You might also like
- VHDL IntroductionDocument100 pagesVHDL IntroductionDhaval ShuklaNo ratings yet
- Assignment Microprocessor 8085Document2 pagesAssignment Microprocessor 8085Dhaval Shukla100% (1)
- Self Biased Cascode CM PDFDocument7 pagesSelf Biased Cascode CM PDFDhaval ShuklaNo ratings yet
- Solution MPI PDFDocument5 pagesSolution MPI PDFDhaval ShuklaNo ratings yet
- CMOS Lab Assignment-1 Digital Circuit Schematics and SimulationsDocument1 pageCMOS Lab Assignment-1 Digital Circuit Schematics and SimulationsDhaval ShuklaNo ratings yet
- CMOS Assignment 1Document1 pageCMOS Assignment 1Dhaval ShuklaNo ratings yet
- National Common Minimum Program - 2004Document8 pagesNational Common Minimum Program - 2004Piyush KulshreshthaNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- MSTP US Style GuideDocument1,078 pagesMSTP US Style GuideNupur RNo ratings yet
- Web Site Name:: MSBI: SSIS, SSRS, SSAS Interview Questions and AnswersDocument2 pagesWeb Site Name:: MSBI: SSIS, SSRS, SSAS Interview Questions and AnswersatoztargetNo ratings yet
- Introduction & Product Overview: Ian Maynard - Senior Engineer EMEADocument22 pagesIntroduction & Product Overview: Ian Maynard - Senior Engineer EMEAМахендра СингхNo ratings yet
- Wireless Network ProjectDocument44 pagesWireless Network Projectstratack99% (101)
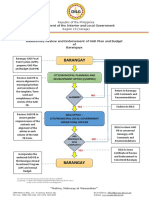
- Flow Chart On The Review of LGUs GAD Plan and BudgetDocument1 pageFlow Chart On The Review of LGUs GAD Plan and BudgetPerzi ValNo ratings yet
- Huawei BGP EVPN WorkDocument23 pagesHuawei BGP EVPN WorkAbdelhaiNo ratings yet
- Mission3-Cisco CCAI - Agent Answers Configuration Part 1-LGDocument8 pagesMission3-Cisco CCAI - Agent Answers Configuration Part 1-LGKleber RodriguesNo ratings yet
- Hariz Mulya Wibawa: ProfileDocument2 pagesHariz Mulya Wibawa: Profileradit.d.hikenNo ratings yet
- FirewallDocument21 pagesFirewallShlok MukkawarNo ratings yet
- A Survey On Wieless Sensor Networks Simulation Tools and TestbedsDocument21 pagesA Survey On Wieless Sensor Networks Simulation Tools and TestbedsJesús Quintero BorregoNo ratings yet
- Quadrature Amplitude ModulationDocument10 pagesQuadrature Amplitude ModulationSafirinaFebryantiNo ratings yet
- CXZOSAdminGuide en PDFDocument354 pagesCXZOSAdminGuide en PDFCassio CristianoNo ratings yet
- The Ribbon Communications SBC 1000™ Session Border ControllerDocument4 pagesThe Ribbon Communications SBC 1000™ Session Border ControllerHary RatraNo ratings yet
- HL-L2370DN Compact Mono Laser PrinterDocument5 pagesHL-L2370DN Compact Mono Laser PrinterTestNo ratings yet
- H.265/HEVC Video Transmission Over 4G Cellular NetworksDocument82 pagesH.265/HEVC Video Transmission Over 4G Cellular Networksweito2003No ratings yet
- Sg244656 - Subarea To APPN Migration - VTAM and APPN ImplementationDocument290 pagesSg244656 - Subarea To APPN Migration - VTAM and APPN ImplementationO. SalvianoNo ratings yet
- Leased LineDocument5 pagesLeased LineAditya kaushikNo ratings yet
- Alarm Box User ManualDocument37 pagesAlarm Box User ManualgetlibinNo ratings yet
- V2801 Series Product IntroductionDocument13 pagesV2801 Series Product IntroductionVicente NettoNo ratings yet
- Resume GerminDocument4 pagesResume Germinlingesh1892No ratings yet
- Radio Network FlowchartDocument16 pagesRadio Network FlowchartChiheb BerrabahNo ratings yet
- Orbcomm Ip Gateway Apivcd2Document52 pagesOrbcomm Ip Gateway Apivcd2Magdalena TerrasaNo ratings yet
- SAP SMS 365 - International SMS Product Description - V4.2Document30 pagesSAP SMS 365 - International SMS Product Description - V4.2Athanasios LioumpasNo ratings yet
- UDP Message FormatDocument5 pagesUDP Message FormatGauravNo ratings yet
- Synopsis of E-LearningDocument5 pagesSynopsis of E-LearningSachin Verma100% (5)
- M2000 Northbound MML Command Interface Developer GuideDocument39 pagesM2000 Northbound MML Command Interface Developer GuideWidagdho WidyoNo ratings yet
- Av, CCTV, Acs, Pa SpecsDocument85 pagesAv, CCTV, Acs, Pa SpecsMohamed Abou El hassanNo ratings yet
- Mobile Transport LayerDocument18 pagesMobile Transport LayervalansterNo ratings yet
- Assignment-W2 Nptel NotesDocument6 pagesAssignment-W2 Nptel NotesAshishNo ratings yet
- User Manual IES-3160 V1.3Document105 pagesUser Manual IES-3160 V1.3oring2012No ratings yet