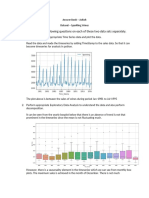
You might also like
- System Administration JakartaDocument347 pagesSystem Administration JakartaLorena Castillero80% (10)
- PRACTICAL RESEARCH 2 - Q1 - W1 - Mod1Document13 pagesPRACTICAL RESEARCH 2 - Q1 - W1 - Mod1Ma Fe Evangelista Galia77% (48)
- Telco Customer ChurnDocument11 pagesTelco Customer ChurnHamza Qazi100% (2)
- Slide 1: No-Churn TelecomDocument11 pagesSlide 1: No-Churn Telecomleongladxton100% (1)
- Customer Churn Prediction Using Big Data AnalyticsDocument41 pagesCustomer Churn Prediction Using Big Data AnalyticsBesty H50% (2)
- Telecom Churn SolutionDocument28 pagesTelecom Churn SolutionShyam Kishore Tripathi100% (5)
- Final Churn PredictionDocument16 pagesFinal Churn PredictionDanny FarooqNo ratings yet
- Capstone Project Final SubmissionDocument13 pagesCapstone Project Final SubmissionSavitaDarekarNo ratings yet
- Assignment 2 PDFDocument25 pagesAssignment 2 PDFBoni HalderNo ratings yet
- Pima Indian Diabetes QuestionsDocument6 pagesPima Indian Diabetes QuestionsAMAN PRAKASHNo ratings yet
- Ordered Groups and Infinite Permutation Groups PDFDocument252 pagesOrdered Groups and Infinite Permutation Groups PDFmc180401877No ratings yet
- CHURN AnalysisDocument6 pagesCHURN AnalysisRaju Das100% (1)
- Churn Prediction in Mobile Telecom Syste PDFDocument5 pagesChurn Prediction in Mobile Telecom Syste PDFMahmoud Al-EwiwiNo ratings yet
- Churn PredictionDocument41 pagesChurn PredictionPritamJaiswal100% (3)
- Customer Churn Analysis and PredictionDocument4 pagesCustomer Churn Analysis and PredictionATSNo ratings yet
- Predicting The Churn in Telecom IndustryDocument9 pagesPredicting The Churn in Telecom Industrystruggler17No ratings yet
- Pre-Paid Customer Churn Prediction Using SPSSDocument18 pagesPre-Paid Customer Churn Prediction Using SPSSabhi1098No ratings yet
- Churn Modelling: TM 298 - Big Data Analytics Group 1Document31 pagesChurn Modelling: TM 298 - Big Data Analytics Group 1Phillip SalinasNo ratings yet
- Telecom Customer ChurnDocument39 pagesTelecom Customer Churnsalmagm0% (1)
- Attrition Reduction IN Telecom IndustryDocument11 pagesAttrition Reduction IN Telecom IndustryPhaninder ReddyNo ratings yet
- Churn DataDocument56 pagesChurn Datatuhion100% (1)
- Customer ChurnDocument50 pagesCustomer ChurnFahad Feroz100% (2)
- Telecom Customer Churn Prediction Assessment-Pratik ZankeDocument19 pagesTelecom Customer Churn Prediction Assessment-Pratik Zankepratik zankeNo ratings yet
- Customer Churn Case StudyDocument19 pagesCustomer Churn Case Studysantoshsadan100% (2)
- Lead Score Case Study PresentationDocument16 pagesLead Score Case Study Presentationashwin choudharyNo ratings yet
- Data Mining Project Shivani PandeyDocument40 pagesData Mining Project Shivani PandeyShivich10100% (1)
- Customer Churn Prediction ReviewDocument7 pagesCustomer Churn Prediction ReviewSanyam Lakhanpal100% (1)
- Customer Churn Prediction Using Machine Learning: D. Deepika, Nihal ChandraDocument14 pagesCustomer Churn Prediction Using Machine Learning: D. Deepika, Nihal ChandraKarthik 1100% (1)
- Churn AnalysisDocument12 pagesChurn AnalysisIsha Handayani100% (3)
- Customer Churn Prediction Project: Group CDocument12 pagesCustomer Churn Prediction Project: Group CRohit NNo ratings yet
- Predicting The Churn in Telecom IndustryDocument23 pagesPredicting The Churn in Telecom Industryashish841No ratings yet
- Time Series ProjectDocument19 pagesTime Series ProjectPriyush Pratim SharmaNo ratings yet
