You might also like
- Occult ChemistryDocument142 pagesOccult ChemistryMahaotNo ratings yet
- Parapsychology: Parapsychology Is The Study of Alleged Psychic PhenomenaDocument43 pagesParapsychology: Parapsychology Is The Study of Alleged Psychic Phenomenamarga ritaNo ratings yet
- FullIndex To Communal Societies Through 36 2 SargentDocument64 pagesFullIndex To Communal Societies Through 36 2 SargentGuzmán de CastroNo ratings yet
- Strahlenfolter Stalking - Major Electromagnetic Mind Control ProjectsDocument2 pagesStrahlenfolter Stalking - Major Electromagnetic Mind Control ProjectsParanoia.war.gesternNo ratings yet
- Magical States of Consciousness: Secrets of Pathworking: by Osborne PhillipsDocument13 pagesMagical States of Consciousness: Secrets of Pathworking: by Osborne PhillipsGEORGE EMANUEL DANCIU100% (1)
- The Surreptitious Reincarnation of COINTELPRO With The COPS Gang-Stalking Program August 22, 2016 Written by Rahul D. Manchanda, Esq.Document14 pagesThe Surreptitious Reincarnation of COINTELPRO With The COPS Gang-Stalking Program August 22, 2016 Written by Rahul D. Manchanda, Esq.Stan J. Caterbone100% (2)
- Cell PysiologyDocument38 pagesCell PysiologyKriztine Mae GonzalesNo ratings yet
- Mantichor E: Mantic NotesDocument9 pagesMantichor E: Mantic NotesLeigh BlackmoreNo ratings yet
- Operation INFEKTION - Soviet Bloc Intelligence and Its AIDS Disinformation CampaignDocument24 pagesOperation INFEKTION - Soviet Bloc Intelligence and Its AIDS Disinformation CampaignCleverton RamosNo ratings yet
- Mobilizing PeopleDocument23 pagesMobilizing PeopleJenine SipaganNo ratings yet
- The Epic of Gilgamesh A Spiritual Biogra PDFDocument28 pagesThe Epic of Gilgamesh A Spiritual Biogra PDFLuanaNo ratings yet
- Gabion Retaining Wall Design GuideDocument30 pagesGabion Retaining Wall Design GuideThomas Hill80% (5)
- Mitsubishi diesel forklifts 1.5-3.5 tonnesDocument2 pagesMitsubishi diesel forklifts 1.5-3.5 tonnesJoniNo ratings yet
- THKDocument1,901 pagesTHKapi-26356646No ratings yet
- Indigenous Radars PDFDocument16 pagesIndigenous Radars PDFsmsarmadNo ratings yet
- Magic On The Mind Physicists' Use of MetaphorDocument6 pagesMagic On The Mind Physicists' Use of Metaphorm68_xNo ratings yet
- Strahlenfolter - TI - 9nania - My Story - Secret Tech, Mind Control & Other Weird Stuff - Playlist - YoutubeDocument13 pagesStrahlenfolter - TI - 9nania - My Story - Secret Tech, Mind Control & Other Weird Stuff - Playlist - YoutubeTimo_KaehlkeNo ratings yet
- CIA Gov Library Center For The Study of Intelligence Drugs Ineffective in InterogationDocument8 pagesCIA Gov Library Center For The Study of Intelligence Drugs Ineffective in InterogationAlan Jules WebermanNo ratings yet
- Programming languages as religions comparisonDocument2 pagesProgramming languages as religions comparisonrqNo ratings yet
- Training Matrix For TM IDocument14 pagesTraining Matrix For TM IApril NavaretteNo ratings yet
- The Most Terrifying Thought Experiment of All TimeDocument7 pagesThe Most Terrifying Thought Experiment of All Timedimos katerinaNo ratings yet
- Talking To The Future Humans - DR Jack Sarfatti Thinks I'm An IdiotDocument4 pagesTalking To The Future Humans - DR Jack Sarfatti Thinks I'm An IdiotThe RearrangerNo ratings yet
- Hawkins, Jaq - Elemental ChaosDocument3 pagesHawkins, Jaq - Elemental Chaoscaligari2000No ratings yet
- OscillationDocument6 pagesOscillationAliceAlormenuNo ratings yet
- Reading Non-Verbal Cues in Jamie Uys's The Gods Must Be Crazy: A Subliminal and Semiotic AnalysisDocument11 pagesReading Non-Verbal Cues in Jamie Uys's The Gods Must Be Crazy: A Subliminal and Semiotic AnalysisIJELS Research JournalNo ratings yet
- 666 ChipDocument18 pages666 Chipapi-3696230100% (2)
- An Incremental Approach To Compiler ConstructionDocument11 pagesAn Incremental Approach To Compiler ConstructionasmirNo ratings yet
