You might also like
- Srs 26022013 For ClusteringDocument17 pagesSrs 26022013 For ClusteringMaram Nagarjuna ReddyNo ratings yet
- DataStage Advanced Parallel GuideDocument899 pagesDataStage Advanced Parallel GuideSagarNo ratings yet
- Ijet V2i3p7Document6 pagesIjet V2i3p7International Journal of Engineering and TechniquesNo ratings yet
- Analysis of Log Data and Statistics Report Generation Using HadoopDocument5 pagesAnalysis of Log Data and Statistics Report Generation Using HadoopPradipsinh ChavdaNo ratings yet
- Re-Enactment of Newspaper ArticlesDocument4 pagesRe-Enactment of Newspaper ArticlesATSNo ratings yet
- Context Based Web Indexing For Semantic Web: Anchal Jain Nidhi TyagiDocument5 pagesContext Based Web Indexing For Semantic Web: Anchal Jain Nidhi TyagiInternational Organization of Scientific Research (IOSR)No ratings yet
- DoCEIS2013 - BrainMap - A Navigation Support System in A Tourism Case StudyDocument8 pagesDoCEIS2013 - BrainMap - A Navigation Support System in A Tourism Case StudybromeroviateclaNo ratings yet
- Chapter 1: Introduction: Efficient Search in Large Textual Collections With Redundancy - 2009Document31 pagesChapter 1: Introduction: Efficient Search in Large Textual Collections With Redundancy - 2009tibinttNo ratings yet
- Chapter - 6 Part 1Document21 pagesChapter - 6 Part 1CLAsH with DxNo ratings yet
- Ijarcce.2019.81220text Gen ModelDocument6 pagesIjarcce.2019.81220text Gen ModelUma MaheshwarNo ratings yet
- Multi-Document Extractive Summarization For News Page 1 of 59Document59 pagesMulti-Document Extractive Summarization For News Page 1 of 59athar1988No ratings yet
- Indexing: 1. Static and Dynamic Inverted IndexDocument55 pagesIndexing: 1. Static and Dynamic Inverted IndexVaibhav Garg100% (1)
- CHAP 4 Inverted IndexDocument21 pagesCHAP 4 Inverted IndexsuperzanhotmailNo ratings yet
- Multilevel Index Algorithm in Search EngineDocument4 pagesMultilevel Index Algorithm in Search Enginesaeedullah81No ratings yet
- Significance of HTML Tags For Document Indexing and RetrievalDocument4 pagesSignificance of HTML Tags For Document Indexing and RetrievalJoyce Salles ArbajaNo ratings yet
- Efficient Online Index Construction For Text Databases 08Document33 pagesEfficient Online Index Construction For Text Databases 08Simon WistowNo ratings yet
- Sentiment Analysis On Twitter Hashtag DatasetsDocument6 pagesSentiment Analysis On Twitter Hashtag DatasetsIJRASETPublicationsNo ratings yet
- A Comparison of Open Source Search EngineDocument46 pagesA Comparison of Open Source Search EngineZamah SyariNo ratings yet
- The Observed Preprocessing Strategies For Doing Automatic Text SummarizingDocument8 pagesThe Observed Preprocessing Strategies For Doing Automatic Text SummarizingCSIT iaesprimeNo ratings yet
- SUMSEM2022-23 CSE3024 ETH VL2022230700533 2023-05-22 Reference-Material-IDocument7 pagesSUMSEM2022-23 CSE3024 ETH VL2022230700533 2023-05-22 Reference-Material-ISarthak VermaNo ratings yet
- On-Line Index Maintenance Using Horizontal Partitioning: Sairam Gurajada Sreenivasa Kumar PDocument9 pagesOn-Line Index Maintenance Using Horizontal Partitioning: Sairam Gurajada Sreenivasa Kumar PAmit ChandakNo ratings yet
- Contextual Information Search Based On Domain Using Query ExpansionDocument4 pagesContextual Information Search Based On Domain Using Query ExpansionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Machine Translation Using Natural Language ProcessDocument6 pagesMachine Translation Using Natural Language ProcessFidelzy MorenoNo ratings yet
- An Automatic Text Summarization Using Feature Terms For Relevance MeasureDocument5 pagesAn Automatic Text Summarization Using Feature Terms For Relevance MeasureInternational Organization of Scientific Research (IOSR)No ratings yet
- Methods and Techniques For Recommender Systems in Secure Software Engineering A Literature ReviewDocument7 pagesMethods and Techniques For Recommender Systems in Secure Software Engineering A Literature ReviewInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Document Text Classification Using Support Vector MachineDocument5 pagesDocument Text Classification Using Support Vector MachinerohitNo ratings yet
