You might also like
- Leçon1 Programmation Mathematique21 10 20Document45 pagesLeçon1 Programmation Mathematique21 10 20Driss Rifai100% (1)
- L3 Gestion-Optimisation-Livret de TDDocument7 pagesL3 Gestion-Optimisation-Livret de TDjomalikeNo ratings yet
- DM Chapitre4 Clustering (Suite HAC)Document13 pagesDM Chapitre4 Clustering (Suite HAC)ikram100% (1)
- Polycopié de Cours - Apprentissage ArtificielDocument62 pagesPolycopié de Cours - Apprentissage Artificielabdeljalil elhadiriNo ratings yet
- OptimisationDocument13 pagesOptimisationJawad MaalNo ratings yet
- Tutorial GamsDocument23 pagesTutorial GamsDjoumana SalemiNo ratings yet
- Une Application Smartphone Pour L'identification Des Objets en Se Basant Sur Le Deep LearningDocument49 pagesUne Application Smartphone Pour L'identification Des Objets en Se Basant Sur Le Deep LearningAymane MaghoutiNo ratings yet
- Prediction Des Proprietes Des Materiaux Par Apprentissage.Document58 pagesPrediction Des Proprietes Des Materiaux Par Apprentissage.BOULAHLIB ALDJIANo ratings yet
- Optimisation Combinatoire Programmation Linéaire Et AlgorithmesDocument155 pagesOptimisation Combinatoire Programmation Linéaire Et AlgorithmesAmani ATTARNo ratings yet
- Exercice Random Forest Classification BayesienneDocument5 pagesExercice Random Forest Classification Bayesienneoumayma brikiNo ratings yet
- PLNEDocument109 pagesPLNEZINEB BELBACHIRNo ratings yet
- Exercice Programmation Lineaire Et Non LineaireDocument1 pageExercice Programmation Lineaire Et Non LineaireAmbassa100% (1)
- Integration Du Systeme D Aide A La Decision Multicriteres Et Du Systeme D Intelligence Que Dans L Ere ConcurrentielleDocument199 pagesIntegration Du Systeme D Aide A La Decision Multicriteres Et Du Systeme D Intelligence Que Dans L Ere ConcurrentielleayanouhaNo ratings yet
- GHEDIR Lina Master ILC Optimisation Du Decoupage de Materiaux Par AGDocument69 pagesGHEDIR Lina Master ILC Optimisation Du Decoupage de Materiaux Par AGDiosWNo ratings yet
- Memoire Master 2018 Larachiche Et Remadelia PDFDocument104 pagesMemoire Master 2018 Larachiche Et Remadelia PDFMohamed SelmaniNo ratings yet
- Algorithme de Colonie de Fourmis 2 FSTFDocument40 pagesAlgorithme de Colonie de Fourmis 2 FSTFHamza Saffaj100% (3)
- TD - Diagrammes de Cas D'utilisation Et de SéquenceDocument11 pagesTD - Diagrammes de Cas D'utilisation Et de SéquenceMohamed BouazaouiNo ratings yet
- Probleme Du Voyageur de Transport Avec Les Méthodes StochastiquesDocument42 pagesProbleme Du Voyageur de Transport Avec Les Méthodes StochastiquesnarimenNo ratings yet
- Chapitre III.1 Modelisation Des Systemes Statiques Et DynamiquesDocument47 pagesChapitre III.1 Modelisation Des Systemes Statiques Et DynamiquesAnis BounaslaNo ratings yet
- PoissonDocument21 pagesPoissonLasme Essoh100% (1)
- MÉTHODES MATHÉMATIQUES DE LA PHYSIQUE. Xavier Bagnoud UNIVERSITE DE FRIBOURG (2010) PDFDocument115 pagesMÉTHODES MATHÉMATIQUES DE LA PHYSIQUE. Xavier Bagnoud UNIVERSITE DE FRIBOURG (2010) PDFKKNo ratings yet
- Manuel UML PowerAMCDocument42 pagesManuel UML PowerAMCbelk00No ratings yet
- Amine Le Recuit Simulc3a9Document12 pagesAmine Le Recuit Simulc3a9Uriel OuakeNo ratings yet