- Homa 2 CalculatorDocument6 pagesHoma 2 CalculatorAnonymous 4dE7mUCIH0% (1)
- Nathaniel Biafore - Discussion Questions For The Matrix 3Document3 pagesNathaniel Biafore - Discussion Questions For The Matrix 3api-617845760No ratings yet
- United States Patent (19) : (45) Date of Patent: Oct. 12, 1999Document17 pagesUnited States Patent (19) : (45) Date of Patent: Oct. 12, 1999KrozeNo ratings yet
- COE 205 Lab ManualDocument110 pagesCOE 205 Lab Manualmadhu1983aug30No ratings yet
- Dynamic Modeling of GE 1.5 andDocument31 pagesDynamic Modeling of GE 1.5 andErtuğrul ÇamNo ratings yet
- Curtis CatalogDocument9 pagesCurtis CatalogtharngalNo ratings yet
- Grade 5 Mtap Compilation 2011,2013 2015 2016 2017 Division OralsDocument5 pagesGrade 5 Mtap Compilation 2011,2013 2015 2016 2017 Division OralsChristine De San JoseNo ratings yet
- Operational Guidelines For VlsfoDocument2 pagesOperational Guidelines For VlsfoИгорьNo ratings yet
- SteganographyDocument28 pagesSteganographyGanesh PahadeNo ratings yet
- Eleonor WhiteDocument64 pagesEleonor WhiteSimon BenjaminNo ratings yet
- WWW Citizensaht Org Implant TechDocument30 pagesWWW Citizensaht Org Implant TechLazlo JoószNo ratings yet
- Subliminal Channels in DSA CryptographyDocument15 pagesSubliminal Channels in DSA CryptographyJingan AlnaNo ratings yet
- Studying Hawking Radiation Using a Desktop Sonic Black HoleDocument4 pagesStudying Hawking Radiation Using a Desktop Sonic Black HoleadimeghaNo ratings yet
- War On HumanityDocument4 pagesWar On Humanityjanhendrik4444No ratings yet
- X - NG - Jack Kerouac, On The Nobody Again - Paranormal - 4chanDocument34 pagesX - NG - Jack Kerouac, On The Nobody Again - Paranormal - 4chanAnonymous dIjB7XD8ZNo ratings yet
- Classification of The Approaches To The Technological - ResurrectionDocument29 pagesClassification of The Approaches To The Technological - Resurrectionteh chia weiNo ratings yet
- CIA Kubark 61-112Document52 pagesCIA Kubark 61-112Luca BredaNo ratings yet
- If You Stop Speaking They Kill You Kind of Freedom Volume1Document13 pagesIf You Stop Speaking They Kill You Kind of Freedom Volume1Waris WaljiNo ratings yet
- Physis ManualDocument19 pagesPhysis ManualMax anykeyNo ratings yet
- Seminar On CryptographyDocument13 pagesSeminar On CryptographyDeepak RathoreNo ratings yet
- Human Sacrifice in Ancient EgyptDocument3 pagesHuman Sacrifice in Ancient EgyptJennifer C. Johnson100% (1)
- Emil Cioran QuotesDocument8 pagesEmil Cioran QuotesAlannah RichardsNo ratings yet
- The Psychic World of Stanley KrippnerDocument8 pagesThe Psychic World of Stanley KrippnerlakisNo ratings yet
- Spectral Souls PSPDocument33 pagesSpectral Souls PSPTomas CereskeviciusNo ratings yet
- Newcomb's Problem: Two Compelling Yet Opposing ArgumentsDocument17 pagesNewcomb's Problem: Two Compelling Yet Opposing ArgumentsFigiW100% (1)
- SteganographyDocument32 pagesSteganographysubashreeNo ratings yet
- The Proper Protection of Human Thought TN ElWikosian BookDocument169 pagesThe Proper Protection of Human Thought TN ElWikosian Bookvulture53No ratings yet
- CIA Final Response Letter RE Hunter ThompsonDocument1 pageCIA Final Response Letter RE Hunter ThompsonRobNo ratings yet
- Short Detail of RNM UserDocument2 pagesShort Detail of RNM UserKunalNo ratings yet
- Walk On WaterDocument4 pagesWalk On Waterjoebob19No ratings yet
- De-Vermis-Mysteriis - Luwig PrinnDocument188 pagesDe-Vermis-Mysteriis - Luwig PrinnWladimir CotrinaNo ratings yet
- MIND READING WITH PHONESDocument5 pagesMIND READING WITH PHONESSiva SankarNo ratings yet
- The Night Beast AwakensDocument2 pagesThe Night Beast Awakensmwaite22No ratings yet