- OperatingDocument3 pagesOperatingHemang JainNo ratings yet
- Quantization of Product Using Collaborative Filtering Based On ClusterDocument9 pagesQuantization of Product Using Collaborative Filtering Based On ClusterIJRASETPublicationsNo ratings yet
- Ijaret: ©iaemeDocument11 pagesIjaret: ©iaemeIAEME PublicationNo ratings yet
- Document Ranking Using Customizes Vector MethodDocument6 pagesDocument Ranking Using Customizes Vector MethodEditor IJTSRDNo ratings yet
- Assessment 2Document3 pagesAssessment 2FVRNo ratings yet
- A Statistical Approach To Perform Web Based Summarization: Kirti Bhatia, Dr. Rajendar ChhillarDocument3 pagesA Statistical Approach To Perform Web Based Summarization: Kirti Bhatia, Dr. Rajendar ChhillarInternational Organization of Scientific Research (IOSR)No ratings yet
- Information Processing and Management: Richard Mccreadie, Craig Macdonald, Iadh OunisDocument16 pagesInformation Processing and Management: Richard Mccreadie, Craig Macdonald, Iadh OunisJemy ArieswantoNo ratings yet
- Sentiment Analysis On IMDB Movie Comments and TwitDocument8 pagesSentiment Analysis On IMDB Movie Comments and TwitNauffan MuftiNo ratings yet
- A Graph Based Keyword Extraction Model Using Collective Node WeightDocument9 pagesA Graph Based Keyword Extraction Model Using Collective Node WeighthalloweenNo ratings yet
- Project 2020 ENDocument4 pagesProject 2020 ENPanagiotis PapadakosNo ratings yet
- A Survey - Ontology Based Information Retrieval in Semantic WebDocument8 pagesA Survey - Ontology Based Information Retrieval in Semantic WebMayank SinghNo ratings yet
- MS CS Manipal University Ashish Kumar Jha Data Structures and Algorithms Used in Search EngineDocument13 pagesMS CS Manipal University Ashish Kumar Jha Data Structures and Algorithms Used in Search EngineAshish Kumar JhaNo ratings yet
- 1 PDFDocument28 pages1 PDFqaro kaduNo ratings yet
- PDC Review2Document23 pagesPDC Review2corote1026No ratings yet
- Camera Ready PaperDocument5 pagesCamera Ready PaperAdesh DhakaneNo ratings yet
- Twespa A Modern Approach To Twitter Sentiment AnalysisDocument7 pagesTwespa A Modern Approach To Twitter Sentiment AnalysisIJRASETPublicationsNo ratings yet
- Query Sensitive Comparative Summarization of Search Results Using Concept Based SegmentationDocument13 pagesQuery Sensitive Comparative Summarization of Search Results Using Concept Based SegmentationcseijNo ratings yet
- Sentiment Analysis On Amazon Fine Food Reviews by Using Linear Machine Learning ModelsDocument6 pagesSentiment Analysis On Amazon Fine Food Reviews by Using Linear Machine Learning ModelsIJRASETPublicationsNo ratings yet
- Web Mining: Day-Today: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)Document4 pagesWeb Mining: Day-Today: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- An Approach For Design Search Engine Architecture For Document SummarizationDocument6 pagesAn Approach For Design Search Engine Architecture For Document SummarizationEditor IJRITCCNo ratings yet
- Information Management System Using LINQ OverDocument3 pagesInformation Management System Using LINQ Overeditor_ijarcsseNo ratings yet
- Web Based Chat BotDocument7 pagesWeb Based Chat BotLucky BujjiNo ratings yet
- Learn Able CrawlerDocument6 pagesLearn Able Crawlerjay sharmaNo ratings yet
- Movie Recommendation - 01Document7 pagesMovie Recommendation - 01sudulagunta aksharaNo ratings yet
- SQL Server Full Text SearchDocument5 pagesSQL Server Full Text SearchHasleen GujralNo ratings yet
- A Comparative Analysis of Automatic Text Summarization (ATS) Using Scoring TechniqueDocument11 pagesA Comparative Analysis of Automatic Text Summarization (ATS) Using Scoring TechniqueIJRASETPublicationsNo ratings yet
- NAAC Accredited ''A" D. E. Society's: "Rainfall Analysis in India "Document21 pagesNAAC Accredited ''A" D. E. Society's: "Rainfall Analysis in India "gunjan jadhavNo ratings yet
- Design and Implementation of A Simple Web Search EDocument9 pagesDesign and Implementation of A Simple Web Search EajaykumarbmsitNo ratings yet
