You might also like
- A Survey On Handwritten Character Recognition Using Deep Learning TechniqueDocument6 pagesA Survey On Handwritten Character Recognition Using Deep Learning TechniqueMs. Divya KonikkaraNo ratings yet
- Tài liệu về OCR 6Document6 pagesTài liệu về OCR 6Minh ChâuNo ratings yet
- Recognition of Devanagari Printed Text Using Neural Network and Genetic AlgorithmDocument4 pagesRecognition of Devanagari Printed Text Using Neural Network and Genetic AlgorithmvishwanathNo ratings yet
- A Survey On Handwritten Character Recognition (HCR) Techniques For English AlphabetsDocument12 pagesA Survey On Handwritten Character Recognition (HCR) Techniques For English AlphabetsavcjournalNo ratings yet
- Text Detection and Recognition A ReviewDocument10 pagesText Detection and Recognition A ReviewIJRASETPublicationsNo ratings yet
- Optical Character Recognition Using Artificial Neural NetworkDocument4 pagesOptical Character Recognition Using Artificial Neural NetworkFarhad Ahmed ChirleyNo ratings yet
- Extract and Organize Information in Images With AI Using IBM ServicesDocument7 pagesExtract and Organize Information in Images With AI Using IBM ServicesIJRASETPublicationsNo ratings yet
- Machine Learning For Handwriting Recognition: Preetha S, Afrid I M, Karthik Hebbar P, Nishchay S KDocument9 pagesMachine Learning For Handwriting Recognition: Preetha S, Afrid I M, Karthik Hebbar P, Nishchay S KAustin Abhishek KispottaNo ratings yet
- Guajarati Character Recognition: The State of The Art Comprehensive SurveyDocument4 pagesGuajarati Character Recognition: The State of The Art Comprehensive SurveyKrupa Patel DholakiaNo ratings yet
- Optical Character Recognition Technique AlgorithmsDocument8 pagesOptical Character Recognition Technique AlgorithmsAnushiMaheshwariNo ratings yet
- Personnel Identification Using Handwriting, Tested On Indian WritersDocument4 pagesPersonnel Identification Using Handwriting, Tested On Indian WritersEditor IJRITCCNo ratings yet
- Offline Handwritten Character Recognition Techniques Using Neural Network A ReviewDocument8 pagesOffline Handwritten Character Recognition Techniques Using Neural Network A ReviewIjsrnet Editorial100% (1)
- Pattern RecognitionDocument9 pagesPattern RecognitionAravinda GowdaNo ratings yet
- Character Segmentation and Recognition of Marathi LanguageDocument10 pagesCharacter Segmentation and Recognition of Marathi LanguageIJRASETPublicationsNo ratings yet
- Bayesian Decision Theory Based Handwritten Character RecognitionDocument8 pagesBayesian Decision Theory Based Handwritten Character RecognitionBarath GunasekaranNo ratings yet
- Diagonal Based Feature Extraction For Handwritten Alphabets Recognition System Using Neural NetworkDocument12 pagesDiagonal Based Feature Extraction For Handwritten Alphabets Recognition System Using Neural NetworkAnonymous Gl4IRRjzNNo ratings yet
- Texture Features From Handwritten Images For Writer IdentificationDocument4 pagesTexture Features From Handwritten Images For Writer IdentificationEditor IJRITCCNo ratings yet
- A Survey On Odia Handwritten Character RecognitionDocument2 pagesA Survey On Odia Handwritten Character RecognitionIJARTESNo ratings yet
- Detection of Bold Italic and Underline Fonts For Hindi OCRDocument4 pagesDetection of Bold Italic and Underline Fonts For Hindi OCRseventhsensegroupNo ratings yet
- HCR (English) Using Neural Network PDFDocument7 pagesHCR (English) Using Neural Network PDFDr. Hitesh MohapatraNo ratings yet
- A Comprehensive Study On Recognition of Various Indian and Non Indian ScriptsDocument10 pagesA Comprehensive Study On Recognition of Various Indian and Non Indian ScriptsDrNeeraj KansalNo ratings yet
- Devnagari Char Recognition PDFDocument4 pagesDevnagari Char Recognition PDFSaroj SahooNo ratings yet
- Handwritten Character RecognitionDocument22 pagesHandwritten Character RecognitionIJRASETPublicationsNo ratings yet
