You might also like
- NSN Vol 2 Addition Subtraction PDFDocument87 pagesNSN Vol 2 Addition Subtraction PDFNur Nadzirah100% (1)
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- BUSC2112 Basic Calculus WEEK 5-7-7101216Document104 pagesBUSC2112 Basic Calculus WEEK 5-7-7101216Mark John Paul Cabling100% (2)
- 9618 Course BookDocument536 pages9618 Course BookQuicksilverNo ratings yet
- Subtraction Up To 10,000: Practice 1 Subtraction Without RegroupingDocument14 pagesSubtraction Up To 10,000: Practice 1 Subtraction Without RegroupingkidushunNo ratings yet
- Transformation of Axes (Geometry) Mathematics Question BankFrom EverandTransformation of Axes (Geometry) Mathematics Question BankRating: 3 out of 5 stars3/5 (1)
- Differential Equation Midterm ExamDocument43 pagesDifferential Equation Midterm Exammicaela vergara67% (3)
- Green FunctionDocument57 pagesGreen FunctionSagar Rawal100% (1)
- Graph Theory and Interconnection NetworksDocument722 pagesGraph Theory and Interconnection NetworksThilak100% (1)
- Service Manual: GE Signa 1.5T MARK 9000 Phased Array Shoulder CoilDocument29 pagesService Manual: GE Signa 1.5T MARK 9000 Phased Array Shoulder CoilRaimundo RochaNo ratings yet
- Math 2nd Quarter With Tos & Key AnsDocument10 pagesMath 2nd Quarter With Tos & Key AnsRosalie R. ReymundoNo ratings yet
- Functions & Limits ConceptsDocument23 pagesFunctions & Limits ConceptsJeriza AquinoNo ratings yet
- Gradient Vector and Directional DerivativesDocument6 pagesGradient Vector and Directional DerivativesCollege Application CenterNo ratings yet
- Calc PYQDocument6 pagesCalc PYQsatish kumarNo ratings yet
- Chapter 12Document6 pagesChapter 12Asad SaeedNo ratings yet
- MAT 772 Lecture 6 Notes on Hermite Interpolation and Finite Difference ApproximationsDocument7 pagesMAT 772 Lecture 6 Notes on Hermite Interpolation and Finite Difference ApproximationsSaurabhNo ratings yet
- MAT232H5F Final Exam Problem Set SolutionsDocument7 pagesMAT232H5F Final Exam Problem Set SolutionsRevownSada0% (1)
- Series de TaylorDocument26 pagesSeries de TaylorRicardo OrtegaNo ratings yet
- Module 3 Other Applications of DifferentiationDocument36 pagesModule 3 Other Applications of DifferentiationSean Maverick NobillosNo ratings yet
- L note-IVDocument6 pagesL note-IVUpdirahman MohamoudNo ratings yet
- Fourier Series ExplainedDocument18 pagesFourier Series ExplainedMarwan ElsayedNo ratings yet
- Fourier Series and Transform ExplainedDocument16 pagesFourier Series and Transform ExplainedSalvacion BandoyNo ratings yet
- Pgmath2023 SolutionsDocument3 pagesPgmath2023 Solutionspublicacc71No ratings yet
- Geg 311 Vector FunctionsDocument19 pagesGeg 311 Vector Functionsakinyemi.favour.isaacNo ratings yet
- Discrepancy of Linear Recurring Sequences over Galois RingsDocument7 pagesDiscrepancy of Linear Recurring Sequences over Galois RingsChatchawan PanraksaNo ratings yet
- Summary (WS1-2)Document3 pagesSummary (WS1-2)Mohammed KhalilNo ratings yet
- Chap 6 LIMIT AND CONTINUITY (S - Week 8)Document16 pagesChap 6 LIMIT AND CONTINUITY (S - Week 8)ADELLINNE NATASYA BINTI ROSDI / UPMNo ratings yet
