You might also like
- Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really AreFrom EverandEverybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really AreRating: 4 out of 5 stars4/5 (369)
- Sunflower Diaries: Cryptology Applied to Basic Math and Current Technology, Volume 1From EverandSunflower Diaries: Cryptology Applied to Basic Math and Current Technology, Volume 1No ratings yet
- Eight Preposterous Propositions: From the Genetics of Homosexuality to the Benefits of Global WarmingFrom EverandEight Preposterous Propositions: From the Genetics of Homosexuality to the Benefits of Global WarmingRating: 4 out of 5 stars4/5 (9)
- 3.2 Three Kinds of Questions That Researchers AskDocument4 pages3.2 Three Kinds of Questions That Researchers AskMam HaidoryNo ratings yet
- Book Review: Blink by Malcolm Gladwell: The secrets of subconscious decision-makingFrom EverandBook Review: Blink by Malcolm Gladwell: The secrets of subconscious decision-makingNo ratings yet
- How to Humble a Wingnut and Other Lessons from Behavioral EconomicsFrom EverandHow to Humble a Wingnut and Other Lessons from Behavioral EconomicsRating: 4.5 out of 5 stars4.5/5 (4)
- Profit from History: See Patterns; Make Predictions; Better Your LifeFrom EverandProfit from History: See Patterns; Make Predictions; Better Your LifeNo ratings yet
- The Concept of Statistical Significance in Testing HypothesesDocument6 pagesThe Concept of Statistical Significance in Testing HypothesesMohamed SaleemNo ratings yet
- Book Review: Nudge by Richard H. Thaler and Cass R. Sunstein: A manifesto of libertarian paternalismFrom EverandBook Review: Nudge by Richard H. Thaler and Cass R. Sunstein: A manifesto of libertarian paternalismNo ratings yet
- World Leadership: How Societies Become Leaders and What Future Leading Societies Will Look LikeFrom EverandWorld Leadership: How Societies Become Leaders and What Future Leading Societies Will Look LikeNo ratings yet
- The Strange Ways of Chance: A Lay Guide to Uncertainty in Medicine, Sports, Finance, Crime, and MoreFrom EverandThe Strange Ways of Chance: A Lay Guide to Uncertainty in Medicine, Sports, Finance, Crime, and MoreNo ratings yet
- Stat-Spotting: A Field Guide to Identifying Dubious DataFrom EverandStat-Spotting: A Field Guide to Identifying Dubious DataRating: 4 out of 5 stars4/5 (7)
- Practical Statistics Simply ExplainedFrom EverandPractical Statistics Simply ExplainedRating: 3.5 out of 5 stars3.5/5 (3)
- Embracing ComplexityDocument12 pagesEmbracing ComplexityBlessolutionsNo ratings yet
- Can You Outsmart an Economist?: 100+ Puzzles to Train Your BrainFrom EverandCan You Outsmart an Economist?: 100+ Puzzles to Train Your BrainNo ratings yet
- Psychonomics: How Modern Science Aims to Conquer the Mind and How the Mind PrevailsFrom EverandPsychonomics: How Modern Science Aims to Conquer the Mind and How the Mind PrevailsNo ratings yet
- The Quick Fix: Why Fad Psychology Can't Cure Our Social IllsFrom EverandThe Quick Fix: Why Fad Psychology Can't Cure Our Social IllsRating: 4 out of 5 stars4/5 (6)
- How To ThinkDocument13 pagesHow To ThinkmrigankkashNo ratings yet
- Models Are Stupid, and We Need More of ThemDocument19 pagesModels Are Stupid, and We Need More of ThemLux GmtNo ratings yet
- Causality and Statistical Learning (Andrew Gelman)Document12 pagesCausality and Statistical Learning (Andrew Gelman)kekeNo ratings yet
- The Vocabulary of Scientific Literacy: The Fundamental Definitions Every Scientifically-Literate Person Should KnowFrom EverandThe Vocabulary of Scientific Literacy: The Fundamental Definitions Every Scientifically-Literate Person Should KnowNo ratings yet