- TD N°4-1Document13 pagesTD N°4-1Imad HakkacheNo ratings yet
- Examen UML PDFDocument4 pagesExamen UML PDFJANNET ELFELAHNo ratings yet
- POO &creation de Bibliothèque ArduinoDocument14 pagesPOO &creation de Bibliothèque ArduinoAdolphe Pascal KIKI100% (1)
- Le Concept Tiré Des Nuées D'oiseaux: L'optimisation Par Essaims de ParticulesDocument15 pagesLe Concept Tiré Des Nuées D'oiseaux: L'optimisation Par Essaims de Particulesسعيد سعيدNo ratings yet
- Programmation Linéaire - Modélisation - Partie IIDocument15 pagesProgrammation Linéaire - Modélisation - Partie IITaha BelakhdherNo ratings yet
- Programmation LinéaireDocument9 pagesProgrammation LinéaireBlgNo ratings yet
- Introduction À La LogiqueDocument35 pagesIntroduction À La Logiqueamore mio0% (1)
- CoursIA 1Document32 pagesCoursIA 1Khlifi AssilNo ratings yet
- Numérique Partie1 CombiDocument176 pagesNumérique Partie1 Combimcraam1985100% (1)
- Exercice CUBEDocument1 pageExercice CUBEbil100% (1)
- Rapport Sur Les Algorithmes Utilisee Dans Le Probleme Du Voyageur de CommerceDocument10 pagesRapport Sur Les Algorithmes Utilisee Dans Le Probleme Du Voyageur de CommerceChergui OussamaNo ratings yet
- TP PandasDocument12 pagesTP PandasHendou MohamedNo ratings yet
- Programmation LineaireDocument10 pagesProgrammation LineaireLionSage100% (1)
- Cours IA PDFDocument88 pagesCours IA PDFKhaled OuniNo ratings yet
- 4 - Algorithmes D'optimisation Heuristiques Et Meta-HeuristiquesDocument23 pages4 - Algorithmes D'optimisation Heuristiques Et Meta-HeuristiquesAhmed Abatourab100% (1)
- Cours C2SI PDFDocument41 pagesCours C2SI PDFKhalil BentayebNo ratings yet
- Exercice Graphe 2Document16 pagesExercice Graphe 2FreddyGuenengafo100% (1)
- Algorithme D'optimisation Par Colonie de FourmisDocument80 pagesAlgorithme D'optimisation Par Colonie de Fourmisهشام درياسNo ratings yet
- Modelisation Et SimulationDocument46 pagesModelisation Et SimulationsalsabilNo ratings yet
- K Means PDFDocument13 pagesK Means PDFFatima HmaidouchNo ratings yet
- ProjetDocument21 pagesProjetMoussa NianeNo ratings yet
- Cours Mcda AnDocument21 pagesCours Mcda Anlokmandz100% (2)
- Gestion Des Emplois Du TempsDocument35 pagesGestion Des Emplois Du TempsGhita BENCHEIKH100% (1)
- Chapitre2 Le Recuit SimulDocument24 pagesChapitre2 Le Recuit SimulSALAH EDDINE100% (1)
- 1a Automatique Poly PDFDocument119 pages1a Automatique Poly PDFaimalNo ratings yet
- Systémes de Gestion de Bases de DonnéesDocument112 pagesSystémes de Gestion de Bases de DonnéesAbdoul wahab kaneNo ratings yet
- Programmation Linéaire Avec ExcelDocument200 pagesProgrammation Linéaire Avec ExcelMaryem Baddouj100% (3)
- Programmation Lineaire PDFDocument10 pagesProgrammation Lineaire PDFnishanth abirNo ratings yet
- Lecon 3 PapierDocument14 pagesLecon 3 Papiergabi adablaNo ratings yet
- Modeles Mathematiques Et Metaheuristiques Pour LaDocument11 pagesModeles Mathematiques Et Metaheuristiques Pour Lajacques EDOHNo ratings yet
- Cours Optimisation1Document11 pagesCours Optimisation1Abderahman ChakNo ratings yet
- MAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsFrom EverandMAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsNo ratings yet
- Extraction et Gestion des Connaissances: Actes de la conférence EGC'2019From EverandExtraction et Gestion des Connaissances: Actes de la conférence EGC'2019Rating: 5 out of 5 stars5/5 (1)
- Apprendre et enseigner sur le Web: quelle ingénierie pédagogique?From EverandApprendre et enseigner sur le Web: quelle ingénierie pédagogique?No ratings yet
- Etudes 76Document4 pagesEtudes 76w.madmax42No ratings yet
- Lecon 9Document11 pagesLecon 9doubeNo ratings yet
- Polygraphes PDFDocument53 pagesPolygraphes PDFAssouma TiNo ratings yet
- MSE3112 BF 10 S 1Document21 pagesMSE3112 BF 10 S 1w.madmax42No ratings yet
- PL1 PDFDocument25 pagesPL1 PDFAbdelghani FTNo ratings yet
- Cre TBDocument3 pagesCre TBw.madmax42No ratings yet
- Vd2 Excoffier Mathilde 30092015Document134 pagesVd2 Excoffier Mathilde 30092015w.madmax42No ratings yet
- Etude Des Méthodes D'optimisation MulticritèresDocument25 pagesEtude Des Méthodes D'optimisation Multicritèresw.madmax42No ratings yet
- GraphesDocument52 pagesGraphesMohamed Ismail100% (1)
- Numeros Utiles Bouygues Telecom 32129 Lnk47xDocument2 pagesNumeros Utiles Bouygues Telecom 32129 Lnk47xw.madmax42No ratings yet
- Programmation LinéaireDocument41 pagesProgrammation Linéairew.madmax42100% (1)
- Prog LinDocument49 pagesProg LinELBASRAOUIINo ratings yet
- Paris Cop21 PDFDocument4 pagesParis Cop21 PDFw.madmax42No ratings yet
- Sady Kov CP SlidesDocument58 pagesSady Kov CP Slidesw.madmax42No ratings yet
- Programmation Linéaire Et Recherche OpérationelleDocument14 pagesProgrammation Linéaire Et Recherche OpérationelleSamah Sam BouimaNo ratings yet
- LM339 Chapitre3Document4 pagesLM339 Chapitre3Mohamed Ben MoussaNo ratings yet
- Algorithme SimplexeDocument8 pagesAlgorithme SimplexeklarksonNo ratings yet
- Diapo Optimisation CombinatoireDocument121 pagesDiapo Optimisation Combinatoirew.madmax42No ratings yet
- Paris Cop21Document4 pagesParis Cop21w.madmax42No ratings yet
- Jc269-Stratplan3 FRDocument31 pagesJc269-Stratplan3 FRw.madmax42No ratings yet
- Bibliographie Sur La Supply Chain Bibliotheque Michel Serres EclDocument2 pagesBibliographie Sur La Supply Chain Bibliotheque Michel Serres Eclw.madmax42No ratings yet
- Gestion de Production - Modele MRP 2012 PDFDocument70 pagesGestion de Production - Modele MRP 2012 PDFCorey HarrisonNo ratings yet
- Jc269-Stratplan3 FRDocument31 pagesJc269-Stratplan3 FRw.madmax42No ratings yet
- Jc269-Stratplan3 FRDocument31 pagesJc269-Stratplan3 FRw.madmax42No ratings yet
- Elwatan 07062009Document25 pagesElwatan 07062009w.madmax42No ratings yet
- Jc269-Stratplan3 FRDocument31 pagesJc269-Stratplan3 FRw.madmax42No ratings yet
- M F 'E Pour L'obtention Du Diplôme de Master en Informatique Option: Présenté ParDocument74 pagesM F 'E Pour L'obtention Du Diplôme de Master en Informatique Option: Présenté ParNour El HoudaNo ratings yet
- Observation - Suivi - Veille Littoral Tunisien APALDocument56 pagesObservation - Suivi - Veille Littoral Tunisien APALsaint luc diattaNo ratings yet
- Le Système Et Le Système D'informationDocument100 pagesLe Système Et Le Système D'informationMajda Khatib100% (1)