- Telecom Customer Churn RV PDFDocument29 pagesTelecom Customer Churn RV PDFRamachandran VenkataramanNo ratings yet
- Churn Predict AnalysisDocument23 pagesChurn Predict AnalysisSujeet Rajput100% (1)
- Customer Churn AnalysisDocument10 pagesCustomer Churn AnalysisRahul JajuNo ratings yet
- Group Assignment - Data MiningDocument28 pagesGroup Assignment - Data MiningSimran SahaNo ratings yet
- Think Pair Share Team G1 - 7Document8 pagesThink Pair Share Team G1 - 7Akash Kashyap100% (1)
- Answer Book - Sparkling WinesDocument10 pagesAnswer Book - Sparkling WinesAshish AgrawalNo ratings yet
- Customer Churn Prediction in Telecom Industry: Sourav Sarkar (Group 7)Document30 pagesCustomer Churn Prediction in Telecom Industry: Sourav Sarkar (Group 7)prince2venkat100% (1)
- Clustering: ISOM3360 Data Mining For Business AnalyticsDocument28 pagesClustering: ISOM3360 Data Mining For Business AnalyticsClaire LeeNo ratings yet
- Churn AnalysisDocument7 pagesChurn AnalysisgauravNo ratings yet
- Project 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFDocument38 pagesProject 3 - Build A Logistic Regression Model To Predict Custo Mer Churn in Telecom IndustryV1.0 PDFPrakash Jha100% (1)
- Lead Scoring Subjective QuestionsDocument3 pagesLead Scoring Subjective QuestionsAkshay PatilNo ratings yet
- Assignment (AutoRecovered)Document31 pagesAssignment (AutoRecovered)Sri Balaji Ram100% (1)
- Logistic Regression AnalysisDocument16 pagesLogistic Regression AnalysisPIE TUTORSNo ratings yet
- Data Wrangling ReportDocument3 pagesData Wrangling ReportchinudashNo ratings yet
- Applying Data Mining Techniques To Breast Cancer AnalysisDocument30 pagesApplying Data Mining Techniques To Breast Cancer AnalysisLuis ReiNo ratings yet
- Best PDFDocument16 pagesBest PDFSankarNo ratings yet
- Cluster Training PDF (Compatibility Mode)Document21 pagesCluster Training PDF (Compatibility Mode)Sarbani DasguptsNo ratings yet
- Time Series and ForecastingDocument3 pagesTime Series and ForecastingkaviyapriyaNo ratings yet
- Advanced Applied Statistics ProjectDocument16 pagesAdvanced Applied Statistics ProjectIshtiaq IshaqNo ratings yet
- Predictive Modeling: Project Documentation Team 10Document16 pagesPredictive Modeling: Project Documentation Team 10Eka PonkratovaNo ratings yet
- Week3 Logistic Regression Post PDFDocument110 pagesWeek3 Logistic Regression Post PDFYecheng Caroline LiuNo ratings yet
- Customer Analytics in TelecomDocument47 pagesCustomer Analytics in TelecomHemanth19591No ratings yet
- Predictive Modeling Using Transactional Data: Financial ServicesDocument12 pagesPredictive Modeling Using Transactional Data: Financial ServicesAshu Chaudhary100% (1)
- Paper 4-Churn Prediction in Telecommunication PDFDocument3 pagesPaper 4-Churn Prediction in Telecommunication PDFOzioma IhekwoabaNo ratings yet
- DVT Project For PGP-BABI (2019-20) Done by Saleesh Satheeshcahandran (G6)Document3 pagesDVT Project For PGP-BABI (2019-20) Done by Saleesh Satheeshcahandran (G6)Narayana NarlaNo ratings yet
- Customer Churn: by Dinesh Nair Adrien Le Doussal Fiona Tait Fatma Ahmadi Fulya PercinDocument20 pagesCustomer Churn: by Dinesh Nair Adrien Le Doussal Fiona Tait Fatma Ahmadi Fulya PercinFati Ahmadi100% (1)
- Customer Churn Prediction in TelecommunicationDocument13 pagesCustomer Churn Prediction in TelecommunicationnimaNo ratings yet
- 2017 CustomerChurnDocument6 pages2017 CustomerChurnNitya BalakrishnanNo ratings yet