- Module 1 - Fourier Series-1Document11 pagesModule 1 - Fourier Series-1Md Esteyak alam KhanNo ratings yet
- Finding the rate of changeDocument22 pagesFinding the rate of changeYashuNo ratings yet
- Lnote - IIIDocument7 pagesLnote - IIIUpdirahman MohamoudNo ratings yet
- Muller's Method & Graeffe's Root Squaring MethodDocument8 pagesMuller's Method & Graeffe's Root Squaring MethodSofia Geet100% (1)
- MTH313 Numerical Analysis PDFDocument82 pagesMTH313 Numerical Analysis PDFbashirsaidgumelNo ratings yet
- Lesson 13Document7 pagesLesson 13Jayron John Puguon AquinoNo ratings yet
- Problem 05 SolDocument3 pagesProblem 05 SolDaniyal HassanNo ratings yet
- CH 1 Functions 2Document15 pagesCH 1 Functions 2Mohammed GhallabNo ratings yet
- ECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounDocument23 pagesECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounKen ZhengNo ratings yet
- LECTURE 3: INTERPOLATION TECHNIQUESDocument39 pagesLECTURE 3: INTERPOLATION TECHNIQUESChelsie Patricia Demonteverde MirandaNo ratings yet
- Z Observed At 0, Δt, 2Δt, ... , Nδt (=T) Denoted As Z (0), Z (Δt), Z (2Δt), ... , Z (T)Document10 pagesZ Observed At 0, Δt, 2Δt, ... , Nδt (=T) Denoted As Z (0), Z (Δt), Z (2Δt), ... , Z (T)Wang包了儿No ratings yet
- LE in Combinatorics (Alimento) (Final)Document23 pagesLE in Combinatorics (Alimento) (Final)KayeNo ratings yet
- Richardson Extrapolation NotesDocument7 pagesRichardson Extrapolation NotesHassanZameerNo ratings yet
- Unit 5 (Fourier Series)Document24 pagesUnit 5 (Fourier Series)krushil tejaniNo ratings yet
- Week 8 SlidesDocument82 pagesWeek 8 Slides5s5tbgtfyqNo ratings yet
- Phys 4410 HW 10 Done at CuDocument14 pagesPhys 4410 HW 10 Done at CuChristian Alic KelleyNo ratings yet
- 1 Existence and Uniqueness of Solutions To Differential EquationsDocument22 pages1 Existence and Uniqueness of Solutions To Differential EquationsBella ZionNo ratings yet
- The General Linear EquationDocument13 pagesThe General Linear EquationJm AlipioNo ratings yet
- MAT051 Module 3 Other Applications of Differentiation With Corrections March 17 2021Document45 pagesMAT051 Module 3 Other Applications of Differentiation With Corrections March 17 2021JGM BLACK blinksNo ratings yet
- Definite-Integral-and-The-Fundamental-Theorem-of-CalculusDocument4 pagesDefinite-Integral-and-The-Fundamental-Theorem-of-CalculusshiiextraNo ratings yet
- PRELIMINARY DISCUSSIONS ON FUNCTIONS, LIMITS, AND CONTINUITYDocument3 pagesPRELIMINARY DISCUSSIONS ON FUNCTIONS, LIMITS, AND CONTINUITYSteve RogersNo ratings yet
- Lecture13 of Fluid Dynamics Part 3Document3 pagesLecture13 of Fluid Dynamics Part 3Khan SabNo ratings yet
- Chapter 1Document18 pagesChapter 1krymatf741No ratings yet
- Lesson 44 Line Integral: 44.2.1 ExampleDocument6 pagesLesson 44 Line Integral: 44.2.1 Examplearpit sharmaNo ratings yet
- Basic CalculusDocument29 pagesBasic CalculusOrVen'sNo ratings yet
- Newton-Raphson (NR) MethodDocument14 pagesNewton-Raphson (NR) MethodHONAR DUHOKINo ratings yet
- Tangents and Curvature of Parametric CurvesDocument7 pagesTangents and Curvature of Parametric CurvesAleksandar MicicNo ratings yet