- How to grab the coffee cup. The statistical reasoning in everyday lifeFrom EverandHow to grab the coffee cup. The statistical reasoning in everyday lifeNo ratings yet
- Thinking StatisticallyDocument29 pagesThinking Statisticallyroy royNo ratings yet
- Simply Complexity: A Clear Guide to Complexity TheoryFrom EverandSimply Complexity: A Clear Guide to Complexity TheoryRating: 3.5 out of 5 stars3.5/5 (18)
- Physics Foibles: A Book for Physics, Math and Computer Science StudentsFrom EverandPhysics Foibles: A Book for Physics, Math and Computer Science StudentsNo ratings yet
- Hawking and Maudlin Debate Philosophy's Role in ScienceDocument15 pagesHawking and Maudlin Debate Philosophy's Role in ScienceDamir ĐirlićNo ratings yet
- When the Echo Dies: Marriage Is Unconstitutional: America at RiskFrom EverandWhen the Echo Dies: Marriage Is Unconstitutional: America at RiskNo ratings yet
- How To Think: Why Arguing A Point Comes NaturallyDocument11 pagesHow To Think: Why Arguing A Point Comes NaturallyAnonymous 0yCy6amiEmNo ratings yet
- Why Model?: Joshua M. EpsteinDocument6 pagesWhy Model?: Joshua M. Epsteinjsebas60No ratings yet
- Sample EssaysDocument6 pagesSample EssaysDD97No ratings yet
- Dance With Chance: Making Luck Work for YouFrom EverandDance With Chance: Making Luck Work for YouRating: 4 out of 5 stars4/5 (5)
- Principles and Methods of Social Research: Second EditionDocument15 pagesPrinciples and Methods of Social Research: Second EditionLarisa AlexandraNo ratings yet
- Suspicious Minds: Why We Believe Conspiracy TheoriesFrom EverandSuspicious Minds: Why We Believe Conspiracy TheoriesRating: 3.5 out of 5 stars3.5/5 (16)
- Tackling Global Problems With Big Data: Viktor Mayer-SchönbergerDocument10 pagesTackling Global Problems With Big Data: Viktor Mayer-SchönbergerRishi TandonNo ratings yet
- Why Model? Insights from Joshua M. EpsteinDocument5 pagesWhy Model? Insights from Joshua M. EpsteinLautaro Simón Ramírez CifuentesNo ratings yet
- Practical Genius: How to be a Featherless BipedFrom EverandPractical Genius: How to be a Featherless BipedRating: 2 out of 5 stars2/5 (1)
- The Theory of Evolution is a Result of Erroneous ExtrapolationFrom EverandThe Theory of Evolution is a Result of Erroneous ExtrapolationNo ratings yet
- 20 Chap 16 PDFDocument6 pages20 Chap 16 PDFMrigendra MishraNo ratings yet
- Aimcat 1811 PDFDocument41 pagesAimcat 1811 PDFShiba ShankarNo ratings yet
- Past, Present and Future: An Irreverent Treatment of HistoryFrom EverandPast, Present and Future: An Irreverent Treatment of HistoryNo ratings yet
- Debunk It! Fake News Edition: How to Stay Sane in a World of MisinformationFrom EverandDebunk It! Fake News Edition: How to Stay Sane in a World of MisinformationRating: 3 out of 5 stars3/5 (12)
- Critical Literacy (Student)Document11 pagesCritical Literacy (Student)api-250867541No ratings yet
- أهم القطع للثانوية العامة - أ. بلال زهير أحمد - توجيهي2022Document6 pagesأهم القطع للثانوية العامة - أ. بلال زهير أحمد - توجيهي2022Abdullah AhmedNo ratings yet
- Lecturing Birds on Flying: Can Mathematical Theories Destroy the Financial Markets?From EverandLecturing Birds on Flying: Can Mathematical Theories Destroy the Financial Markets?Rating: 3 out of 5 stars3/5 (1)
- Conversations with a Snot-Nosed Kid: Are We Living in a Computer Simulation?From EverandConversations with a Snot-Nosed Kid: Are We Living in a Computer Simulation?Rating: 5 out of 5 stars5/5 (1)