- Offline Handwritten Hindi Character Recognition Using Data Mining152Document50 pagesOffline Handwritten Hindi Character Recognition Using Data Mining152AshutoshSharmaNo ratings yet
- Image To Text Conversion, Character RecognitionDocument3 pagesImage To Text Conversion, Character RecognitionNAJIB GHATTENo ratings yet
- Ocr For Hindi Using NLPDocument25 pagesOcr For Hindi Using NLPAV MediaNo ratings yet
- Offline Signature Verification Using Critical Region MatchingDocument14 pagesOffline Signature Verification Using Critical Region MatchingIshaan GuptaNo ratings yet
- Enhancement and Segmentation of Historical RecordsDocument19 pagesEnhancement and Segmentation of Historical RecordsCS & ITNo ratings yet
- International Journal of Computational Engineering Research (IJCER)Document7 pagesInternational Journal of Computational Engineering Research (IJCER)International Journal of computational Engineering research (IJCER)No ratings yet
- A Survey On Handwritten Gujarati Character RecognitionDocument5 pagesA Survey On Handwritten Gujarati Character Recognitionmarmikshah57No ratings yet
- Numeral Recognition Using Statistical Methods Comparison StudyDocument9 pagesNumeral Recognition Using Statistical Methods Comparison Studysar0000No ratings yet
- Handwritten Gujarati Character Recognition Based On Discrete Cosine TransformDocument4 pagesHandwritten Gujarati Character Recognition Based On Discrete Cosine TransformAnkit SharmaNo ratings yet
- Text Color ImagesDocument6 pagesText Color ImagesvandanaNo ratings yet
- Handwritten English Alphabet RecognitionDocument8 pagesHandwritten English Alphabet RecognitionIJRASETPublicationsNo ratings yet
- SVMBasedRealTimeHand WrittenDigitRecognitionSystemDocument7 pagesSVMBasedRealTimeHand WrittenDigitRecognitionSystemOnur OzdemirNo ratings yet
- Alphanumeric Recognition Using Hand Gestures: Shashank Krishna Naik, Mihir Singh, Pratik Goswami, Mahadeva Swamy GNDocument7 pagesAlphanumeric Recognition Using Hand Gestures: Shashank Krishna Naik, Mihir Singh, Pratik Goswami, Mahadeva Swamy GNShashank Krishna NaikNo ratings yet
- Accuracy Augmentation of Tamil OCR Using Algorithm FusionDocument6 pagesAccuracy Augmentation of Tamil OCR Using Algorithm FusionsubakishaanNo ratings yet
- Construction of Statistical SVM Based Recognition Model For Handwritten Character RecognitionDocument16 pagesConstruction of Statistical SVM Based Recognition Model For Handwritten Character RecognitionPrasanna KumarNo ratings yet
- Devnagari Handwritten Numeral Recognition Using Geometric Features and Statistical Combination ClassifierDocument8 pagesDevnagari Handwritten Numeral Recognition Using Geometric Features and Statistical Combination ClassifierkprakashmmNo ratings yet
- Offline Handwritten Kannada Numerals Recognition: Sushritha S N Lohitesh KumarDocument4 pagesOffline Handwritten Kannada Numerals Recognition: Sushritha S N Lohitesh KumarEditor IJRITCCNo ratings yet
- Journal Paper PublicationDocument20 pagesJournal Paper Publicationrikaseo rikaNo ratings yet
- Text Detection in Document Images: Highlight On Using FAST AlgorithmDocument11 pagesText Detection in Document Images: Highlight On Using FAST AlgorithmNusret MeherremzadeNo ratings yet
- Centroidal Distance Based Offline Signature Recognition Using Global and Local FeaturesDocument7 pagesCentroidal Distance Based Offline Signature Recognition Using Global and Local FeaturesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- 3 With Cover Page v2Document21 pages3 With Cover Page v2Souhaila DjaffalNo ratings yet
- Project ResearchpaperDocument12 pagesProject ResearchpaperMuskan GuptaNo ratings yet
- CNN Based Digital Alphanumeric Archaeolinguistics Apprehension For Ancient Script DetectionDocument7 pagesCNN Based Digital Alphanumeric Archaeolinguistics Apprehension For Ancient Script Detectionaparna miduthuruNo ratings yet
