You might also like
- Probabilidad y estadística: un enfoque teórico-prácticoFrom EverandProbabilidad y estadística: un enfoque teórico-prácticoRating: 4 out of 5 stars4/5 (40)
- Sistemas Egr y SCR en Motor Scania DieselDocument25 pagesSistemas Egr y SCR en Motor Scania DieselJob Esp100% (1)
- Taller de EstadisticaDocument11 pagesTaller de EstadisticaJh JjNo ratings yet
- Programacion Lineal EnteraDocument50 pagesProgramacion Lineal EnteraÁlvaro_cayetanoNo ratings yet
- Dia 04 - Matematica SimetriaDocument11 pagesDia 04 - Matematica SimetriaALICIA HUAYTA GARCIANo ratings yet
- Conceptos Básicos de Probabilidad y EstadísticaDocument17 pagesConceptos Básicos de Probabilidad y Estadísticaequipo5tosemestre4a gmailNo ratings yet
- Trabajo - Conmutacion de PaquetesDocument12 pagesTrabajo - Conmutacion de PaquetesnaujbassNo ratings yet
- Fase 2 - Variables Estadísticas - Folkenberg DíazDocument13 pagesFase 2 - Variables Estadísticas - Folkenberg DíazFOLKENBERG DÍAZ PÉREZNo ratings yet
- Conocimientos en EstadísticaDocument9 pagesConocimientos en EstadísticaEduardo HernandezNo ratings yet
- Deli - EstadisticaDocument7 pagesDeli - EstadisticaJ Daniel HernandezNo ratings yet
- Medidas de Tendencia Central - Herrera Gutiérrez María Del RosarioDocument9 pagesMedidas de Tendencia Central - Herrera Gutiérrez María Del RosarioMary HGNo ratings yet
- Abp 2Document12 pagesAbp 2Victor :/No ratings yet
- Estadística - (Tema 3) - Medidas de Posición y de Dispersión - (PPT) (2019-1)Document26 pagesEstadística - (Tema 3) - Medidas de Posición y de Dispersión - (PPT) (2019-1)ToteB.P-hNo ratings yet
- Clase 1Document34 pagesClase 1Ivannia HasbumNo ratings yet
- Trabajo de MatematicasDocument11 pagesTrabajo de MatematicasBrandy NovaNo ratings yet
- Actividad 7Document12 pagesActividad 7jessicaNo ratings yet
- Medidas de Tendencia Central para Datos NoDocument10 pagesMedidas de Tendencia Central para Datos NoErika HFNo ratings yet
- Estadigrafos CentralesDocument8 pagesEstadigrafos CentralesAngy SaenzNo ratings yet
- INVESTIGACIÓNDocument10 pagesINVESTIGACIÓNAnyi GarciaNo ratings yet
- Medidas de Dispersión 1Document15 pagesMedidas de Dispersión 1JoseRubioNo ratings yet
- Media ApuntesDocument5 pagesMedia ApuntesEmmanuel RamirezNo ratings yet
- Estadistica y ProbabilidadDocument7 pagesEstadistica y ProbabilidadCamii DiazNo ratings yet
- Medidas de Tendencia Central y Distribución de FrecuenciasDocument15 pagesMedidas de Tendencia Central y Distribución de FrecuenciasLuis Angel Puma SegoviaNo ratings yet
- Clase en EstadisticaDocument12 pagesClase en EstadisticaRaul FarfanNo ratings yet
- Solucion PreguntasDocument8 pagesSolucion PreguntasAngelita ZamsanNo ratings yet
- Estadistica SumatoriaDocument13 pagesEstadistica Sumatoriaammari parraNo ratings yet
- Desviación MediaDocument3 pagesDesviación MediaAnthony MendozaNo ratings yet
- Probabilidad y Estadística Sesión 1Document43 pagesProbabilidad y Estadística Sesión 1Marín Juan PabloNo ratings yet
- EstadísticaDocument4 pagesEstadísticaPablo PeraltaNo ratings yet
- CONSULTADocument3 pagesCONSULTAJohanna Jaramillo MorenoNo ratings yet
- Promedi 1Document23 pagesPromedi 1Robert GolindanoNo ratings yet
- Estadistica DescriptivaDocument11 pagesEstadistica DescriptivaOscar SaenzNo ratings yet