- Advance Assessment Evaluation: A Deep-Learning Framework With Sophisticated Text Extraction For Unparalleled PrecisionDocument8 pagesAdvance Assessment Evaluation: A Deep-Learning Framework With Sophisticated Text Extraction For Unparalleled PrecisionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Easychair Preprint: Pallavi Kohakade and Sujata JadhavDocument5 pagesEasychair Preprint: Pallavi Kohakade and Sujata JadhavsauravNo ratings yet
- NAAC Accredited ''A" D. E. Society's: "Rainfall in India Analysis"Document21 pagesNAAC Accredited ''A" D. E. Society's: "Rainfall in India Analysis"gunjan jadhavNo ratings yet
- Abstractive Text Summarization Using Deep LearningDocument7 pagesAbstractive Text Summarization Using Deep LearningIJRASETPublicationsNo ratings yet
- AP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceFrom EverandAP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceNo ratings yet
- LOTED: a semantic web portal for the management of tenders from the European CommunityFrom EverandLOTED: a semantic web portal for the management of tenders from the European CommunityNo ratings yet
- Compusoft, 1 (1), 8-12Document5 pagesCompusoft, 1 (1), 8-12Ijact EditorNo ratings yet
- Compusoft, 2 (5), 108-113 PDFDocument6 pagesCompusoft, 2 (5), 108-113 PDFIjact EditorNo ratings yet
- Implementation of Digital Watermarking Using MATLAB SoftwareDocument7 pagesImplementation of Digital Watermarking Using MATLAB SoftwareIjact EditorNo ratings yet
- Compusoft, 2 (5), 114-120 PDFDocument7 pagesCompusoft, 2 (5), 114-120 PDFIjact EditorNo ratings yet
- Graphical Password Authentication Scheme Using CloudDocument3 pagesGraphical Password Authentication Scheme Using CloudIjact EditorNo ratings yet
- Compusoft, 2 (5), 127-129 PDFDocument3 pagesCompusoft, 2 (5), 127-129 PDFIjact EditorNo ratings yet
- Compusoft, 2 (5), 121-126 PDFDocument6 pagesCompusoft, 2 (5), 121-126 PDFIjact EditorNo ratings yet
- Attacks Analysis and Countermeasures in Routing Protocols of Mobile Ad Hoc NetworksDocument6 pagesAttacks Analysis and Countermeasures in Routing Protocols of Mobile Ad Hoc NetworksIjact EditorNo ratings yet
- A New Cryptographic Scheme With Modified Diffusion For Digital ImagesDocument6 pagesA New Cryptographic Scheme With Modified Diffusion For Digital ImagesIjact EditorNo ratings yet
- Information Technology in Human Resource Management: A Practical EvaluationDocument6 pagesInformation Technology in Human Resource Management: A Practical EvaluationIjact EditorNo ratings yet
- Role of Information Technology in Supply Chain ManagementDocument3 pagesRole of Information Technology in Supply Chain ManagementIjact EditorNo ratings yet
- Impact of E-Governance and Its Challenges in Context To IndiaDocument4 pagesImpact of E-Governance and Its Challenges in Context To IndiaIjact Editor100% (1)
- Audit Planning For Investigating Cyber CrimesDocument4 pagesAudit Planning For Investigating Cyber CrimesIjact EditorNo ratings yet
- Compusoft, 3 (12), 1386-1396 PDFDocument11 pagesCompusoft, 3 (12), 1386-1396 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1377-1385 PDFDocument9 pagesCompusoft, 3 (12), 1377-1385 PDFIjact EditorNo ratings yet
- Measurement, Analysis and Data Collection in The Programming LabVIEWDocument5 pagesMeasurement, Analysis and Data Collection in The Programming LabVIEWIjact EditorNo ratings yet
- Recent Advances in Risk Analysis and Management (RAM)Document5 pagesRecent Advances in Risk Analysis and Management (RAM)Ijact EditorNo ratings yet
- Adaptive Firefly Optimization On Reducing High Dimensional Weighted Word Affinity GraphDocument5 pagesAdaptive Firefly Optimization On Reducing High Dimensional Weighted Word Affinity GraphIjact EditorNo ratings yet
- Archiving Data From The Operating System AndroidDocument5 pagesArchiving Data From The Operating System AndroidIjact EditorNo ratings yet