- wp2017 25Document123 pageswp2017 25TBP_Think_Tank100% (7)
- Covid 2Document7 pagesCovid 2TBP_Think_Tank100% (2)
- Fintech Innovation in The Home Purchase and Financing Market 0Document15 pagesFintech Innovation in The Home Purchase and Financing Market 0TBP_Think_TankNo ratings yet
- Market Declines: What Is Accomplished by Banning Short-Selling?Document7 pagesMarket Declines: What Is Accomplished by Banning Short-Selling?annawitkowski88No ratings yet
- CPC Hearings Nyu 12-6-18Document147 pagesCPC Hearings Nyu 12-6-18TBP_Think_TankNo ratings yet
- p60 263Document74 pagesp60 263TBP_Think_TankNo ratings yet
- Insight: Can The Euro Rival The Dollar?Document6 pagesInsight: Can The Euro Rival The Dollar?TBP_Think_TankNo ratings yet
- HHRG 116 BA16 Wstate IsolaD 20190314Document4 pagesHHRG 116 BA16 Wstate IsolaD 20190314TBP_Think_Tank0% (1)
- ISGQVAADocument28 pagesISGQVAATBP_Think_Tank100% (1)
- Vanguard - Barry Q&ADocument5 pagesVanguard - Barry Q&ATBP_Think_TankNo ratings yet
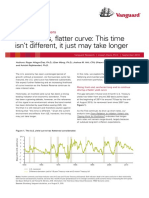
- Rising Rates, Flatter Curve: This Time Isn't Different, It Just May Take LongerDocument5 pagesRising Rates, Flatter Curve: This Time Isn't Different, It Just May Take LongerTBP_Think_TankNo ratings yet
- WEF BookDocument78 pagesWEF BookZerohedge100% (1)
- El2018 19Document5 pagesEl2018 19TBP_Think_Tank100% (1)
- R 180726 GDocument2 pagesR 180726 GTBP_Think_TankNo ratings yet
- Nafta Briefing April 2018 Public Version-FinalDocument17 pagesNafta Briefing April 2018 Public Version-FinalTBP_Think_TankNo ratings yet
- 381-2018 FetzerDocument100 pages381-2018 FetzerTBP_Think_TankNo ratings yet
- F 2807 SuerfDocument11 pagesF 2807 SuerfTBP_Think_TankNo ratings yet
- Solving Future Skills ChallengesDocument32 pagesSolving Future Skills ChallengesTBP_Think_Tank100% (1)
- Bullard Glasgow Chamber 20 July 2018Document33 pagesBullard Glasgow Chamber 20 July 2018TBP_Think_TankNo ratings yet
- Williamson 020418Document67 pagesWilliamson 020418TBP_Think_TankNo ratings yet
- Inequalities in Household Wealth Across OECD Countries: OECD Statistics Working Papers 2018/01Document70 pagesInequalities in Household Wealth Across OECD Countries: OECD Statistics Working Papers 2018/01TBP_Think_TankNo ratings yet
- Financial Stability ReviewDocument188 pagesFinancial Stability ReviewTBP_Think_TankNo ratings yet
- HFS Essay 2 2018Document24 pagesHFS Essay 2 2018TBP_Think_TankNo ratings yet
- pb18 16Document8 pagespb18 16TBP_Think_TankNo ratings yet
- Trade Patterns of China and India: Analytical Articles Economic Bulletin 3/2018Document14 pagesTrade Patterns of China and India: Analytical Articles Economic Bulletin 3/2018TBP_Think_TankNo ratings yet
- DP 11648Document52 pagesDP 11648TBP_Think_TankNo ratings yet
- The Economics of Subsidizing Sports Stadiums SEDocument4 pagesThe Economics of Subsidizing Sports Stadiums SETBP_Think_TankNo ratings yet
- Macro Aspects of Housing: Federal Reserve Bank of Dallas Globalization and Monetary Policy InstituteDocument73 pagesMacro Aspects of Housing: Federal Reserve Bank of Dallas Globalization and Monetary Policy InstituteTBP_Think_TankNo ratings yet
- Has18 062018Document116 pagesHas18 062018TBP_Think_TankNo ratings yet
- Working Paper Series: Exchange Rate Forecasting On A NapkinDocument19 pagesWorking Paper Series: Exchange Rate Forecasting On A NapkinTBP_Think_TankNo ratings yet
- Instant Download Ebook PDF Elementary Survey Sampling 7th Edition PDF ScribdDocument41 pagesInstant Download Ebook PDF Elementary Survey Sampling 7th Edition PDF Scribdjason.reeves204100% (42)