- Tutorial Sheet 6Document2 pagesTutorial Sheet 6Avinash Kumar Jha 4-Year B.Tech. Mechanical EngineeringNo ratings yet
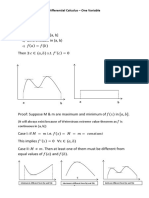
- Rolle's Theorem:: Differential Calculus - One VariableDocument7 pagesRolle's Theorem:: Differential Calculus - One VariableAnshul ModiNo ratings yet
- Robert J. T. BellDocument79 pagesRobert J. T. BellAngshika DeyNo ratings yet
- Answer 40483Document3 pagesAnswer 40483Himanshu ShekharNo ratings yet
- Lec. 3 InterpolationDocument26 pagesLec. 3 InterpolationMahdi HusseinNo ratings yet
- The General Linear EquationDocument13 pagesThe General Linear EquationJm AlipioNo ratings yet
- L Note - V (Updated)Document5 pagesL Note - V (Updated)Updirahman MohamoudNo ratings yet
- Chapter 2 - Solution To Worked ExamplesDocument6 pagesChapter 2 - Solution To Worked ExamplesJack LinesNo ratings yet
- Chapter1 Solution of Equation of One VariableDocument13 pagesChapter1 Solution of Equation of One Variablenelkon7No ratings yet
- Chapter 3Document9 pagesChapter 3Hamza HussineNo ratings yet
- CHAPTER 1-1Document13 pagesCHAPTER 1-1k.benaliaNo ratings yet
- Chapter1 PDFDocument30 pagesChapter1 PDFThilakNo ratings yet
- Introduction To Social Network MethodsDocument149 pagesIntroduction To Social Network MethodsRobert LevyNo ratings yet
- Least Squares Signal ProcessingDocument15 pagesLeast Squares Signal ProcessingseñalesuisNo ratings yet
- Graph MiningDocument51 pagesGraph MiningThilakNo ratings yet
- Recurrences Classification PDFDocument1 pageRecurrences Classification PDFThilakNo ratings yet
- An Introduction To The Theory of Numbes FIFTH EDITIONDocument541 pagesAn Introduction To The Theory of Numbes FIFTH EDITIONrdubé_sarmaNo ratings yet
- Lec 6Document7 pagesLec 6Kathryn HewittNo ratings yet
- Lec 6Document7 pagesLec 6Kathryn HewittNo ratings yet
- Co OrdinateDocument37 pagesCo OrdinateVincent VetterNo ratings yet
- Algebraic Properties of Chromatic Polynomial of A Graph PDFDocument30 pagesAlgebraic Properties of Chromatic Polynomial of A Graph PDFThilakNo ratings yet
- Intro Analysis Ch5Document17 pagesIntro Analysis Ch5Aqeel AnwarNo ratings yet
- Material On EllipsesDocument13 pagesMaterial On EllipsesThilakNo ratings yet
- An Introduction To Differential EquationsDocument62 pagesAn Introduction To Differential EquationsDomenti VictoriaNo ratings yet
- Different I AbilityDocument2 pagesDifferent I AbilityThilakNo ratings yet
- How To Convert Lumens To Lux (LX)Document4 pagesHow To Convert Lumens To Lux (LX)ThilakNo ratings yet
- Solving Triangle - SssDocument5 pagesSolving Triangle - SssThilakNo ratings yet
- Clustering in Mobile Ad Hoc NetworksDocument28 pagesClustering in Mobile Ad Hoc NetworksThilakNo ratings yet
- Geometric ProbabilityDocument60 pagesGeometric ProbabilitythariqsatriaNo ratings yet
- Geometric ProbabilityDocument60 pagesGeometric ProbabilitythariqsatriaNo ratings yet
- 11 Ma 1 A Notes WK 5Document10 pages11 Ma 1 A Notes WK 5ThilakNo ratings yet
- An Introduction to Extending NS-2Document54 pagesAn Introduction to Extending NS-2ThilakNo ratings yet
- Routing in Mobile and Wireless Ad Hoc NetworksDocument3 pagesRouting in Mobile and Wireless Ad Hoc NetworksDang KhueNo ratings yet
