
You might also like
- Data Mesh: Building Scalable, Resilient, and Decentralized Data Infrastructure for the Enterprise Part 1From EverandData Mesh: Building Scalable, Resilient, and Decentralized Data Infrastructure for the Enterprise Part 1No ratings yet
- Recommendations Using RedisDocument7 pagesRecommendations Using RedisredaniumNo ratings yet
- Big Data RecommendationDocument9 pagesBig Data RecommendationFerdaous HdNo ratings yet
- Collaborative Filtering Techniques For GeneratingDocument5 pagesCollaborative Filtering Techniques For GeneratingycaredNo ratings yet
- DownloadDocument13 pagesDownloadAbusya SeydNo ratings yet
- Case Study Revision Notes 3Document15 pagesCase Study Revision Notes 3Aditya SudinNo ratings yet
- Topic 6 Managerial Support SystemsDocument47 pagesTopic 6 Managerial Support SystemsJeline E LansanganNo ratings yet
- FinalreportDocument92 pagesFinalreportSyed MisbahNo ratings yet
- Neu rx914n629Document6 pagesNeu rx914n629sayoge4736No ratings yet
- Hybrid Recommendation System Using Clustering and Collaborative FilteringDocument6 pagesHybrid Recommendation System Using Clustering and Collaborative FilteringEditor IJRITCCNo ratings yet
- Survey On Users Ranking Pattern Based Trust Model Regularization in Product RecommendationDocument13 pagesSurvey On Users Ranking Pattern Based Trust Model Regularization in Product RecommendationEditor IJTSRDNo ratings yet
- CBP RBW Imacst Published PaperDocument4 pagesCBP RBW Imacst Published PaperR.B.WaghNo ratings yet
- MdocDocument32 pagesMdocjyothi bhavaniNo ratings yet
- Web-Based Personalized Hybrid Book Recommendation SystemDocument5 pagesWeb-Based Personalized Hybrid Book Recommendation SystemconejoNo ratings yet
- Hybrid Web Recommender SystemsDocument33 pagesHybrid Web Recommender SystemsVinicius RodriguesNo ratings yet
- Data Warehouse Project ManagementDocument11 pagesData Warehouse Project ManagementAgha AliNo ratings yet
- Product Review Analysis With Filtering Vulgarity & Ranking System Based On Transaction & OtpDocument4 pagesProduct Review Analysis With Filtering Vulgarity & Ranking System Based On Transaction & OtpijcnesNo ratings yet
- Big Data Ebook 2017Document17 pagesBig Data Ebook 2017Wilson Julián Rodríguez Ch.No ratings yet
- Community Expert Based Recommendation For Solving First Rater ProblemDocument7 pagesCommunity Expert Based Recommendation For Solving First Rater ProblemOmm SinghNo ratings yet
- Web Crawling Based Context Aware Recommender SysteDocument25 pagesWeb Crawling Based Context Aware Recommender SysteSaravanan PalanisamyNo ratings yet
- Personalized Recommendation Services Based On Service-Oriented ArchitectureDocument6 pagesPersonalized Recommendation Services Based On Service-Oriented Architecturesaravana1115No ratings yet
- DecisionDocument6 pagesDecisionSingh GurpreetNo ratings yet
- The Architecture of An Optimizing Decision Support SystemDocument6 pagesThe Architecture of An Optimizing Decision Support SystempraveenaviNo ratings yet
- CC Becse Unit 4 PDFDocument32 pagesCC Becse Unit 4 PDFRushikesh YadavNo ratings yet
- CCPS521-WIN2023-Week12 Recommender Systems V02Document52 pagesCCPS521-WIN2023-Week12 Recommender Systems V02Charles KingstonNo ratings yet
- A Survey of Azure ML Recommender SystemDocument5 pagesA Survey of Azure ML Recommender SystemEditor IJRITCCNo ratings yet
- A Hybrid Recommender System For Recommending Smartphones ToDocument24 pagesA Hybrid Recommender System For Recommending Smartphones ToSabri GOCERNo ratings yet
- Sat - 73.Pdf - Social Media Analysis With Machine LearningDocument8 pagesSat - 73.Pdf - Social Media Analysis With Machine LearningVj KumarNo ratings yet