- Compusoft, 3 (12), 1360-1363 PDFDocument4 pagesCompusoft, 3 (12), 1360-1363 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1374-1376 PDFDocument3 pagesCompusoft, 3 (12), 1374-1376 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1369-1373 PDFDocument5 pagesCompusoft, 3 (12), 1369-1373 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1354-1359 PDFDocument6 pagesCompusoft, 3 (12), 1354-1359 PDFIjact EditorNo ratings yet
- Compusoft, 3 (11), 1337-1342 PDFDocument6 pagesCompusoft, 3 (11), 1337-1342 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1364-1368 PDFDocument5 pagesCompusoft, 3 (12), 1364-1368 PDFIjact EditorNo ratings yet
- Compusoft, 3 (11), 1343-1349 PDFDocument8 pagesCompusoft, 3 (11), 1343-1349 PDFIjact EditorNo ratings yet
- Compusoft, 3 (12), 1350-1353 PDFDocument4 pagesCompusoft, 3 (12), 1350-1353 PDFIjact EditorNo ratings yet
- Compusoft, 3 (11), 1327-1336 PDFDocument10 pagesCompusoft, 3 (11), 1327-1336 PDFIjact EditorNo ratings yet
- Compusoft, 3 (11), 1317-1326 PDFDocument10 pagesCompusoft, 3 (11), 1317-1326 PDFIjact EditorNo ratings yet
- Bee Gees - One Night OnlyDocument1 pageBee Gees - One Night OnlyothonoNo ratings yet
- 5 Steps To A 5 Ap Computer Science Principles 2024 Julie Schacht Sway Full ChapterDocument67 pages5 Steps To A 5 Ap Computer Science Principles 2024 Julie Schacht Sway Full Chapterdeborah.scott238100% (5)
- Questions of CommunicationDocument9 pagesQuestions of CommunicationShimaa KashefNo ratings yet
- Neural Network Unsupervised Machine Learning: What Are Autoencoders?Document22 pagesNeural Network Unsupervised Machine Learning: What Are Autoencoders?shubh agrawalNo ratings yet
- Cracking PDFDocument22 pagesCracking PDFJohn "BiggyJ" Dumas100% (2)
- Applications of Finite AutomataDocument27 pagesApplications of Finite AutomataWaqas ShahidNo ratings yet
- Laboratory ManualDocument184 pagesLaboratory Manualviswanath kaniNo ratings yet
- Canon 5D Mark III Review - VideoDocument10 pagesCanon 5D Mark III Review - VideoManrico Montero CalzadiazNo ratings yet
- Lesson 8: Opportunities, Challenges, and Power of Media and InformationDocument7 pagesLesson 8: Opportunities, Challenges, and Power of Media and InformationJonalyn Cayog CarbonelNo ratings yet
- Voluson S6 Data SheetDocument15 pagesVoluson S6 Data SheetNanang YlNo ratings yet
- Importing Geodata TutorialDocument24 pagesImporting Geodata TutorialJohn KingsleyNo ratings yet
- Haivision 1000 TLDocument44 pagesHaivision 1000 TLRobertNo ratings yet
- JPEG Image CompressionDocument54 pagesJPEG Image CompressionJonathan EvangelistaNo ratings yet
- Abel DamtewDocument114 pagesAbel DamtewshegawNo ratings yet
- Final - MTech-Cyber Security SyllabusDocument58 pagesFinal - MTech-Cyber Security SyllabusMunivel EllappanNo ratings yet
- CELPDocument23 pagesCELPANeek181No ratings yet
- LZW (Lempel Ziv Welch) : 60.1 Brief HistoryDocument4 pagesLZW (Lempel Ziv Welch) : 60.1 Brief HistoryMuziKhumaloNo ratings yet
- DS-7200HUHI-K1 SERIES Turbo HD DVR: Key FeatureDocument4 pagesDS-7200HUHI-K1 SERIES Turbo HD DVR: Key FeatureRadu GălățanNo ratings yet
- Torrent Suite User DocumentationDocument218 pagesTorrent Suite User DocumentationRupert YipNo ratings yet
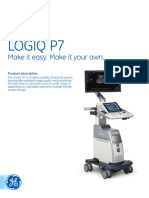
- Logiq p7 Data Sheet PDFDocument11 pagesLogiq p7 Data Sheet PDFMsadir KhanNo ratings yet
- Video Steganography PDFDocument5 pagesVideo Steganography PDFgunesh1No ratings yet
- Oracle Partitioning in Oracle Database 11gDocument47 pagesOracle Partitioning in Oracle Database 11gDudi KumarNo ratings yet
- CamStudio HelpDocument30 pagesCamStudio HelpRajesh KhatavkarNo ratings yet
- j276 - 02 May 2019 QP Ocr Gcse Computer ScienceDocument24 pagesj276 - 02 May 2019 QP Ocr Gcse Computer SciencebobNo ratings yet
- Tg11 Ict Model Book VZ 2016 PDFDocument48 pagesTg11 Ict Model Book VZ 2016 PDFMohamed NawsathNo ratings yet
- Multimedia Technology PDFDocument5 pagesMultimedia Technology PDFShubham BhattNo ratings yet
- Eset Scan 23 Jan 2017Document1 pageEset Scan 23 Jan 2017Jiravas LerdcharunthornNo ratings yet
- Dip Questions On Bit Plane CodingDocument3 pagesDip Questions On Bit Plane CodingLavanyaNo ratings yet
- Hikvision Katalog RetailDocument13 pagesHikvision Katalog Retaildian wahyudiNo ratings yet