- Chapitre 4: Programmation en Nombres Entiers: Abdelkrim E Professeur Habilité en Mathématique AppliquéeDocument33 pagesChapitre 4: Programmation en Nombres Entiers: Abdelkrim E Professeur Habilité en Mathématique AppliquéeAbdel El MouatasimNo ratings yet
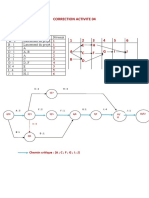
- Correction Activite 04 - GPDocument4 pagesCorrection Activite 04 - GPMoussi BaderNo ratings yet
- IA Séance 1Document30 pagesIA Séance 1Abdallahi SidiNo ratings yet
- Devoir Libre 2023Document2 pagesDevoir Libre 2023haytam lakNo ratings yet
- PFE - Corrigé Jusqu'a La Page 21 - 121427Document64 pagesPFE - Corrigé Jusqu'a La Page 21 - 121427Youness HriouichNo ratings yet
- Séance 4 Aide À La Décision Multicritère AHP-FAHPDocument50 pagesSéance 4 Aide À La Décision Multicritère AHP-FAHPBoubakri Dhia100% (3)
- Les SIG Pour Une Gestion EnvironnementalDocument20 pagesLes SIG Pour Une Gestion EnvironnementalRodolphe TsiafaraNo ratings yet
- Outil D'aide À La DécisionDocument29 pagesOutil D'aide À La Décisionnabil osmanNo ratings yet
- Simulation Des ProcédésDocument55 pagesSimulation Des ProcédéspirloNo ratings yet
- Exercice Optimisation Combinatoire PDFDocument2 pagesExercice Optimisation Combinatoire PDFKeith0% (1)
- Optimisation tp1Document6 pagesOptimisation tp1Salah Mohammed100% (1)
- Recherche OpérationnelleDocument17 pagesRecherche OpérationnelleFouad Elhajji100% (1)
- Travaux Dirigés - PertDocument2 pagesTravaux Dirigés - PertYves AhlonsouNo ratings yet
- Correction Activite 04 - GPDocument4 pagesCorrection Activite 04 - GPfidaNo ratings yet
- Motivation Dauphine IDDocument1 pageMotivation Dauphine IDBoutheyna NecibNo ratings yet
- Plus de 200 Tests Pour Évaluer Les Compétences ITDocument20 pagesPlus de 200 Tests Pour Évaluer Les Compétences ITserge Kashosi chen kashosiNo ratings yet
- Chapitre 1Document43 pagesChapitre 1ABBES Nour-ElHoudaNo ratings yet
- Papier IHM 2022 VFDocument6 pagesPapier IHM 2022 VFDavidNo ratings yet
- Mémoire L'introduction Des NTIC Dans Le Systeme D'information Et Leur Impact Sur La Performance de L'entrepriseDocument144 pagesMémoire L'introduction Des NTIC Dans Le Systeme D'information Et Leur Impact Sur La Performance de L'entrepriseBrahim HallicheNo ratings yet
- Planification SouterrainDocument63 pagesPlanification SouterrainAYOUB CHHAIBINo ratings yet
- Séries Révision - La Gestion de L Approvisionnement - Bac Economie - SfaxDocument17 pagesSéries Révision - La Gestion de L Approvisionnement - Bac Economie - SfaxYahiaLouati100% (1)
- 3 - Optmisation-Mult-Ao-FDocument12 pages3 - Optmisation-Mult-Ao-FAhmed AbatourabNo ratings yet
- Identification Et Hiérarchisation Des ActionsDocument5 pagesIdentification Et Hiérarchisation Des ActionsAbdramane WahidiNo ratings yet
- CoursDocument35 pagesCoursMoncef ComputerNo ratings yet
- Recherche Opérationnelle - TransparentsDocument158 pagesRecherche Opérationnelle - TransparentsIkram Mouhib100% (2)
- Cagri 210095Document10 pagesCagri 210095Sidy Mohamed CoulibalyNo ratings yet
- Exercice Corrigé de Réseau PERTDocument2 pagesExercice Corrigé de Réseau PERTPapy Laurent Fondjo100% (2)