You might also like
- Improving Multimedia Retrieval With A Video OCRDocument12 pagesImproving Multimedia Retrieval With A Video OCRSujayCjNo ratings yet
- Icpr 2010Document4 pagesIcpr 2010eesaahNo ratings yet
- A Robust and Fast Text Extraction in Images and Video FramesDocument7 pagesA Robust and Fast Text Extraction in Images and Video FramesvandanaNo ratings yet
- Text Detection and Recognition Using Enhanced MSER Detection and A Novel OCR TechniqueDocument7 pagesText Detection and Recognition Using Enhanced MSER Detection and A Novel OCR TechniqueLeonardusNo ratings yet
- Curved Scene Text Detection Based On Mask R-CNNDocument13 pagesCurved Scene Text Detection Based On Mask R-CNNRajeshwari R PNo ratings yet
- Robust Text Detection in Natural Images With Edge-Enhanced Maximally Stable Extremal RegionsDocument4 pagesRobust Text Detection in Natural Images With Edge-Enhanced Maximally Stable Extremal Regionssatishkumar697No ratings yet
- Ancient Text Character Recognition Using Deep Learning: Shikhachadha, Dr. Sonumittal and Dr. Vivek SinghalDocument8 pagesAncient Text Character Recognition Using Deep Learning: Shikhachadha, Dr. Sonumittal and Dr. Vivek SinghalHarish GanapathyNo ratings yet
- Automatically Detect and Recognize Text in Natural ImagesDocument19 pagesAutomatically Detect and Recognize Text in Natural ImagesStudent 188X1A04D0No ratings yet
- Word Spotting and Recognition Using Deep EmbeddingDocument6 pagesWord Spotting and Recognition Using Deep EmbeddingSunil ChaluvaiahNo ratings yet
- Extracting Text From VideosDocument11 pagesExtracting Text From VideosAbhijeet ChattarjeeNo ratings yet
- Spatio-Temporal Dynamics and Semantic Attributes for Video CaptioningDocument10 pagesSpatio-Temporal Dynamics and Semantic Attributes for Video Captioningford ferrariNo ratings yet
- Scene Text Detection With Fully Convolutional Neural NetworksDocument23 pagesScene Text Detection With Fully Convolutional Neural NetworksRajeshwari R PNo ratings yet
- Content Based Image Retrieval Using Feature CodingDocument4 pagesContent Based Image Retrieval Using Feature CodingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- JournalNX - Textual Content Video StreamDocument5 pagesJournalNX - Textual Content Video StreamJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Classification of Urdu Ligatures Using Convolutional Neural Networks - A Novel ApproachDocument5 pagesClassification of Urdu Ligatures Using Convolutional Neural Networks - A Novel Approachzaki zakiNo ratings yet
- Ijecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)Document8 pagesIjecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)IAEME PublicationNo ratings yet
- Segmentation and Extraction of Text From Curved Text Lines Using Image Processing ApproachDocument5 pagesSegmentation and Extraction of Text From Curved Text Lines Using Image Processing ApproachAkai ShuichiNo ratings yet
- Key Word of AllDocument6 pagesKey Word of AllSunil ChaluvaiahNo ratings yet
- High-Level Concept Detection in VideoDocument11 pagesHigh-Level Concept Detection in VideoNeha GundreNo ratings yet
- Scene Text Detection and Segmentation Based OnDocument12 pagesScene Text Detection and Segmentation Based OnHitechNo ratings yet
- Siddiqua 2019Document5 pagesSiddiqua 2019Madhurima KVNo ratings yet
- Last Vergen ReportsDocument26 pagesLast Vergen ReportsAbeer.mmm4746No ratings yet
- Efficient and Robust Detection of Duplicate Videos in A DatabaseDocument4 pagesEfficient and Robust Detection of Duplicate Videos in A DatabaseEditor IJRITCCNo ratings yet