- Exercise 1 SolutionsDocument3 pagesExercise 1 SolutionsCartieNo ratings yet
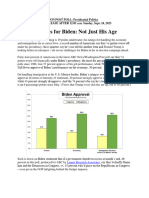
- Presidential Poll 2024Document11 pagesPresidential Poll 2024Juan PeñaNo ratings yet
- Alan R. Ball (Auth.) - Modern Politics and Government (1988, Macmillan Education UK)Document262 pagesAlan R. Ball (Auth.) - Modern Politics and Government (1988, Macmillan Education UK)Heather Carter100% (3)
- 3 ĐỀ THI THPT QUỐC GIA - KEY CÓ GIẢI THÍCH CHI TIẾTDocument40 pages3 ĐỀ THI THPT QUỐC GIA - KEY CÓ GIẢI THÍCH CHI TIẾTTrần Quốc Quyện50% (2)
- Lesson 11. Computer Application That Supports Nursing ResearchDocument6 pagesLesson 11. Computer Application That Supports Nursing ResearchGroup 8 BSN 33No ratings yet
- Early Voting: What WorksDocument44 pagesEarly Voting: What WorksThe Brennan Center for JusticeNo ratings yet
- Media RulesDocument102 pagesMedia RulesTony YeglesNo ratings yet
- Sba - SpreadsheetDocument3 pagesSba - Spreadsheetapi-489394215No ratings yet
- April 2, 2009 IssueDocument12 pagesApril 2, 2009 IssueThe Brown Daily HeraldNo ratings yet
- Views On Divorce Rate in Pakistan 48% Believe It Has Increased, of Whom Majority Believes It Is Due To Lack of Patience: Gilani Poll/Gallup PakistanDocument2 pagesViews On Divorce Rate in Pakistan 48% Believe It Has Increased, of Whom Majority Believes It Is Due To Lack of Patience: Gilani Poll/Gallup Pakistanasad usmanNo ratings yet
- Freedom of Expression Case DigestDocument65 pagesFreedom of Expression Case DigestAddy Guinal67% (3)
- Akhtamov A.A. - Reading Comprehension TestsDocument48 pagesAkhtamov A.A. - Reading Comprehension TestsKhalid TsouliNo ratings yet
- 08-05-14 EditionDocument32 pages08-05-14 EditionSan Mateo Daily JournalNo ratings yet
- Foreign Affairs Magazine Sep To OctDocument245 pagesForeign Affairs Magazine Sep To OctMomina Butt50% (2)
- GovOnlineLectureNotesch6s4 PDFDocument20 pagesGovOnlineLectureNotesch6s4 PDFArzooNo ratings yet
- Hollywood Reporter Morning Consult TV Binge Watching PollDocument19 pagesHollywood Reporter Morning Consult TV Binge Watching PollTHRNo ratings yet
- GOP of Texas 2024 R Primary Likely Voter PollDocument2 pagesGOP of Texas 2024 R Primary Likely Voter PollVerónica SilveriNo ratings yet
- Wicker PollDocument2 pagesWicker Pollthe kingfishNo ratings yet
- Mainstreet BC 02october2020Document6 pagesMainstreet BC 02october2020MainstreetNo ratings yet
- ABS-CBN Broadcasting Corporation V COMELECDocument3 pagesABS-CBN Broadcasting Corporation V COMELECxxyyNo ratings yet
- ABC News/Ipsos Poll June 13Document6 pagesABC News/Ipsos Poll June 13ABC News PoliticsNo ratings yet
- Chapter 6 OutlineDocument2 pagesChapter 6 Outlineapi-301988522No ratings yet
- MIL Q2 Module 1Document23 pagesMIL Q2 Module 1sherrylNo ratings yet
- Delhi Post Poll Survey Questionnaire (English)Document5 pagesDelhi Post Poll Survey Questionnaire (English)AashishSethiNo ratings yet
- John Eddy ResumeDocument2 pagesJohn Eddy ResumeJ EddyNo ratings yet
- Georgia Poll May 14thDocument4 pagesGeorgia Poll May 14thLindsey BasyeNo ratings yet
- Nguyễn Nhật Anh Sc 2312 Private Test 137 Mads 1600Document20 pagesNguyễn Nhật Anh Sc 2312 Private Test 137 Mads 1600anh.nguyennhat.279No ratings yet
- Demand Forecasting...Document14 pagesDemand Forecasting...anujjalansNo ratings yet
- Introduction To Quantitative Methods 1: Dr. Patrick Murphy School of Mathematical SciencesDocument21 pagesIntroduction To Quantitative Methods 1: Dr. Patrick Murphy School of Mathematical SciencesAlok AnandNo ratings yet