- Medidas de Tendencia CentralDocument6 pagesMedidas de Tendencia CentralJavier Alejandro Lozano GuerreroNo ratings yet
- Manuel Alejandro - 93Document12 pagesManuel Alejandro - 93Angelica Maria Gonzalez OrtegaNo ratings yet
- Perez Briones GermanDocument12 pagesPerez Briones GermanHildeberto CortinaNo ratings yet
- Medidas EstadisticaDocument7 pagesMedidas EstadisticaYesenia ChinchillaNo ratings yet
- GLOSARIODocument11 pagesGLOSARIOJuan Antonio Vázquez SandovalNo ratings yet
- Que Son Las Medidas de Tendencia CentralDocument11 pagesQue Son Las Medidas de Tendencia CentralMarleny SolizNo ratings yet
- Desviación Estándar: Datos. LaDocument5 pagesDesviación Estándar: Datos. LaVicsoli SantillánNo ratings yet
- 3-E. Descriptiva-Resumen-de-datosDocument18 pages3-E. Descriptiva-Resumen-de-datosRafael BertoniNo ratings yet
- Probabilidad y EstadisticaDocument6 pagesProbabilidad y EstadisticaUltimateBuld399No ratings yet
- GLOSARIODocument11 pagesGLOSARIOJuan Antonio Vázquez SandovalNo ratings yet
- Estadística DescriptivaDocument6 pagesEstadística DescriptivaGlendaZamoraNo ratings yet
- Glosario de Términos Estadísticos - PinedaDocument20 pagesGlosario de Términos Estadísticos - PinedaLUISA FERNANDA PINEDA MENDOZANo ratings yet
- Trabajo de EstadisticaDocument6 pagesTrabajo de EstadisticaPeter Gabriel Ojeda SNo ratings yet
- Teoria Descriptiva y ProbabilidadDocument9 pagesTeoria Descriptiva y ProbabilidadYoaSchembergerNo ratings yet
- Trabajo de Metrologia (Estadistica)Document35 pagesTrabajo de Metrologia (Estadistica)Camilo De Jesus PipeNo ratings yet
- Media ArmonicaDocument3 pagesMedia ArmonicaJessica QuirozNo ratings yet
- Tarea 1Document34 pagesTarea 1Guillermo TorresNo ratings yet
- Presentación Proyecto de Investigación Minimalista Verde y BeigeDocument26 pagesPresentación Proyecto de Investigación Minimalista Verde y BeigeFran CumbalNo ratings yet
- Medidas de Dispersión Laura Dionicio GarcíaDocument23 pagesMedidas de Dispersión Laura Dionicio GarcíaLucrecia MoralesNo ratings yet
- Clase Octubre 19 MC - CAPITULO 3 TAREA - ANGIE ALVARADODocument8 pagesClase Octubre 19 MC - CAPITULO 3 TAREA - ANGIE ALVARADOAngie AlvaradoNo ratings yet
- COMPROBACION DE LECTURA No2Document6 pagesCOMPROBACION DE LECTURA No2Carlos SalazarNo ratings yet
- Medidas de Tendencia Central y Frecuencias y DiagramasDocument9 pagesMedidas de Tendencia Central y Frecuencias y DiagramasMariana RiveroNo ratings yet
- Clase 5Document41 pagesClase 5Samantha GarcíaNo ratings yet
- Medidas de Tendencia Central (Analisis Estadistico)Document8 pagesMedidas de Tendencia Central (Analisis Estadistico)DianaCCesinNo ratings yet
- TAREA # 4 Medidas de Tendencia Central, Localización y DispersiónDocument10 pagesTAREA # 4 Medidas de Tendencia Central, Localización y DispersiónCarlos HernandezNo ratings yet
- Distribuciones MuestralesDocument25 pagesDistribuciones MuestralesFrancisco JavierNo ratings yet
- Estadistica PDFDocument66 pagesEstadistica PDFWalter SainzNo ratings yet
- Resumen Del Capítulo 3Document8 pagesResumen Del Capítulo 3itzelhernandezmay11No ratings yet
- Libro de LopezDocument66 pagesLibro de LopezMilton Benalcazar0% (1)
- Medidas de Tendencia CentralDocument9 pagesMedidas de Tendencia CentralKaterineAsencioNo ratings yet
- Medidas de DispersionDocument5 pagesMedidas de DispersionEdinson Fabian Salcedo SanguinoNo ratings yet
