You might also like
- CBSR 4003 Web Server TechnologyDocument15 pagesCBSR 4003 Web Server TechnologyCOCLオスマンNo ratings yet
- CBSR 4003 Web Server TechnologyDocument8 pagesCBSR 4003 Web Server TechnologyCOCLオスマンNo ratings yet
- 0 Leksion Web ServersDocument41 pages0 Leksion Web Serversarlin pashoNo ratings yet
- Web System ArchitectureDocument32 pagesWeb System ArchitectureHansraj RouniyarNo ratings yet
- Web TwchnologiesDocument373 pagesWeb TwchnologiesnavneetccnaNo ratings yet
- 01 NetAppsDocument29 pages01 NetAppsZee ZaboutNo ratings yet
- Web Technologies: Anurag Singh Mohit Srivastava Rishi PandeyDocument43 pagesWeb Technologies: Anurag Singh Mohit Srivastava Rishi PandeyloveloveanuNo ratings yet
- Intrioduction To Web TechnologiesDocument50 pagesIntrioduction To Web Technologiespatrick rollodaNo ratings yet
- Web Technologies: Plattner Melanie Leschinger BernhardDocument49 pagesWeb Technologies: Plattner Melanie Leschinger BernhardSami BubereNo ratings yet
- SUMSEM-2021-22 CSE4001 ETH VL2021220701879 Reference Material II 25-08-2022 6.2 DistributedwebbasedsystemDocument27 pagesSUMSEM-2021-22 CSE4001 ETH VL2021220701879 Reference Material II 25-08-2022 6.2 DistributedwebbasedsystemSamvitNo ratings yet
- Thin ClientsDocument31 pagesThin ClientsMiqueas GonzalesNo ratings yet
- WIT-1 Ruby Special 2marks PDFDocument73 pagesWIT-1 Ruby Special 2marks PDFsyed shahidnazeerNo ratings yet
- Application Layer: Schedule: MW 1:30 PM - 2:45 PM, Tahoe Hall 1026 Instructor: Dr. Sadaf AshtariDocument52 pagesApplication Layer: Schedule: MW 1:30 PM - 2:45 PM, Tahoe Hall 1026 Instructor: Dr. Sadaf AshtariThông LạiNo ratings yet
- Architecture DesignDocument54 pagesArchitecture DesignBehind The SideNo ratings yet
- UntitledggggDocument36 pagesUntitledggggAmbrose OnapaNo ratings yet
- Web TechnologyDocument247 pagesWeb TechnologydineshkumarhclNo ratings yet
- Active Browser Pages, Web Services, BasicsDocument59 pagesActive Browser Pages, Web Services, BasicsAqsaNo ratings yet
- PPT-1 HTMLDocument113 pagesPPT-1 HTMLAnushka SharmaNo ratings yet
- Web Server ProjectDocument16 pagesWeb Server Projectمعتز العجيليNo ratings yet
- 3 HTTP & FTP Serveices: StructureDocument10 pages3 HTTP & FTP Serveices: StructuresumitangiraNo ratings yet
- Assignment 2Document15 pagesAssignment 2ZIX326No ratings yet
- E Commerce ArchitectureDocument11 pagesE Commerce ArchitectureRishabh SethiNo ratings yet
- ECS781P-3-Cloud ApplicationsDocument50 pagesECS781P-3-Cloud ApplicationsYen-Kai ChengNo ratings yet
- Week1 Introduction PDFDocument52 pagesWeek1 Introduction PDFBhuvan AhujaNo ratings yet
- 4020 Week 4Document51 pages4020 Week 4khanpmsg26No ratings yet
- Ch3 - The Internet Database EnvironmentDocument25 pagesCh3 - The Internet Database EnvironmenthasaniftakharNo ratings yet
- Introductiontowebarchitecture 090922221506 Phpapp01Document60 pagesIntroductiontowebarchitecture 090922221506 Phpapp01AqsaNo ratings yet
- Web Services As Method of Access To Parallel Cluster ResourcesDocument11 pagesWeb Services As Method of Access To Parallel Cluster ResourcespaldudemanNo ratings yet
- 07 CT050-3-2 Introduction To Servers and SecurityDocument24 pages07 CT050-3-2 Introduction To Servers and SecurityMOHAMAD FIRDAUS BIN CHE ABDUL RANINo ratings yet
