You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Cambridge IGCSE Computer Science Programming Book For PythonDocument44 pagesCambridge IGCSE Computer Science Programming Book For Pythonkogumi42% (12)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Defence Expo2022Document111 pagesDefence Expo2022Jyotsna Pandey50% (2)
- HR Shared Services: Best Practices, Business Model and TechnologyDocument11 pagesHR Shared Services: Best Practices, Business Model and TechnologypiermeNo ratings yet
- DDR-SDRAM Controller ASIC Design For High Speed InterfacingDocument5 pagesDDR-SDRAM Controller ASIC Design For High Speed InterfacingInternational Journal of Advanced and Innovative ResearchNo ratings yet
- The Effect of Drying On The Phytochemical Composition of Azadirachta Indica Leaf ExtractDocument5 pagesThe Effect of Drying On The Phytochemical Composition of Azadirachta Indica Leaf ExtractInternational Journal of Advanced and Innovative ResearchNo ratings yet
- A Survey Antenna Design Structure For Massive MIMODocument3 pagesA Survey Antenna Design Structure For Massive MIMOInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Robust Watermarking Using DWT-SVD & Torus Automorphism (DSTA) Based With High PSNR: A ReviewDocument4 pagesRobust Watermarking Using DWT-SVD & Torus Automorphism (DSTA) Based With High PSNR: A ReviewInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Efficient Algorithm For Big Data ApplicationDocument4 pagesEfficient Algorithm For Big Data ApplicationInternational Journal of Advanced and Innovative ResearchNo ratings yet
- SurveyonCloudComputingwithCloudService Model PDFDocument5 pagesSurveyonCloudComputingwithCloudService Model PDFInternational Journal of Advanced and Innovative ResearchNo ratings yet
- SecureandEfficientAccessControlOver P2PCloudStorageSystem PDFDocument5 pagesSecureandEfficientAccessControlOver P2PCloudStorageSystem PDFInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Analysing Sentiment On Matter Reviews Victimisation QD Manual Laborer Technique in On-Line Mobile StoreDocument3 pagesAnalysing Sentiment On Matter Reviews Victimisation QD Manual Laborer Technique in On-Line Mobile StoreInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Nature Flow and Constraints of The Railway Commuters An Analytical Study On Sealdah SectionDocument6 pagesNature Flow and Constraints of The Railway Commuters An Analytical Study On Sealdah SectionInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Robust Watermarking Using DWT-SVD & Torus Automorphism (DSTA) Based With High PSNRDocument5 pagesRobust Watermarking Using DWT-SVD & Torus Automorphism (DSTA) Based With High PSNRInternational Journal of Advanced and Innovative ResearchNo ratings yet
- A Study To Demonstrate The Traditional Value of Dye Plants Collected From Hamirpur District of Himachal Pradesh, IndiaDocument9 pagesA Study To Demonstrate The Traditional Value of Dye Plants Collected From Hamirpur District of Himachal Pradesh, IndiaInternational Journal of Advanced and Innovative ResearchNo ratings yet
- Facility Layout, PPTDocument22 pagesFacility Layout, PPTsakhawatNo ratings yet
- The History of Java Technology: James Gosling Patrick NaughtonDocument2 pagesThe History of Java Technology: James Gosling Patrick NaughtonMiguel Angel Rivera NiñoNo ratings yet
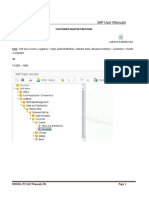
- Customer Master UsermanualDocument13 pagesCustomer Master UsermanualVeeru ThungaNo ratings yet