- Investigating The Effect of Bd-Craft To Text Detection AlgorithmsDocument16 pagesInvestigating The Effect of Bd-Craft To Text Detection AlgorithmsAdam HansenNo ratings yet
- Research - Paper-2 (Img To Text)Document159 pagesResearch - Paper-2 (Img To Text)Taraka Manjunatha TNo ratings yet
- An Evaluation of Various Pre-Trained Optical Character Recognition Models For Complex License PlatesDocument7 pagesAn Evaluation of Various Pre-Trained Optical Character Recognition Models For Complex License Plates1181103201No ratings yet
- Optimized and Efficient Color Prediction AlgorithmDocument25 pagesOptimized and Efficient Color Prediction Algorithmshivamnna07No ratings yet
- Learning Robust Feature Representations For Scene Text DetectionDocument10 pagesLearning Robust Feature Representations For Scene Text DetectionMinh Đinh NhậtNo ratings yet
- Ijcse - Creation of Arab Graphic Writings Recognition ProgramDocument10 pagesIjcse - Creation of Arab Graphic Writings Recognition ProgramImpact JournalsNo ratings yet
- TCS OcrDocument39 pagesTCS OcrThrow AwayNo ratings yet
- Comparative Evaluation of CNN Architectures for Image Caption GenerationDocument9 pagesComparative Evaluation of CNN Architectures for Image Caption Generationsebampitako duncanNo ratings yet
- Devnagari Char Recognition PDFDocument4 pagesDevnagari Char Recognition PDFSaroj SahooNo ratings yet
- Algorithm For Translation of Texts in Images Taken With A SmartphoneDocument9 pagesAlgorithm For Translation of Texts in Images Taken With A SmartphoneCentral Asian StudiesNo ratings yet
- Title: Spatial Cohesion Refers To The Fact That TextDocument6 pagesTitle: Spatial Cohesion Refers To The Fact That TextVigneshInfotechNo ratings yet
- Neural Matching Fields ImpliciDocument14 pagesNeural Matching Fields ImpliciAhmed AbbasNo ratings yet
- Scene Text Recognition Using Co-Occurrence of Histogram of Oriented GradientsDocument5 pagesScene Text Recognition Using Co-Occurrence of Histogram of Oriented GradientslikufaneleNo ratings yet
- High Efficiency Video Coding With Content Split Block Search Algorithm and Hybrid Wavelet TransformDocument7 pagesHigh Efficiency Video Coding With Content Split Block Search Algorithm and Hybrid Wavelet TransformSai Kumar YadavNo ratings yet
- Accuracy Augmentation of Tamil OCR Using Algorithm FusionDocument6 pagesAccuracy Augmentation of Tamil OCR Using Algorithm FusionsubakishaanNo ratings yet
- Comparative Evaluation of CNN Architectures For Image Caption GenerationDocument9 pagesComparative Evaluation of CNN Architectures For Image Caption GenerationInstaNo ratings yet
- VD1010Document9 pagesVD1010Edward AysonNo ratings yet
- Optical Character Recognition Based Speech Synthesis: Project ReportDocument17 pagesOptical Character Recognition Based Speech Synthesis: Project Reportisoi0% (1)
- Assignment 1 NFDocument6 pagesAssignment 1 NFKhondoker Abu NaimNo ratings yet
- Auto Jotting: A Notes MakerDocument11 pagesAuto Jotting: A Notes MakerIJRASETPublicationsNo ratings yet
- Lip2 Speech ReportDocument7 pagesLip2 Speech Reportshivammittal200.smNo ratings yet
- Aic - 2022 - 35 2 - Aic 35 2 Aic210172 - Aic 35 Aic210172Document19 pagesAic - 2022 - 35 2 - Aic 35 2 Aic210172 - Aic 35 Aic210172mohamed walidNo ratings yet
- DownloadDocument5 pagesDownloadsantiago gonzalezNo ratings yet
- Legal Amount Recognition in Bank Cheques Using CapsuleDocument22 pagesLegal Amount Recognition in Bank Cheques Using CapsuleManeesh DarisiNo ratings yet
- (IJCST-V10I4P20) :khanaghavalle G R, Arvind Nachiappan L, Bharath Vyas S, Chaitanya MDocument5 pages(IJCST-V10I4P20) :khanaghavalle G R, Arvind Nachiappan L, Bharath Vyas S, Chaitanya MEighthSenseGroupNo ratings yet
