yet
- A Comparison of On Campus First Year Undergraduate Nursing S 2006 Nurse EducDocument7 pagesA Comparison of On Campus First Year Undergraduate Nursing S 2006 Nurse EducUNLV234No ratings yet
- Adverse Childhood Experiences ACEs Research A Bibliometri 2021 Child AbusDocument10 pagesAdverse Childhood Experiences ACEs Research A Bibliometri 2021 Child AbusUNLV234No ratings yet
- Architects Renovators Builders and Fragmenters A Mod 2019 The Journal ofDocument8 pagesArchitects Renovators Builders and Fragmenters A Mod 2019 The Journal ofUNLV234No ratings yet
- A Novice Teachers Teacher Identity Construction During 2021 Learning CulturDocument12 pagesA Novice Teachers Teacher Identity Construction During 2021 Learning CulturUNLV234No ratings yet
- CSUSBprogressreportDec2017 0Document11 pagesCSUSBprogressreportDec2017 0UNLV234No ratings yet
- Crime Data Analysis 1Document2 pagesCrime Data Analysis 1kenny laroseNo ratings yet
- Acute Renal Failure in The Intensive Care Unit: Steven D. Weisbord, M.D., M.Sc. and Paul M. Palevsky, M.DDocument12 pagesAcute Renal Failure in The Intensive Care Unit: Steven D. Weisbord, M.D., M.Sc. and Paul M. Palevsky, M.Dkerm6991No ratings yet
- Unit 8 Packet KeyDocument21 pagesUnit 8 Packet KeyHiddenNo ratings yet
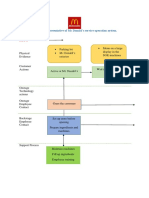
- Blueprint Huynh My Ky Duyen 2022 McDonald'sDocument2 pagesBlueprint Huynh My Ky Duyen 2022 McDonald'sHuỳnh Mỹ Kỳ DuyênNo ratings yet
- S ELITE Nina Authors Certain Ivey This Reproduce Western Material Management Gupta Names Do OntarioDocument15 pagesS ELITE Nina Authors Certain Ivey This Reproduce Western Material Management Gupta Names Do Ontariocarlos menaNo ratings yet
- MSDS - Granular Silica GelDocument3 pagesMSDS - Granular Silica GelLailal HaqimNo ratings yet
- A Critical Appreciation of Ode To NightingaleDocument3 pagesA Critical Appreciation of Ode To NightingaleBaloch Karawan100% (2)
- Chemical Quick Guide PDFDocument1 pageChemical Quick Guide PDFAndrejs ZundaNo ratings yet
- Doctors ListDocument212 pagesDoctors ListSaranya Chandrasekar33% (3)
- EXP 2 - Plug Flow Tubular ReactorDocument18 pagesEXP 2 - Plug Flow Tubular ReactorOng Jia YeeNo ratings yet
- Latest Low NOx Combustion TechnologyDocument7 pagesLatest Low NOx Combustion Technology95113309No ratings yet
- Bio411 C1Document1 pageBio411 C1Aqiena BalqisNo ratings yet
- Castle 1-3K E ManualDocument26 pagesCastle 1-3K E ManualShami MudunkotuwaNo ratings yet
- Engineering Project ListDocument25 pagesEngineering Project ListSyed ShaNo ratings yet
- A Project Report On A Study On Amul Taste of India: Vikash Degree College Sambalpur University, OdishaDocument32 pagesA Project Report On A Study On Amul Taste of India: Vikash Degree College Sambalpur University, OdishaSonu PradhanNo ratings yet
- G1 Series User Manual Ver. 1.2Document101 pagesG1 Series User Manual Ver. 1.2unedo parhusip100% (1)
- Pengaruh Kualitas Anc Dan Riwayat Morbiditas Maternal Terhadap Morbiditas Maternal Di Kabupaten SidoarjoDocument9 pagesPengaruh Kualitas Anc Dan Riwayat Morbiditas Maternal Terhadap Morbiditas Maternal Di Kabupaten Sidoarjohikmah899No ratings yet
- Thesis ProposalDocument19 pagesThesis Proposaldharmi subedi75% (4)
- 2005 Harley Davidson Sportster 883 66418Document136 pages2005 Harley Davidson Sportster 883 66418Josef Bruno SchlittenbauerNo ratings yet
- Finite Element Analysis Project ReportDocument22 pagesFinite Element Analysis Project ReportsaurabhNo ratings yet
- Bedwetting TCMDocument5 pagesBedwetting TCMRichonyouNo ratings yet
- Narrative Report On Weekly Accomplishments: Department of EducationDocument2 pagesNarrative Report On Weekly Accomplishments: Department of Educationisha mariano100% (1)
- TraceGains Inspection Day FDA Audit ChecklistDocument2 pagesTraceGains Inspection Day FDA Audit Checklistdrs_mdu48No ratings yet
- Chapter 2 and 3 ImmunologyDocument16 pagesChapter 2 and 3 ImmunologyRevathyNo ratings yet
- 6 Kuliah Liver CirrhosisDocument55 pages6 Kuliah Liver CirrhosisAnonymous vUEDx8100% (1)
- "Next Friend" and "Guardian Ad Litem" - Difference BetweenDocument1 page"Next Friend" and "Guardian Ad Litem" - Difference BetweenTeh Hong Xhe100% (2)
- United States v. Victor Vallin-Jauregui, 4th Cir. (2013)Document4 pagesUnited States v. Victor Vallin-Jauregui, 4th Cir. (2013)Scribd Government DocsNo ratings yet
- Inducement of Rapid Analysis For Determination of Reactive Silica and Available Alumina in BauxiteDocument11 pagesInducement of Rapid Analysis For Determination of Reactive Silica and Available Alumina in BauxiteJAFAR MUHAMMADNo ratings yet
- Business Plan Example - Little LearnerDocument26 pagesBusiness Plan Example - Little LearnerCourtney mcintosh100% (1)
