You might also like
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Sikkim Manipal University: Dhananjay KumarDocument5 pagesSikkim Manipal University: Dhananjay Kumarmail2dmishraNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- mk0003 Set1Document7 pagesmk0003 Set1mail2dmishraNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Diary of Anne Frank - Study GuideDocument38 pagesThe Diary of Anne Frank - Study GuideAngyf088100% (7)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Sikkim Manipal University: Dhananjay KumarDocument5 pagesSikkim Manipal University: Dhananjay Kumarmail2dmishraNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- mk0002 Set1Document21 pagesmk0002 Set1mail2dmishraNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- mk0001 Set2Document9 pagesmk0001 Set2mail2dmishraNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Sikkim Manipal University: Dhananjay KumarDocument8 pagesSikkim Manipal University: Dhananjay Kumarmail2dmishraNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Sikkim Manipal University: Dhananjay KumarDocument13 pagesSikkim Manipal University: Dhananjay Kumarmail2dmishraNo ratings yet
- MB-0035 (Set-1)Document13 pagesMB-0035 (Set-1)mail2dmishraNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- MB-0034 (Set-1)Document18 pagesMB-0034 (Set-1)mail2dmishraNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Sikkim Manipal University: Dhananjay KumarDocument6 pagesSikkim Manipal University: Dhananjay Kumarmail2dmishraNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Siemens Make Motor Manual PDFDocument10 pagesSiemens Make Motor Manual PDFArindam SamantaNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Case Study 2Document5 pagesCase Study 2api-247285537100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Synthesis, Analysis and Simulation of A Four-Bar Mechanism Using Matlab ProgrammingDocument12 pagesSynthesis, Analysis and Simulation of A Four-Bar Mechanism Using Matlab ProgrammingPedroAugustoNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Rifle May 2015 USADocument72 pagesRifle May 2015 USAhanshcNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Bom Details FormatDocument6 pagesBom Details FormatPrince MittalNo ratings yet
- Application Form InnofundDocument13 pagesApplication Form InnofundharavinthanNo ratings yet
- Brand Strategy - in B2BDocument6 pagesBrand Strategy - in B2BKrishan SahuNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Fast Track Design and Construction of Bridges in IndiaDocument10 pagesFast Track Design and Construction of Bridges in IndiaSa ReddiNo ratings yet
- Hans Belting - The End of The History of Art (1982)Document126 pagesHans Belting - The End of The History of Art (1982)Ross Wolfe100% (7)
- Presentation About GyroscopesDocument24 pagesPresentation About GyroscopesgeenjunkmailNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Comparison Between CompetitorsDocument2 pagesComparison Between Competitorsritesh singhNo ratings yet
- LM2576/LM2576HV Series Simple Switcher 3A Step-Down Voltage RegulatorDocument21 pagesLM2576/LM2576HV Series Simple Switcher 3A Step-Down Voltage RegulatorcgmannerheimNo ratings yet
- 40 People vs. Rafanan, Jr.Document10 pages40 People vs. Rafanan, Jr.Simeon TutaanNo ratings yet
- Activity On Noli Me TangereDocument5 pagesActivity On Noli Me TangereKKKNo ratings yet
- TriPac EVOLUTION Operators Manual 55711 19 OP Rev. 0-06-13Document68 pagesTriPac EVOLUTION Operators Manual 55711 19 OP Rev. 0-06-13Ariel Noya100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Deep Hole Drilling Tools: BotekDocument32 pagesDeep Hole Drilling Tools: BotekDANIEL MANRIQUEZ FAVILANo ratings yet
- Apple Change ManagementDocument31 pagesApple Change ManagementimuffysNo ratings yet
- Lieh TzuDocument203 pagesLieh TzuBrent Cullen100% (2)
- Canon Powershot S50 Repair Manual (CHAPTER 4. PARTS CATALOG) PDFDocument13 pagesCanon Powershot S50 Repair Manual (CHAPTER 4. PARTS CATALOG) PDFRita CaselliNo ratings yet
- Sandstorm Absorbent SkyscraperDocument4 pagesSandstorm Absorbent SkyscraperPardisNo ratings yet
- ISO 27001 Introduction Course (05 IT01)Document56 pagesISO 27001 Introduction Course (05 IT01)Sheik MohaideenNo ratings yet
- Out PDFDocument211 pagesOut PDFAbraham RojasNo ratings yet
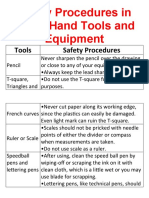
- Safety Procedures in Using Hand Tools and EquipmentDocument12 pagesSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNo ratings yet
- SSP 237 d1Document32 pagesSSP 237 d1leullNo ratings yet
- PC Model Answer Paper Winter 2016Document27 pagesPC Model Answer Paper Winter 2016Deepak VermaNo ratings yet
- 2022 Mable Parker Mclean Scholarship ApplicationDocument2 pages2022 Mable Parker Mclean Scholarship Applicationapi-444959661No ratings yet
- Evs ProjectDocument19 pagesEvs ProjectSaloni KariyaNo ratings yet
- Performance Task 1Document3 pagesPerformance Task 1Jellie May RomeroNo ratings yet
- Test 51Document7 pagesTest 51Nguyễn Hiền Giang AnhNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Rana2 Compliment As Social StrategyDocument12 pagesRana2 Compliment As Social StrategyRanaNo ratings yet