- The Internet - An IntroductionDocument32 pagesThe Internet - An IntroductionPatrick LegiNo ratings yet
- Unit-2:: Application LayerDocument34 pagesUnit-2:: Application LayerKondareddy RamireddyNo ratings yet
- Pertemuan 2Document26 pagesPertemuan 2Arief BudimanNo ratings yet
- (Part-1) : Dr. Nirnay GhoshDocument4 pages(Part-1) : Dr. Nirnay GhoshSOHOM MAJUMDARNo ratings yet
- HTTP OverviewDocument45 pagesHTTP OverviewManzu PokharelNo ratings yet
- DotNet 1Document66 pagesDotNet 1sindhuja eswarNo ratings yet
- Wit Lecture Notes by RaginiDocument239 pagesWit Lecture Notes by Raginitezom techeNo ratings yet
- CH2 HKM UpdatedDocument174 pagesCH2 HKM Updatedmuhammad azimNo ratings yet
- Wit Full NotesDocument236 pagesWit Full Notessoumya100% (1)
- Module VDocument46 pagesModule Vvinutha kNo ratings yet
- Intro To Tech StreamsDocument124 pagesIntro To Tech Streamsapi-3706175100% (1)
- 08 - Introduction To Servers and Security - SlidesDocument24 pages08 - Introduction To Servers and Security - SlidesMOHAMAD FIRDAUS BIN CHE ABDUL RANINo ratings yet
- 01 Internet Web ConceptsDocument33 pages01 Internet Web Conceptskamran khanNo ratings yet
- ch-3 AJDocument26 pagesch-3 AJDhrutik PadashalaNo ratings yet
- Topics That We Will ExploreDocument135 pagesTopics That We Will ExploreAJNo ratings yet
- Web Technologies NotesDocument238 pagesWeb Technologies NotesBommidarling JoeNo ratings yet
- NotesDocument359 pagesNotesadlinefreedaNo ratings yet
- AnnexureDocument7 pagesAnnexureVrushabh HuleNo ratings yet
- Introduction To Micro ServicesDocument46 pagesIntroduction To Micro ServicesNikita PatelNo ratings yet
- Introduction To Micro-ServicesDocument46 pagesIntroduction To Micro-Servicesroshni2012No ratings yet
- Week 2 NewDocument26 pagesWeek 2 NewOla OludeleNo ratings yet
- Web Technologies Notes - TutorialsDuniyaDocument249 pagesWeb Technologies Notes - TutorialsDuniyaISHARE DDU-GKY100% (1)
- Lecture 2 InfrastructureDocument64 pagesLecture 2 InfrastructureSoumitra ChakrabortyNo ratings yet
- Web Technology DBMSsDocument61 pagesWeb Technology DBMSskirank_11No ratings yet
- 02 SystemModels Architecture 2Document7 pages02 SystemModels Architecture 2Kool PrashantNo ratings yet
- Cs Project Class 12 CbseDocument39 pagesCs Project Class 12 CbseKV AdithyanNo ratings yet
- Fundamentals of Web Development: Third Edition by Randy Connolly and Ricardo HoarDocument38 pagesFundamentals of Web Development: Third Edition by Randy Connolly and Ricardo Hoarihatebooks98100% (2)
- Module 5 CNDocument26 pagesModule 5 CNNadeem PashaNo ratings yet
- E-Commerce Enabling TechnologiesDocument11 pagesE-Commerce Enabling Technologiesmarkobare2019No ratings yet
- Project SynopsisDocument15 pagesProject Synopsissumitasthana2100% (3)
- Psychological Contract Rousseau PDFDocument9 pagesPsychological Contract Rousseau PDFSandy KhanNo ratings yet
- Decision Making and The Role of Manageme PDFDocument20 pagesDecision Making and The Role of Manageme PDFRaadmaan RadNo ratings yet
- Heterogeneity in Macroeconomics: Macroeconomic Theory II (ECO-504) - Spring 2018Document5 pagesHeterogeneity in Macroeconomics: Macroeconomic Theory II (ECO-504) - Spring 2018Gabriel RoblesNo ratings yet
- 11-03 TB Value Chains and BPs - WolfDocument3 pages11-03 TB Value Chains and BPs - WolfPrakash PandeyNo ratings yet