- Paper 23-An Automated Recommender System For Course SelectionDocument10 pagesPaper 23-An Automated Recommender System For Course SelectionPrasad M ShaivasNo ratings yet
- A Collaborative Location BasedDocument28 pagesA Collaborative Location BasedCinty NyNo ratings yet
- D Ata Science In: PracticeDocument7 pagesD Ata Science In: PracticeShadowfax_u0% (1)
- Lecture 5 - Conceptual, Logical & Physical DB DesignDocument68 pagesLecture 5 - Conceptual, Logical & Physical DB DesignAmmr AmnNo ratings yet
- Usage-Based Web Recommendations: A Reinforcement Learning ApproachDocument8 pagesUsage-Based Web Recommendations: A Reinforcement Learning ApproachFathin MubarakNo ratings yet
- Study of Recommender Systems Techniques: Shreya Gangan, Khyati Pawde, Niharika Purbey, Prof. Sindhu NairDocument4 pagesStudy of Recommender Systems Techniques: Shreya Gangan, Khyati Pawde, Niharika Purbey, Prof. Sindhu NairerpublicationNo ratings yet
- CCPS521 WIN2023 Week12 Recommender SystemsDocument49 pagesCCPS521 WIN2023 Week12 Recommender SystemsCharles KingstonNo ratings yet
- Cloud-Based Context Aware - Recommender SystemDocument7 pagesCloud-Based Context Aware - Recommender System[04] - Abrar ShahNo ratings yet
- Mis - Gds Session - 10: by Somnath MitraDocument14 pagesMis - Gds Session - 10: by Somnath MitraRitesh KumarNo ratings yet
- Paper 6Document8 pagesPaper 6Gaurav SharmaNo ratings yet
- Recommender System Based On Customer Behaviour For Retail StoresDocument12 pagesRecommender System Based On Customer Behaviour For Retail StoresPriscila GuayasamínNo ratings yet
- Decision Support System in ManagementDocument64 pagesDecision Support System in ManagementSumat JainNo ratings yet
- Data Warehousing and The Web: Jim Davis, SAS Institute Inc., Cary, NCDocument4 pagesData Warehousing and The Web: Jim Davis, SAS Institute Inc., Cary, NCPrativa DebNo ratings yet
- ML - 1Document5 pagesML - 1ANNIESOWMYANo ratings yet
- Databases and Information ManagementDocument2 pagesDatabases and Information ManagementNadya AlexandraNo ratings yet
- Recommender Systems: An Overview: Robin Burke, Alexander Felfernig, Mehmet H. GökerDocument6 pagesRecommender Systems: An Overview: Robin Burke, Alexander Felfernig, Mehmet H. GökerabdulsattarNo ratings yet
- UX Analysis White PaperDocument14 pagesUX Analysis White PaperPostolache Adina IulianaNo ratings yet
- Machine Learning Based Efficient Recommendation System For Book Selection Using User Based Collaborative Filtering AlgorithmDocument6 pagesMachine Learning Based Efficient Recommendation System For Book Selection Using User Based Collaborative Filtering Algorithmchrist larsen kumar ekkaNo ratings yet
- User Preferences Based Recommendation System For Services Using Mapreduce ApproachDocument6 pagesUser Preferences Based Recommendation System For Services Using Mapreduce ApproachIJMTST-Online JournalNo ratings yet
- Ijtra 140854Document6 pagesIjtra 140854Akshay Kumar PandeyNo ratings yet
- Types of Decision Support SystemsDocument6 pagesTypes of Decision Support SystemsMitochiNo ratings yet
- Paper2-An Improved Recommender System Solution To MitigatDocument22 pagesPaper2-An Improved Recommender System Solution To Mitigathossam.chakraNo ratings yet
- Sensors 22 04904Document22 pagesSensors 22 04904Miza RaiNo ratings yet
- Selecting The Right Data Warehouse For AnalyticsDocument13 pagesSelecting The Right Data Warehouse For AnalyticsEric LinderhofNo ratings yet
- Unit-2 Modern Data EcosystemDocument3 pagesUnit-2 Modern Data EcosystemParveen KumariNo ratings yet