- Geometric ProbabilityDocument60 pagesGeometric ProbabilitythariqsatriaNo ratings yet
- Survey of Clustering Algorithms For MANET - 2009Document7 pagesSurvey of Clustering Algorithms For MANET - 2009ThilakNo ratings yet
- Full TextDocument25 pagesFull TextThilak100% (1)
- Introduction To Ns-2: Zhibin WU WINLAB, ECE Dept. Rutgers UDocument47 pagesIntroduction To Ns-2: Zhibin WU WINLAB, ECE Dept. Rutgers UxbslinksNo ratings yet
- ME2 Class Test 1 Sample & Solns0Document6 pagesME2 Class Test 1 Sample & Solns0kakaNo ratings yet
- RDA MathDocument2 pagesRDA MathLorena PangilinanNo ratings yet
- Doing Algebra in Grades K-4Document12 pagesDoing Algebra in Grades K-4GreySiNo ratings yet
- Chain Rule ProofDocument2 pagesChain Rule ProofOmar TalaatNo ratings yet
- Geometry 2ndQ - WorksheetsDocument10 pagesGeometry 2ndQ - WorksheetsJuadjie ParbaNo ratings yet
- Calculus of Variations - WikipediaDocument22 pagesCalculus of Variations - Wikipediarpraj3135No ratings yet
- A12 KDLC Programacion Avanzada Uvm Actividad 12Document7 pagesA12 KDLC Programacion Avanzada Uvm Actividad 12Fernando SCNo ratings yet
- MATH 213 Chapter 4 - PDFDocument6 pagesMATH 213 Chapter 4 - PDFJulian CeledioNo ratings yet
- Mathematics Lamp For Grade 2Document23 pagesMathematics Lamp For Grade 2Ginalyn Matildo AfableNo ratings yet
- Multiplication & DivisionDocument8 pagesMultiplication & DivisionkamikamikamsNo ratings yet
- SMA 2232 - Lec 1 - 2023Document6 pagesSMA 2232 - Lec 1 - 2023woche.telto22No ratings yet
- ArthmaticDocument54 pagesArthmaticreddydhanam99No ratings yet
- 1-SMA 2371-PDE-eeeDocument2 pages1-SMA 2371-PDE-eeeClement KipyegonNo ratings yet
- Lesson Plan ElementrayDocument4 pagesLesson Plan Elementrayapi-249598233No ratings yet
- Assignment 1A - Differential EquationsDocument4 pagesAssignment 1A - Differential EquationsAlina KenyNo ratings yet
- Calculus II Test REVIEW Chapter 3 4Document4 pagesCalculus II Test REVIEW Chapter 3 4banikhyiNo ratings yet
- Semi-Detailed Lesson Plan (OperationOfIntegers) - ZozobradoBSEDMath4ADocument6 pagesSemi-Detailed Lesson Plan (OperationOfIntegers) - ZozobradoBSEDMath4AArman ZozobradoNo ratings yet
- Birla Institute of Technology & Science, Pilani Work Integrated Learning ProgrammesDocument7 pagesBirla Institute of Technology & Science, Pilani Work Integrated Learning ProgrammesGopal KrishnanNo ratings yet
- PLC Program Manual: GSK983M (T) CNC SystemDocument76 pagesPLC Program Manual: GSK983M (T) CNC SystemLeonardusNo ratings yet
- The Derivative, Slope and Rate of ChangeDocument13 pagesThe Derivative, Slope and Rate of ChangeMaria Lenzy LasangueNo ratings yet
- Tutorial 6Document2 pagesTutorial 6thweesha tanejaNo ratings yet
- Mathematics Notes For Class 12 Chapter 5. Continuity and DifferentiabilityDocument9 pagesMathematics Notes For Class 12 Chapter 5. Continuity and DifferentiabilitySREEHARI M SNo ratings yet
- Lesson 36 Methods For Solving Simultaneous Ordinary Differential EquationsDocument6 pagesLesson 36 Methods For Solving Simultaneous Ordinary Differential EquationsHussam AgabNo ratings yet