- Ensayoestad 2023 DedadaneDocument6 pagesEnsayoestad 2023 DedadanemarthaNo ratings yet
- KeidyDocument9 pagesKeidySidalia Mercedes TaverasNo ratings yet
- Formulario para Control de Agua HidromedDocument1 pageFormulario para Control de Agua HidromedSidalia Mercedes TaverasNo ratings yet
- Trabajo de Psicologia de La Motivacion AndreaDocument7 pagesTrabajo de Psicologia de La Motivacion AndreaSidalia Mercedes TaverasNo ratings yet
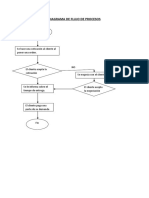
- Diagrama de Flujo de ProcesosDocument3 pagesDiagrama de Flujo de ProcesosSidalia Mercedes TaverasNo ratings yet
- Inocuidad de Los Alimentos - Aseguramiento de La CalidadDocument25 pagesInocuidad de Los Alimentos - Aseguramiento de La Calidadjannie100% (1)
- Curriculum DentistaDocument1 pageCurriculum DentistaLutby Emilio GaitánNo ratings yet
- Inocuidad de Los Alimentos - Aseguramiento de La CalidadDocument25 pagesInocuidad de Los Alimentos - Aseguramiento de La Calidadjannie100% (1)
- Como Generar Ideas Mi Parte Del TrabajoDocument1 pageComo Generar Ideas Mi Parte Del TrabajoSidalia Mercedes TaverasNo ratings yet
- Compuestos-Aromaticos y Alcvoholes ExposicionDocument13 pagesCompuestos-Aromaticos y Alcvoholes ExposicionSidalia Mercedes Taveras0% (1)
- Obtención Del EtanolDocument6 pagesObtención Del EtanolJose Eduardo CaceresNo ratings yet
- Dibujo Industrial ResumenDocument11 pagesDibujo Industrial ResumenSidalia Mercedes TaverasNo ratings yet
- Ley Productos FarmaceuticosDocument89 pagesLey Productos FarmaceuticosSidalia Mercedes TaverasNo ratings yet
- Clase 1 - Qué Es Una Operación UnitariaDocument19 pagesClase 1 - Qué Es Una Operación UnitariaYuliet A.No ratings yet
- Casos de Produccion Copy0101Document10 pagesCasos de Produccion Copy0101Sidalia Mercedes TaverasNo ratings yet
- CAPITULO 2 - Tipos de MantenimientoDocument9 pagesCAPITULO 2 - Tipos de MantenimientoDanielIncisoNo ratings yet
- Mapa Mental Sobre Las Caracteristicas Del EmprendedorDocument1 pageMapa Mental Sobre Las Caracteristicas Del EmprendedorSidalia Mercedes TaverasNo ratings yet
- Segundo Trabajo de Casos de ProduccionDocument12 pagesSegundo Trabajo de Casos de ProduccionSidalia Mercedes TaverasNo ratings yet
- Como Generar Ideas Mi Parte Del TrabajoDocument2 pagesComo Generar Ideas Mi Parte Del TrabajoSidalia Mercedes TaverasNo ratings yet
- Ingenieria Ambiental Trabajo TerminadoDocument9 pagesIngenieria Ambiental Trabajo TerminadoSidalia Mercedes TaverasNo ratings yet
- Analisis y Evaluacion de Puestos SidaliaDocument9 pagesAnalisis y Evaluacion de Puestos SidaliaSidalia Mercedes TaverasNo ratings yet
- Analisis y Evaluacion de Puestos SidaliaDocument1 pageAnalisis y Evaluacion de Puestos SidaliaSidalia Mercedes TaverasNo ratings yet
- Cuestionario Pagina 6Document1 pageCuestionario Pagina 6Sidalia Mercedes TaverasNo ratings yet
- Dibujo Industrial ResumenDocument11 pagesDibujo Industrial ResumenSidalia Mercedes TaverasNo ratings yet
- Trabaj Espa 2Document3 pagesTrabaj Espa 2Sidalia Mercedes TaverasNo ratings yet
- Trabajo de Ingenieria de Costo 2do ParcialDocument11 pagesTrabajo de Ingenieria de Costo 2do ParcialSidalia Mercedes TaverasNo ratings yet
- Programacion Lineal EnteraDocument2 pagesProgramacion Lineal EnteraSidalia Mercedes TaverasNo ratings yet