- Video To SequenceDocument9 pagesVideo To SequenceUtkarsh SaxenaNo ratings yet
- Localizing Text On VideosDocument13 pagesLocalizing Text On VideosAbhijeet ChattarjeeNo ratings yet
- Matecconf Eitce2018 02038 SRC Code DetectorDocument6 pagesMatecconf Eitce2018 02038 SRC Code DetectorSaad AfridiNo ratings yet
- Marathi Numeral Identification System inDocument9 pagesMarathi Numeral Identification System inRadhe GovindaNo ratings yet
- Ligature-Based Font Size Independent OCR For Noori Nastalique Writing StyleDocument5 pagesLigature-Based Font Size Independent OCR For Noori Nastalique Writing Stylezaki zakiNo ratings yet
- HRWDocument28 pagesHRWGLOBAL INFO-TECH KUMBAKONAMNo ratings yet
- Official Logo Recognition Based On Multilayer Convolutional Neural Network ModelDocument8 pagesOfficial Logo Recognition Based On Multilayer Convolutional Neural Network ModelTELKOMNIKANo ratings yet
- Action Recognition Using Hierarchical Dynamic Bayesian NetworkDocument14 pagesAction Recognition Using Hierarchical Dynamic Bayesian Networkart queenNo ratings yet
- Robustdetection of Text in Natural Scene ImagesDocument4 pagesRobustdetection of Text in Natural Scene ImagesJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Bar Code Reading From Images Captured by Camera Phones: Figure 1: Diagram of The Bar Code Decoding SystemDocument6 pagesBar Code Reading From Images Captured by Camera Phones: Figure 1: Diagram of The Bar Code Decoding SystemPrashanth PrashuNo ratings yet
- Gurumukhi Text Hiding Using Steganography in Video: Bharti Chandel Shaily JainDocument6 pagesGurumukhi Text Hiding Using Steganography in Video: Bharti Chandel Shaily JainDuddukuri SrikarNo ratings yet
- EigenvaluesDocument31 pagesEigenvaluesFiza HusainNo ratings yet
- Covariance PDFDocument9 pagesCovariance PDFsaymen GetachewNo ratings yet
- Sample LetterDocument1 pageSample Lettermohammed habeeb VullaNo ratings yet
- Maxwell's Equations: q d ε d d d dt d d μ ε μ dtDocument25 pagesMaxwell's Equations: q d ε d d d dt d d μ ε μ dtmohammed habeeb VullaNo ratings yet
- Data Science SyllabusDocument3 pagesData Science Syllabusmohammed habeeb VullaNo ratings yet
- BEL Interview Details for Probationary Engineer PositionDocument1 pageBEL Interview Details for Probationary Engineer PositionShubham MittalNo ratings yet
- Beginners Python Cheat Sheet PCC All PDFDocument26 pagesBeginners Python Cheat Sheet PCC All PDFName100% (1)
- Letters of RecommendDocument7 pagesLetters of RecommendRajesh AgarwalNo ratings yet
- AP Transco Sub Engineer Question Paper SET-ADocument16 pagesAP Transco Sub Engineer Question Paper SET-AVanitha Pillai KNo ratings yet
- Adaptive 2015 3 10 50047Document7 pagesAdaptive 2015 3 10 50047mohammed habeeb VullaNo ratings yet
- ADC and DAC Converters ExplainedDocument5 pagesADC and DAC Converters ExplainedMatthew AlexanderNo ratings yet
- DR Robot C Sharp Advanced Sentinel II Demo ProgramDocument16 pagesDR Robot C Sharp Advanced Sentinel II Demo Programmohammed habeeb VullaNo ratings yet
- DR Robot C# Advance Sample Program General Function IntroductionDocument15 pagesDR Robot C# Advance Sample Program General Function Introductionmohammed habeeb VullaNo ratings yet
- JSPDocument19 pagesJSPmohammed habeeb VullaNo ratings yet
- JSPDocument19 pagesJSPmohammed habeeb VullaNo ratings yet
- JSP Intro and OverviewDocument5 pagesJSP Intro and Overviewmohammed habeeb VullaNo ratings yet
- Iqip Users GuideDocument580 pagesIqip Users GuideFirstp LastlNo ratings yet