- Advances of Family Apocynaceae A Review - 2017Document30 pagesAdvances of Family Apocynaceae A Review - 2017Владимир ДружининNo ratings yet
- The 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessageFrom EverandThe 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessageRating: 5 out of 5 stars5/5 (73)
- How to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipFrom EverandHow to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipRating: 4.5 out of 5 stars4.5/5 (1135)
- Weapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingFrom EverandWeapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingRating: 4.5 out of 5 stars4.5/5 (149)
- Summary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisFrom EverandSummary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisRating: 5 out of 5 stars5/5 (15)
- Summary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisFrom EverandSummary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisRating: 4.5 out of 5 stars4.5/5 (22)
- Summary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisFrom EverandSummary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisRating: 4.5 out of 5 stars4.5/5 (30)
- Learn Spanish While SleepingFrom EverandLearn Spanish While SleepingRating: 4 out of 5 stars4/5 (20)
- Make It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningFrom EverandMake It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningRating: 4.5 out of 5 stars4.5/5 (55)
- Little Soldiers: An American Boy, a Chinese School, and the Global Race to AchieveFrom EverandLittle Soldiers: An American Boy, a Chinese School, and the Global Race to AchieveRating: 4 out of 5 stars4/5 (25)
- How to Improve English Speaking: How to Become a Confident and Fluent English SpeakerFrom EverandHow to Improve English Speaking: How to Become a Confident and Fluent English SpeakerRating: 4.5 out of 5 stars4.5/5 (56)
- Stoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionFrom EverandStoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionRating: 5 out of 5 stars5/5 (51)
- Dumbing Us Down: The Hidden Curriculum of Compulsory SchoolingFrom EverandDumbing Us Down: The Hidden Curriculum of Compulsory SchoolingRating: 4.5 out of 5 stars4.5/5 (497)
- The Story of the World, Vol. 1 AudiobookFrom EverandThe Story of the World, Vol. 1 AudiobookRating: 4.5 out of 5 stars4.5/5 (3)
- Summary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisFrom EverandSummary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisRating: 4.5 out of 5 stars4.5/5 (2)
- Summary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisFrom EverandSummary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisRating: 5 out of 5 stars5/5 (3)
- Summary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisFrom EverandSummary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisRating: 4 out of 5 stars4/5 (6)
- Why Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativeFrom EverandWhy Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativeRating: 3.5 out of 5 stars3.5/5 (54)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Learn Japanese - Level 1: Introduction to Japanese, Volume 1: Volume 1: Lessons 1-25From EverandLearn Japanese - Level 1: Introduction to Japanese, Volume 1: Volume 1: Lessons 1-25Rating: 5 out of 5 stars5/5 (17)
- Follow The Leader: A Collection Of The Best Lectures On LeadershipFrom EverandFollow The Leader: A Collection Of The Best Lectures On LeadershipRating: 5 out of 5 stars5/5 (122)
- Summary: Atlas of the Heart: Mapping Meaningful Connection and the Language of Human Experience by Brené Brown: Key Takeaways, Summary & AnalysisFrom EverandSummary: Atlas of the Heart: Mapping Meaningful Connection and the Language of Human Experience by Brené Brown: Key Takeaways, Summary & AnalysisRating: 5 out of 5 stars5/5 (4)
- Learn English: Must-Know American English Slang Words & Phrases (Extended Version)From EverandLearn English: Must-Know American English Slang Words & Phrases (Extended Version)Rating: 5 out of 5 stars5/5 (30)
- You Are Not Special: And Other EncouragementsFrom EverandYou Are Not Special: And Other EncouragementsRating: 4.5 out of 5 stars4.5/5 (6)
- Learn French: The Essentials You Need to Go From an Absolute Beginner to Intermediate and AdvancedFrom EverandLearn French: The Essentials You Need to Go From an Absolute Beginner to Intermediate and AdvancedNo ratings yet
- Summary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisFrom EverandSummary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisRating: 5 out of 5 stars5/5 (2)