- Texe Marrs - Codex Magica - Secret Signs, Mysterious Symbols, and Hidden Codes of The Illuminati (2005)Document588 pagesTexe Marrs - Codex Magica - Secret Signs, Mysterious Symbols, and Hidden Codes of The Illuminati (2005)musichristianNo ratings yet
- Linorix HubDocument2 pagesLinorix HublolzNo ratings yet
- John ConstantineDocument2 pagesJohn ConstantinePrussianCommandNo ratings yet
- DreamSpeak 50 Matt Jones PDFDocument7 pagesDreamSpeak 50 Matt Jones PDFbustalNo ratings yet
- The Bio Machine Language: How To Sync The Mind With MachinesFrom EverandThe Bio Machine Language: How To Sync The Mind With MachinesNo ratings yet
- Compiler Construction: Niklaus WirthDocument44 pagesCompiler Construction: Niklaus WirthanikaNo ratings yet
- How a microprocessor executes a program in RAMDocument16 pagesHow a microprocessor executes a program in RAMismail253No ratings yet
- Laboratory Exercise 1Document18 pagesLaboratory Exercise 1amitkumar_87No ratings yet
- Microprocessor, Microcomputer and Associated Languages 1Document10 pagesMicroprocessor, Microcomputer and Associated Languages 1Daryl ScottNo ratings yet
- Leveling Limits For Stationary Reciprocating Compressors: Engineering ReferenceDocument2 pagesLeveling Limits For Stationary Reciprocating Compressors: Engineering ReferencealtruismNo ratings yet
- R8557B KCGGDocument178 pagesR8557B KCGGRinda_RaynaNo ratings yet
- Tesla Regen, Brakes and Sudden AccelerationDocument66 pagesTesla Regen, Brakes and Sudden AccelerationmartinvvNo ratings yet
- Rodi TestSystem EZSDI1 Iom D603Document25 pagesRodi TestSystem EZSDI1 Iom D603Ricardo AndradeNo ratings yet
- Winegard Sensar AntennasDocument8 pagesWinegard Sensar AntennasMichael ColeNo ratings yet
- Comparative Study Between Vyatra 3 and Vyatra 4 WBMDocument9 pagesComparative Study Between Vyatra 3 and Vyatra 4 WBMFatih RakaNo ratings yet
- Velocity profiles and incompressible flow field equationsDocument2 pagesVelocity profiles and incompressible flow field equationsAbdul ArifNo ratings yet
- 4495 10088 1 PBDocument7 pages4495 10088 1 PBGeorgius Kent DiantoroNo ratings yet
- General 04 Fixed Flow Pump To Three TanksDocument13 pagesGeneral 04 Fixed Flow Pump To Three TanksjpalauguillemNo ratings yet
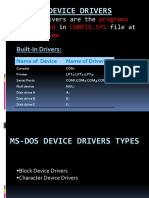
- Ms-Dos Device Drivers: Device Drivers Are The That in File atDocument13 pagesMs-Dos Device Drivers: Device Drivers Are The That in File atJass GillNo ratings yet
- USB GPW CB03 MT02 - EngDocument21 pagesUSB GPW CB03 MT02 - EngRafael BispoNo ratings yet
- College of Information Technology Dmmmsu-Mluc City of San FernandoDocument9 pagesCollege of Information Technology Dmmmsu-Mluc City of San FernandoZoilo BagtangNo ratings yet
- Unit 10Document18 pagesUnit 10ChaithraMalluNo ratings yet
- Efficiency Evaluation of The Ejector Cooling Cycle PDFDocument18 pagesEfficiency Evaluation of The Ejector Cooling Cycle PDFzoom_999No ratings yet
- Sensors 22 09378 v2Document13 pagesSensors 22 09378 v2FahdNo ratings yet
- Lecture 1: Encoding Language: LING 1330/2330: Introduction To Computational Linguistics Na-Rae HanDocument18 pagesLecture 1: Encoding Language: LING 1330/2330: Introduction To Computational Linguistics Na-Rae HanLaura AmwayiNo ratings yet
- 1.11 CHEM FINAL Chapter 11 Sulfuric AcidDocument21 pages1.11 CHEM FINAL Chapter 11 Sulfuric AcidSudhanshuNo ratings yet
- Measurements/ Specifications: Torque Wrench Selection GuideDocument5 pagesMeasurements/ Specifications: Torque Wrench Selection GuideSylvester RakgateNo ratings yet
- Recommended Procedures For Internet-Based Connections Between Rths and Nmcs (VPN, Ipsec)Document38 pagesRecommended Procedures For Internet-Based Connections Between Rths and Nmcs (VPN, Ipsec)Crismaruc Maria-madalinaNo ratings yet
- Database Classification TypesDocument10 pagesDatabase Classification TypesBhiea Mische MatilacNo ratings yet
- Alc10 DatasheetDocument7 pagesAlc10 Datasheetd4l170No ratings yet