- AlliedWare PlusTM HOWTODocument42 pagesAlliedWare PlusTM HOWTOliveNo ratings yet
- E8000E Series Firewall Hardware PDFDocument39 pagesE8000E Series Firewall Hardware PDFviktor220378100% (1)
- How To Show DWG Gateway Port StausDocument1 pageHow To Show DWG Gateway Port StausOmar Marley DioufNo ratings yet
- Install Samba Server on UbuntuDocument28 pagesInstall Samba Server on UbuntuAlan SmillNo ratings yet
- Nco Sample Paper Class-12Document2 pagesNco Sample Paper Class-12kumarnpccNo ratings yet
- Creating Mobile Apps With Xamarin - FormsDocument117 pagesCreating Mobile Apps With Xamarin - FormsShoriful IslamNo ratings yet
- 8255 Programmable Peripheral InterfaceDocument27 pages8255 Programmable Peripheral InterfaceumramanNo ratings yet
- Leica GeoMos Imaging FLYDocument2 pagesLeica GeoMos Imaging FLYGaston Del ValleNo ratings yet
- So PrintDocument55 pagesSo PrintAniezeEchaNo ratings yet
- FYP Proposal Submission Form: Human Activity Monitoring (Wall and Fence)Document2 pagesFYP Proposal Submission Form: Human Activity Monitoring (Wall and Fence)RizwanAliNo ratings yet
- VIT JavaScript array questionsDocument38 pagesVIT JavaScript array questionsAbhimanyu SinhalNo ratings yet
- Strings and Pattern SearchingDocument80 pagesStrings and Pattern SearchingAsafAhmadNo ratings yet
- Day4 - PEGA TrainingDocument10 pagesDay4 - PEGA TrainingAnonymous Xdy09XGH3QNo ratings yet
- SAP JVM - Analysis of Permanent Generation Memory Usage Using JvmmonDocument9 pagesSAP JVM - Analysis of Permanent Generation Memory Usage Using JvmmonamardsyNo ratings yet
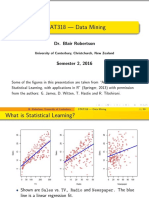
- STAT318 - Data Mining: Dr. Blair RobertsonDocument39 pagesSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNo ratings yet
- Diglit A s2 s1 A3 Windows 10 Study GuideDocument4 pagesDiglit A s2 s1 A3 Windows 10 Study Guideapi-377090598No ratings yet
- Oracle Solaris 11 Network Administration - AgDocument198 pagesOracle Solaris 11 Network Administration - AgRafaNo ratings yet
- The Significance of Computer Forensic Analysis To Law Enforcement ProfessionalsDocument4 pagesThe Significance of Computer Forensic Analysis To Law Enforcement ProfessionalsmuyenzoNo ratings yet
- Sasken Placement Paper Details 2011Document9 pagesSasken Placement Paper Details 2011venniiiiNo ratings yet
- VCP6 DCV Study Guide ESX VirtualizationDocument211 pagesVCP6 DCV Study Guide ESX VirtualizationAlex Applegate100% (5)
- PCClone EX STD PDFDocument27 pagesPCClone EX STD PDFLuis BañuelosNo ratings yet
- Appium Testing Course OutlineDocument3 pagesAppium Testing Course OutlineHarish Kumar MNo ratings yet
- RaspberryPi: Analogue Input With Capacitor (Node - JS)Document4 pagesRaspberryPi: Analogue Input With Capacitor (Node - JS)digital media technologiesNo ratings yet
- CPE 626 Advanced VLSI Design Lecture 3: VHDL Recapitulation: Aleksandar MilenkovicDocument120 pagesCPE 626 Advanced VLSI Design Lecture 3: VHDL Recapitulation: Aleksandar Milenkovicbasavaraj hagaratagiNo ratings yet
- 8086 ArchitectureDocument128 pages8086 ArchitectureLanz de la CruzNo ratings yet
- Connectivity CPI C4CDocument8 pagesConnectivity CPI C4Cfozia_shanu100% (1)
- SC Ricoh Aficio 2022-2027Document16 pagesSC Ricoh Aficio 2022-2027Nguyen Tien DatNo ratings yet
- IEEE Communications Surveys & Tutorials tutorial on InfiniBand, verbs and MPIDocument33 pagesIEEE Communications Surveys & Tutorials tutorial on InfiniBand, verbs and MPIPooyKoNo ratings yet
- Azure Interview Questions and AnswersDocument26 pagesAzure Interview Questions and AnswersPraveen MadupuNo ratings yet