You might also like
- AB ConveenceDocument1 pageAB ConveencenagarajuNo ratings yet
- National Council of Educational Research and Training - HomeDocument1 pageNational Council of Educational Research and Training - HomenagarajuNo ratings yet
- ClerkDocument12 pagesClerkmalikkamaldeepNo ratings yet
- Object Oriented Software Engineering Lab Record ITCS2051Document3 pagesObject Oriented Software Engineering Lab Record ITCS2051nagarajuNo ratings yet
- New Microsoft Office Word DocumentDocument1 pageNew Microsoft Office Word DocumentnagarajuNo ratings yet
- WalkinDocument1 pageWalkinnagarajuNo ratings yet
- WalkinDocument1 pageWalkinnagarajuNo ratings yet
- Taxonomy of Bugs 2. Dichotomies 3. Transaction Flow Testing 4. Path Testing, Predicates, Achievable PathsDocument1 pageTaxonomy of Bugs 2. Dichotomies 3. Transaction Flow Testing 4. Path Testing, Predicates, Achievable PathsnagarajuNo ratings yet
- IJCSIS Copyright Transfer FormDocument2 pagesIJCSIS Copyright Transfer FormnagarajuNo ratings yet
- Students Monitoring SystemDocument2 pagesStudents Monitoring SystemnagarajuNo ratings yet
- Thota Akshay: Educational ProfileDocument2 pagesThota Akshay: Educational ProfilenagarajuNo ratings yet
- OOSEDocument76 pagesOOSEnagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Microsoft PowerPoint PresentationDocument1 pageNew Microsoft PowerPoint PresentationnagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- New Data Mining TechniqueDocument1 pageNew Data Mining TechniquenagarajuNo ratings yet
- Home Assignment - I 1Document3 pagesHome Assignment - I 1nagarajuNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- San Antonio de Padua Catholic School of Batasan Inc.: Curriculum MapDocument4 pagesSan Antonio de Padua Catholic School of Batasan Inc.: Curriculum MapMJ GuinacaranNo ratings yet
- LP English II - Africa's Plea ActivityDocument3 pagesLP English II - Africa's Plea ActivityMichael Joseph Nogoy100% (3)
- The Introvert AdvantageDocument28 pagesThe Introvert Advantagequeue201067% (3)
- Book - 1980 - Bil Tierney - Dynamics of Aspect AnalysisDocument172 pagesBook - 1980 - Bil Tierney - Dynamics of Aspect Analysispitchumani100% (12)
- Chapter 1 Educational TechnologyDocument19 pagesChapter 1 Educational TechnologyLeslie MarciaNo ratings yet
- SAP PM Codigos TDocument7 pagesSAP PM Codigos Teedee3No ratings yet
- 2.7 The Logic of Compound Statements Part 7Document50 pages2.7 The Logic of Compound Statements Part 7Edrianne Ranara Dela RamaNo ratings yet
- COMP9417 Review NotesDocument10 pagesCOMP9417 Review NotesInes SarmientoNo ratings yet
- Solution-3674 Environmental Aesthetics Assignment 1Document19 pagesSolution-3674 Environmental Aesthetics Assignment 1M Hammad Manzoor100% (1)
- SchopenhauerDocument7 pagesSchopenhauerdanielNo ratings yet
- Inclusive ClassroomDocument7 pagesInclusive Classroomsumble ssNo ratings yet
- Mental Grammar Trabajo IIDocument3 pagesMental Grammar Trabajo IIMayte Flores0% (1)
- CNN Object Detection Currency RecognitionDocument6 pagesCNN Object Detection Currency RecognitionNatasha AdvaniNo ratings yet
- Task Analysis: Story Boarding - HTADocument19 pagesTask Analysis: Story Boarding - HTANeeleshNo ratings yet
- Christopher Bollas - Forces of Destiny - Psychoanalysis and Human Idiom-Routledge (2018) PDFDocument185 pagesChristopher Bollas - Forces of Destiny - Psychoanalysis and Human Idiom-Routledge (2018) PDFoperarius100% (8)
- Reported Speech My BlogDocument20 pagesReported Speech My BlogCarlos PereaduNo ratings yet
- Technical Writting McqsDocument4 pagesTechnical Writting Mcqskamran75% (4)
- Ausubel's ReviewrDocument3 pagesAusubel's ReviewrForeducationalpurposeonlyNo ratings yet
- Sociolinguistics - Language and SocietyDocument21 pagesSociolinguistics - Language and SocietynouNo ratings yet
- Reflection Action Research PDFDocument2 pagesReflection Action Research PDFapi-232255206No ratings yet
- Take Home Examination - Hmef5023 - v2 Leong Yen XinDocument12 pagesTake Home Examination - Hmef5023 - v2 Leong Yen XinLeongYenXin100% (2)
- Test 1 - Thinking and Learning - KEYSDocument1 pageTest 1 - Thinking and Learning - KEYSДарина КоноваловаNo ratings yet
- Serious Creativity Book ReviewDocument3 pagesSerious Creativity Book Reviewsyahmi zulkepli100% (3)
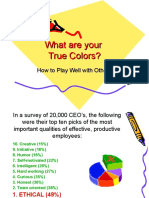
- What Are Your True Colors?Document24 pagesWhat Are Your True Colors?Kety Rosa MendozaNo ratings yet
- Year 2 Daily Lesson Plans: Skills Pedagogy (Strategy/Activity)Document5 pagesYear 2 Daily Lesson Plans: Skills Pedagogy (Strategy/Activity)Kalavathy KrishnanNo ratings yet
- Arellano University - Jose Rizal Campus: Activity Paper For English For Academic and Professional PurposesDocument3 pagesArellano University - Jose Rizal Campus: Activity Paper For English For Academic and Professional PurposesMark Angelo Maylas DomingoNo ratings yet
- BBC CourseDocument5 pagesBBC CoursemfilipelopesNo ratings yet
- Exemplar HRMDocument21 pagesExemplar HRMakhil paulNo ratings yet
- AI Brochure PDFDocument2 pagesAI Brochure PDFCuszy MusNo ratings yet
- Semiotica de La FelicidadDocument233 pagesSemiotica de La FelicidadZaiduniNo ratings yet