- Technical Training of 5G Networking DesignDocument32 pagesTechnical Training of 5G Networking DesignThanh Hoang100% (5)
- Instruction Manual Fieldvue Dvc6200 Hw2 Digital Valve Controller en 123052Document108 pagesInstruction Manual Fieldvue Dvc6200 Hw2 Digital Valve Controller en 123052Cautao Cuahang50No ratings yet
- Trina Solar 375W Allmax PDFDocument2 pagesTrina Solar 375W Allmax PDFDiego PulidoNo ratings yet
- Hrms API ScriptDocument13 pagesHrms API ScriptLava KunneNo ratings yet
- CT SizingDocument24 pagesCT SizingGanesh SantoshNo ratings yet
- Bangladesh Railway e Ticket PDFDocument1 pageBangladesh Railway e Ticket PDFShanto Mohammad Salah UddinNo ratings yet
- MID 039 - CID 1846 - FMI 09: TH220B, TH330B, TH340B, TH350B, TH355B, TH360B, TH460B, TH560B and TH580B TelehandlersDocument6 pagesMID 039 - CID 1846 - FMI 09: TH220B, TH330B, TH340B, TH350B, TH355B, TH360B, TH460B, TH560B and TH580B TelehandlersHarold Alberto Bautista AgudeloNo ratings yet
- Md. Mahabubur Rahman: ST STDocument2 pagesMd. Mahabubur Rahman: ST STred zeenNo ratings yet
- Tosvert vfnc3 PDFDocument254 pagesTosvert vfnc3 PDFKukuh Tak TergoyahkanNo ratings yet
- Catalog 64 5000 Series Subatmospheric Pressure Regulator Tescom en 5351134Document4 pagesCatalog 64 5000 Series Subatmospheric Pressure Regulator Tescom en 5351134Titus PrizfelixNo ratings yet
- Procedure For Painting and CoatingDocument13 pagesProcedure For Painting and CoatingAdil IjazNo ratings yet
- 15+ LinkedIn Cold Message Examples That Get - 49+% Reply Rate - ExpandiDocument44 pages15+ LinkedIn Cold Message Examples That Get - 49+% Reply Rate - ExpandiA GentlemenNo ratings yet
- Atys T M - Automatic Transfer Switching Equipment - Installation and Operating Manual - 2021 06 - 542931D - enDocument30 pagesAtys T M - Automatic Transfer Switching Equipment - Installation and Operating Manual - 2021 06 - 542931D - enTRAG ProjectsNo ratings yet
- CV of MD Moshiur RahamanDocument3 pagesCV of MD Moshiur RahamanMoshiur RahamanNo ratings yet
- Contractor List 3Document6 pagesContractor List 3ALI KHALID0% (1)
- 9.1.13.5 Dry Type Transformer User ManualDocument6 pages9.1.13.5 Dry Type Transformer User ManualDindie GarvidaNo ratings yet
- CHAPTER 7 Prototyping PDFDocument7 pagesCHAPTER 7 Prototyping PDFAngeline Lagmay Visaya100% (1)
- Symantec Netbackup ™ For Vmware Administrator'S Guide: Unix, Windows, and LinuxDocument118 pagesSymantec Netbackup ™ For Vmware Administrator'S Guide: Unix, Windows, and Linuxlyax1365No ratings yet
- Chapter 3 (Methodology) PDFDocument15 pagesChapter 3 (Methodology) PDFFarid SyazwanNo ratings yet
- Correlation Between The Courses and The Pos & PsosDocument5 pagesCorrelation Between The Courses and The Pos & PsosJignesh VaghelaNo ratings yet
- Epigrammatum Anthologia Palatina 1 PDFDocument615 pagesEpigrammatum Anthologia Palatina 1 PDFdrfitti1978No ratings yet
- Bescherelle École - Mon Maxi Cahier D'anglais CP, CE1, CE2, CM1, CM2 (Bescherelle Langues) (French Edition)Document1 pageBescherelle École - Mon Maxi Cahier D'anglais CP, CE1, CE2, CM1, CM2 (Bescherelle Langues) (French Edition)Anna Maciejewska0% (2)
- App Mdtk-Wk-Elc-Vdr-Ont-Dwg-001 - 001 - Ga Drawing For Panel Distribution BoardDocument83 pagesApp Mdtk-Wk-Elc-Vdr-Ont-Dwg-001 - 001 - Ga Drawing For Panel Distribution BoardDilara Azqila YasminNo ratings yet
- Nokia Metrosite Installation and Commissioning Course: Metcom - Cx4.0Document9 pagesNokia Metrosite Installation and Commissioning Course: Metcom - Cx4.0LuisNo ratings yet