- Exposicion Psicologia Analisis de Puestos de TrabajoDocument17 pagesExposicion Psicologia Analisis de Puestos de TrabajoSidalia Mercedes TaverasNo ratings yet
- Exposicion Psicologia Analisis de Puestos de TrabajoDocument17 pagesExposicion Psicologia Analisis de Puestos de TrabajoSidalia Mercedes TaverasNo ratings yet
- Trabaj Espa 2Document3 pagesTrabaj Espa 2Sidalia Mercedes TaverasNo ratings yet
- Hoja de Trabajo Anatomía HumanaDocument6 pagesHoja de Trabajo Anatomía HumanaDulce María Pineda ChavezNo ratings yet
- Manual DR 40Document6 pagesManual DR 40lu1agpNo ratings yet
- Carbonato de CalcioDocument27 pagesCarbonato de CalcioEsteban Garcia100% (1)
- Calendario MayaDocument3 pagesCalendario MayaExon SuhulNo ratings yet
- BOURDIEU Espacio Social y La Genesis de Las ClasesDocument29 pagesBOURDIEU Espacio Social y La Genesis de Las ClasesJuan FernandoNo ratings yet
- Guia 9 - 2023Document33 pagesGuia 9 - 2023eduardoelcrack55No ratings yet
- Practica 2 ParcialDocument8 pagesPractica 2 Parcialjulio floresNo ratings yet
- Taller 1 BiologíaDocument7 pagesTaller 1 BiologíaLaura MajeNo ratings yet
- Taller en Grupo de 3Document2 pagesTaller en Grupo de 3Mejia Acosta Raul DavidNo ratings yet
- Diagnostico Lucre-Power PointDocument10 pagesDiagnostico Lucre-Power Pointfrancois1182No ratings yet
- Estudio Hidrologico e Hidraulico Puente en AtalayaDocument178 pagesEstudio Hidrologico e Hidraulico Puente en Atalayaing.neces23No ratings yet
- Estructuras Ii - Materiales EstructuralesDocument18 pagesEstructuras Ii - Materiales EstructuralesVicky TroyaNo ratings yet
- FICHA-TECNICa Industrias BasicasDocument2 pagesFICHA-TECNICa Industrias Basicasandres lopez llanoNo ratings yet
- Proceso Constructivo Una Casa - Taller ViDocument66 pagesProceso Constructivo Una Casa - Taller ViJASMIN NICOLLE LLACSA QUISPENo ratings yet
- Desarrolo y Analis Tecnico de Un Nuevo Fluidi de Perforacion Base Agua de Mar UNIVERSIDAD - NACIONAL - AUTONOMA - DE - MEXICO PDFDocument124 pagesDesarrolo y Analis Tecnico de Un Nuevo Fluidi de Perforacion Base Agua de Mar UNIVERSIDAD - NACIONAL - AUTONOMA - DE - MEXICO PDFWilliam RocaNo ratings yet
- Resumen Completo BachilleratoDocument279 pagesResumen Completo BachilleratoVale PMNo ratings yet
- Evidencia de ConocimientoDocument5 pagesEvidencia de ConocimientoESTEBAN PINEDA VELASQUEZNo ratings yet
- Elaboracion de Nectar de CopoazuDocument7 pagesElaboracion de Nectar de CopoazuJaime100% (1)
- Revit Clase 1 24.02.20Document19 pagesRevit Clase 1 24.02.20Jose Carlos0% (2)
- Trabajo Practico Grupo 2 - Energia NuclearDocument44 pagesTrabajo Practico Grupo 2 - Energia NuclearAlejandro MaidanaNo ratings yet
- Clase 6 Tecins 21Document24 pagesClase 6 Tecins 21Walter GuadronNo ratings yet
- TesisDocument139 pagesTesisElizzabeth HZNo ratings yet
- Clase 1 ProposicionesDocument10 pagesClase 1 ProposicionesLisbeth VasquezNo ratings yet
- Mna1 T05Document37 pagesMna1 T05emdiazpuNo ratings yet
- Estadistica FinalDocument16 pagesEstadistica FinalManuel MozoNo ratings yet
- Practica 2 DigitalDocument1 pagePractica 2 Digitalhartos1988No ratings yet
- Testo 552 2 Vacumetro Digital Con Bluetooth Manual de InstruccionesDocument34 pagesTesto 552 2 Vacumetro Digital Con Bluetooth Manual de InstruccioneslucasNo ratings yet