- Use of Deep Learning in Modern Recommendation System: A Summary of Recent WorksDocument6 pagesUse of Deep Learning in Modern Recommendation System: A Summary of Recent WorksJanardhan ChNo ratings yet
- Recommendation SystemDocument7 pagesRecommendation SystemMuhammed ShabilNo ratings yet
- A Movie Recommendation System Based On A Convolutional Neural NetworkDocument13 pagesA Movie Recommendation System Based On A Convolutional Neural NetworkIJRASETPublicationsNo ratings yet
- Lesson 3 - DSS FrameworkDocument6 pagesLesson 3 - DSS FrameworkSamwelNo ratings yet
- Unveiling Hidden Implicit Similarities For Cross-Domain RecommendationDocument14 pagesUnveiling Hidden Implicit Similarities For Cross-Domain RecommendationDr J S KanchanaNo ratings yet
- Knowledge Management (KM) 2.0Document2 pagesKnowledge Management (KM) 2.0Michael NoblezaNo ratings yet
- A Proposed Hybrid Book Recommender System: Suhas PatilDocument5 pagesA Proposed Hybrid Book Recommender System: Suhas PatilArnav GudduNo ratings yet
- Natural Language Processing and Legal Knowledge ExtractionDocument76 pagesNatural Language Processing and Legal Knowledge ExtractionThis is meNo ratings yet
- Challenges: Unaffiliated Researchers: A Preliminary StudyDocument5 pagesChallenges: Unaffiliated Researchers: A Preliminary StudyThis is meNo ratings yet
- Yesterday, Today and Tommorrow of Big DataDocument9 pagesYesterday, Today and Tommorrow of Big DataThis is meNo ratings yet
- Dzone Guidetoclouddevelopment PDFDocument38 pagesDzone Guidetoclouddevelopment PDFThis is meNo ratings yet
- The Hidden Costs of Microsoft 365Document12 pagesThe Hidden Costs of Microsoft 365This is meNo ratings yet
- Marantz SR5006 AV Receiver PDFDocument2 pagesMarantz SR5006 AV Receiver PDFThis is meNo ratings yet
- Web Design TutorialDocument1 pageWeb Design TutorialThis is meNo ratings yet
- Word Formation in Natural Language Processing SystemsDocument3 pagesWord Formation in Natural Language Processing SystemsThis is meNo ratings yet
- Aspire One Application Manual EnglishDocument77 pagesAspire One Application Manual Englishmconroy42No ratings yet
- EW160 AlarmsDocument12 pagesEW160 AlarmsIgor MaricNo ratings yet
- The Finley ReportDocument46 pagesThe Finley ReportToronto StarNo ratings yet
- The Role of OrganisationDocument9 pagesThe Role of OrganisationMadhury MosharrofNo ratings yet
- Agoura Hills DIVISION - 6. - NOISE - REGULATIONSDocument4 pagesAgoura Hills DIVISION - 6. - NOISE - REGULATIONSKyle KimNo ratings yet
- Switch CondenserDocument14 pagesSwitch CondenserKader GüngörNo ratings yet
- ISP Flash Microcontroller Programmer Ver 3.0: M Asim KhanDocument4 pagesISP Flash Microcontroller Programmer Ver 3.0: M Asim KhanSrđan PavićNo ratings yet
- Insurance Smart Sampoorna RakshaDocument10 pagesInsurance Smart Sampoorna RakshaRISHAB CHETRINo ratings yet
- White Button Mushroom Cultivation ManualDocument8 pagesWhite Button Mushroom Cultivation ManualKhurram Ismail100% (4)
- Nisha Rough DraftDocument50 pagesNisha Rough DraftbharthanNo ratings yet
- Gravity Based Foundations For Offshore Wind FarmsDocument121 pagesGravity Based Foundations For Offshore Wind FarmsBent1988No ratings yet
- Petitioner's Response To Show CauseDocument95 pagesPetitioner's Response To Show CauseNeil GillespieNo ratings yet
- Project Management: Chapter-2Document26 pagesProject Management: Chapter-2Juned BhavayaNo ratings yet
- SDFGHJKL ÑDocument2 pagesSDFGHJKL ÑAlexis CaluñaNo ratings yet
- Service Manual Lumenis Pulse 30HDocument99 pagesService Manual Lumenis Pulse 30HNodir AkhundjanovNo ratings yet