- 61 NikhilDocument12 pages61 NikhilJaswanthh KrishnaNo ratings yet
- Customer Churn Prediction in The Telecommunication Sector Using A Rough Set ApproachDocument13 pagesCustomer Churn Prediction in The Telecommunication Sector Using A Rough Set Approach김기영No ratings yet
- Predicting Customer Churn On OTT PlatformsDocument19 pagesPredicting Customer Churn On OTT PlatformsGabriel DAnnunzioNo ratings yet
- Proportional Directional Valves: Series LVS08 and LVS12 - Preferred Products ProgrammeDocument66 pagesProportional Directional Valves: Series LVS08 and LVS12 - Preferred Products ProgrammealeksandrNo ratings yet
- Efectele Pe Termen Lung Ale Alaptatului OMSDocument74 pagesEfectele Pe Termen Lung Ale Alaptatului OMSbobocraiNo ratings yet
- 2020 Specimen Paper 1 Mark SchemeDocument16 pages2020 Specimen Paper 1 Mark SchemesarabNo ratings yet
- The C Puzzle BookDocument93 pagesThe C Puzzle Bookabhijeetnayak67% (3)
- SQL1Document13 pagesSQL1Devalla Bhaskar GaneshNo ratings yet
- An Isogeometric Analysis Approach For The Study of Structural VibrationsDocument59 pagesAn Isogeometric Analysis Approach For The Study of Structural VibrationsBharti SinghNo ratings yet
- Astm Parte 5Document5 pagesAstm Parte 5Jimmy David Espinoza MejiaNo ratings yet
- R172 NTG4.5 EngineeringMenuDocument5 pagesR172 NTG4.5 EngineeringMenualeksandar_tudzarovNo ratings yet
- TH 2100Document67 pagesTH 2100KI TechnologiesNo ratings yet
- Nylon Bag BisDocument13 pagesNylon Bag Bisbsnl.corp.pbNo ratings yet
- USN 18CS654: B. E. Degree (Autonomous) Sixth Semester End Examination (SEE)Document2 pagesUSN 18CS654: B. E. Degree (Autonomous) Sixth Semester End Examination (SEE)Sarmi HarshaNo ratings yet
- 7 Market EquilibriumDocument4 pages7 Market EquilibriumAdeeba iqbalNo ratings yet
- Introduction To Research MethodsDocument11 pagesIntroduction To Research MethodsKamlakar SadavarteNo ratings yet
- Microsoft OfficeDocument1 pageMicrosoft OfficesavinaumarNo ratings yet
- Sc3 Lecture Short CKT Currents BMR Feb.03, 2021Document11 pagesSc3 Lecture Short CKT Currents BMR Feb.03, 2021Khizer AminNo ratings yet
- Overview of Missile Flight Control Systems: Paul B. JacksonDocument16 pagesOverview of Missile Flight Control Systems: Paul B. JacksonrobjohniiiNo ratings yet
- Lab 4 SpectrophotometryDocument6 pagesLab 4 SpectrophotometryCheng FuNo ratings yet
- 4 Activity Guide and Evaluation Rubric - Unit 2 - Task 4 - Lets Talk and Share - Speaking Task - En.esDocument8 pages4 Activity Guide and Evaluation Rubric - Unit 2 - Task 4 - Lets Talk and Share - Speaking Task - En.esFabiana Cataño gomezNo ratings yet
- How Microprocessors Work PDFDocument2 pagesHow Microprocessors Work PDFdanielconstantin4No ratings yet
- JAVA NotesDocument12 pagesJAVA NotesVarun BawaNo ratings yet
- Pseudocode Is A Technique Used To Describe The Distinct Steps of An Algorithm in ADocument3 pagesPseudocode Is A Technique Used To Describe The Distinct Steps of An Algorithm in AChristian Doson EstilloreNo ratings yet
- Condensation and BoilingDocument14 pagesCondensation and BoilingCrislyn Akilit Bayawa100% (1)
- QE and Complex Numbers DPPDocument9 pagesQE and Complex Numbers DPPsatishmhbdNo ratings yet
- Caliper Xy MemoryDocument6 pagesCaliper Xy MemoryA MuNo ratings yet
- Autodesk REVIT: Training DetailsDocument3 pagesAutodesk REVIT: Training DetailsMohamed ElFarranNo ratings yet
- S ParametersDocument29 pagesS ParameterseloiseNo ratings yet
- Acn CSDocument4 pagesAcn CSLeo100% (1)