- ISBN Safe Work Method Statements 2022 03Document8 pagesISBN Safe Work Method Statements 2022 03Tamo Kim ChowNo ratings yet
- ME Eng 8 Q1 0101 - SG - African History and LiteratureDocument13 pagesME Eng 8 Q1 0101 - SG - African History and Literaturerosary bersanoNo ratings yet
- Hey Friends B TBDocument152 pagesHey Friends B TBTizianoCiro CarrizoNo ratings yet
- On Derridean Différance - UsiefDocument16 pagesOn Derridean Différance - UsiefS JEROME 2070505No ratings yet
- Monkey Says, Monkey Does Security andDocument11 pagesMonkey Says, Monkey Does Security andNudeNo ratings yet
- Huawei R4815N1 DatasheetDocument2 pagesHuawei R4815N1 DatasheetBysNo ratings yet
- Theories of International InvestmentDocument2 pagesTheories of International InvestmentSamish DhakalNo ratings yet
- Corrosion Fatigue Phenomena Learned From Failure AnalysisDocument10 pagesCorrosion Fatigue Phenomena Learned From Failure AnalysisDavid Jose Velandia MunozNo ratings yet
- Iec TR 61010-3-020-1999Document76 pagesIec TR 61010-3-020-1999Vasko MandilNo ratings yet
- The Doshas in A Nutshell - : Vata Pitta KaphaDocument1 pageThe Doshas in A Nutshell - : Vata Pitta KaphaCheryl LynnNo ratings yet
- The Construction of Optimal Portfolio Using Sharpe's Single Index Model - An Empirical Study On Nifty Metal IndexDocument9 pagesThe Construction of Optimal Portfolio Using Sharpe's Single Index Model - An Empirical Study On Nifty Metal IndexRevanKumarBattuNo ratings yet
- User Manual For Speed Control of BLDC Motor Using DspicDocument12 pagesUser Manual For Speed Control of BLDC Motor Using DspicTrung TrựcNo ratings yet
- Technical Specification For 33KV VCB BoardDocument7 pagesTechnical Specification For 33KV VCB BoardDipankar ChatterjeeNo ratings yet
- Online Extra: "Economists Suffer From Physics Envy"Document2 pagesOnline Extra: "Economists Suffer From Physics Envy"Bisto MasiloNo ratings yet
- Azimuth Steueung - EngDocument13 pagesAzimuth Steueung - EnglacothNo ratings yet
- E MudhraDownload HardDocument17 pagesE MudhraDownload HardVivek RajanNo ratings yet
- How To Identify MQ Client Connections and Stop ThemDocument26 pagesHow To Identify MQ Client Connections and Stop ThemPurushotham100% (1)
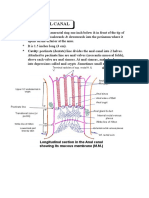
- Anatomy Anal CanalDocument14 pagesAnatomy Anal CanalBela Ronaldoe100% (1)
- Origami Oso HormigueroDocument9 pagesOrigami Oso HormigueroRogelio CerdaNo ratings yet
- Law of EvidenceDocument14 pagesLaw of EvidenceIsha ChavanNo ratings yet
- DQ Vibro SifterDocument13 pagesDQ Vibro SifterDhaval Chapla67% (3)
- Revenue and Expenditure AuditDocument38 pagesRevenue and Expenditure AuditPavitra MohanNo ratings yet
- Prelim Examination MaternalDocument23 pagesPrelim Examination MaternalAaron ConstantinoNo ratings yet
- TIMO Final 2020-2021 P3Document5 pagesTIMO Final 2020-2021 P3An Nguyen100% (2)
- 74HC00D 74HC00D 74HC00D 74HC00D: CMOS Digital Integrated Circuits Silicon MonolithicDocument8 pages74HC00D 74HC00D 74HC00D 74HC00D: CMOS Digital Integrated Circuits Silicon MonolithicAssistec TecNo ratings yet
- Principals' Leadership Styles and Student Academic Performance in Secondary Schools in Ekiti State, NigeriaDocument12 pagesPrincipals' Leadership Styles and Student Academic Performance in Secondary Schools in Ekiti State, NigeriaiqraNo ratings yet