- Kompetensi Sumber Daya Manusia SDM Dalam Meningkatkan Kinerja Tenaga Kependidika PDFDocument13 pagesKompetensi Sumber Daya Manusia SDM Dalam Meningkatkan Kinerja Tenaga Kependidika PDFEka IdrisNo ratings yet
- Interest Rates and Bond Valuation: All Rights ReservedDocument22 pagesInterest Rates and Bond Valuation: All Rights ReservedAnonymous f7wV1lQKRNo ratings yet
- Dreamweaver Lure v. Heyne - ComplaintDocument27 pagesDreamweaver Lure v. Heyne - ComplaintSarah BursteinNo ratings yet
- Test Bank For American Corrections Concepts and Controversies 2nd Edition Barry A Krisberg Susan Marchionna Christopher J HartneyDocument36 pagesTest Bank For American Corrections Concepts and Controversies 2nd Edition Barry A Krisberg Susan Marchionna Christopher J Hartneyvaultedsacristya7a11100% (30)
- LT1256X1 - Revg - FB1300, FB1400 Series - EnglishDocument58 pagesLT1256X1 - Revg - FB1300, FB1400 Series - EnglishRahma NaharinNo ratings yet
- Chapter 1: Investment Landscape: Financial GoalsDocument8 pagesChapter 1: Investment Landscape: Financial GoalsshubhamNo ratings yet
- Pthread TutorialDocument26 pagesPthread Tutorialapi-3754827No ratings yet
- Careem STRATEGIC MANAGEMENT FINAL TERM REPORTDocument40 pagesCareem STRATEGIC MANAGEMENT FINAL TERM REPORTFahim QaiserNo ratings yet
- Sealant Solutions: Nitoseal Thioflex FlamexDocument16 pagesSealant Solutions: Nitoseal Thioflex FlamexBhagwat PatilNo ratings yet
- Power For All - Myth or RealityDocument11 pagesPower For All - Myth or RealityAshutosh BhaktaNo ratings yet
- Class 11 Accountancy NCERT Textbook Chapter 4 Recording of Transactions-IIDocument66 pagesClass 11 Accountancy NCERT Textbook Chapter 4 Recording of Transactions-IIPathan KausarNo ratings yet
- Pro Tools ShortcutsDocument5 pagesPro Tools ShortcutsSteveJones100% (1)
- Conflict WaiverDocument2 pagesConflict WaiverjlurosNo ratings yet
- Powerpoint Presentation R.A 7877 - Anti Sexual Harassment ActDocument14 pagesPowerpoint Presentation R.A 7877 - Anti Sexual Harassment ActApple100% (1)
- UCAT SJT Cheat SheetDocument3 pagesUCAT SJT Cheat Sheetmatthewgao78No ratings yet
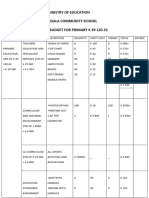
- Ministry of Education Musala SCHDocument5 pagesMinistry of Education Musala SCHlaonimosesNo ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesFrom EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesNo ratings yet
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleFrom EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleRating: 4 out of 5 stars4/5 (16)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- The Future of Competitive Strategy: Unleashing the Power of Data and Digital Ecosystems (Management on the Cutting Edge)From EverandThe Future of Competitive Strategy: Unleashing the Power of Data and Digital Ecosystems (Management on the Cutting Edge)Rating: 5 out of 5 stars5/5 (1)
- Data Mining Techniques: For Marketing, Sales, and Customer Relationship ManagementFrom EverandData Mining Techniques: For Marketing, Sales, and Customer Relationship ManagementRating: 4 out of 5 stars4/5 (9)
- Data Smart: Using Data Science to Transform Information into InsightFrom EverandData Smart: Using Data Science to Transform Information into InsightRating: 4.5 out of 5 stars4.5/5 (23)
- Relational Database Design and ImplementationFrom EverandRelational Database Design and ImplementationRating: 4.5 out of 5 stars4.5/5 (5)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)























































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-2-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1714467780?v=1)