- Optical Character Recognition Using 40-Point Feature Extraction and Artificial Neural NetworkDocument8 pagesOptical Character Recognition Using 40-Point Feature Extraction and Artificial Neural NetworkAravinda GowdaNo ratings yet
- Character RecognitionDocument5 pagesCharacter RecognitionLoganathan RmNo ratings yet
- Ijaia 040303Document16 pagesIjaia 040303Adam HansenNo ratings yet
- An Effective Approach in Face Recognition Using Image Processing ConceptsDocument5 pagesAn Effective Approach in Face Recognition Using Image Processing ConceptsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Writer-Independent Offline Signature Verification Using Deep LearningDocument7 pagesWriter-Independent Offline Signature Verification Using Deep LearningIJRASETPublicationsNo ratings yet
- Design of An OCR System and Its Hardware ImplementationDocument18 pagesDesign of An OCR System and Its Hardware ImplementationIJRASETPublicationsNo ratings yet
- Handwritten Text Recgnition FinalDocument5 pagesHandwritten Text Recgnition Final21211a05g9No ratings yet
- Tarang JI - EditedDocument20 pagesTarang JI - EditedprakharcoolsNo ratings yet
- Assignment 1 NFDocument6 pagesAssignment 1 NFKhondoker Abu NaimNo ratings yet
- 6 Ijcse 01245Document6 pages6 Ijcse 01245Austin Abhishek KispottaNo ratings yet
- Raster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionFrom EverandRaster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionNo ratings yet
- Optical Character Recognition: Unlocking the Power of Computer Vision for Optical Character RecognitionFrom EverandOptical Character Recognition: Unlocking the Power of Computer Vision for Optical Character RecognitionNo ratings yet
- Python Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1From EverandPython Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1No ratings yet
- Automatic License Plate RecognitionDocument6 pagesAutomatic License Plate RecognitionkavithekiranNo ratings yet
- Combo Smart: Compact, Single-Step, Full-Page Scanner Series With Versatile FunctionsDocument2 pagesCombo Smart: Compact, Single-Step, Full-Page Scanner Series With Versatile Functionsminhdung.pham4713No ratings yet
- ZKTECO Catalogo 2021Document53 pagesZKTECO Catalogo 2021Roberto PattyNo ratings yet
- License Plate Recognition System Based On Image Processing Using LabviewDocument6 pagesLicense Plate Recognition System Based On Image Processing Using LabviewJess ChanceNo ratings yet
- Omr Sheet SpecimenDocument1 pageOmr Sheet SpecimenSOUMITRA DEYNo ratings yet
- Foit Unit 1 NotesDocument38 pagesFoit Unit 1 NotesShekhar GuptaNo ratings yet
- Computer Applications Vol - 1 EM - WWW - Governmentexams.co - inDocument272 pagesComputer Applications Vol - 1 EM - WWW - Governmentexams.co - insanNo ratings yet
- UiPath Exam QuestionsDocument15 pagesUiPath Exam QuestionsCarlos0% (1)
- Alcina PDFDocument24 pagesAlcina PDFKaterina PauliucNo ratings yet
- 200 Questions OMR SheetDocument1 page200 Questions OMR SheetAjit AgarkarNo ratings yet
- Echnical Ulletin: Important Information About Normal/Smart Panel Firmware UpdatesDocument590 pagesEchnical Ulletin: Important Information About Normal/Smart Panel Firmware UpdatesHaii NguyenNo ratings yet
- Brother MFC-9840CDW Software User's GuideDocument217 pagesBrother MFC-9840CDW Software User's GuideregnillobNo ratings yet
- Guide For Creating Accessible DocumentsDocument14 pagesGuide For Creating Accessible DocumentsSiberNo ratings yet
- DAnish - Inpayment Form TypesDocument4 pagesDAnish - Inpayment Form TypesRajanikanth ChandrasekarNo ratings yet
- OCR PresentationDocument16 pagesOCR PresentationAniket JainNo ratings yet
- Sustainability of Accounting Profession at The AgeDocument20 pagesSustainability of Accounting Profession at The AgelogambaNo ratings yet
- Ibm Spss Data CollectionDocument13 pagesIbm Spss Data CollectionIzabela Nicoleta SavuNo ratings yet
- CurvedSegmentation Kannada1Document9 pagesCurvedSegmentation Kannada1Mayukh SinhaNo ratings yet
- Robotic Process AutomationDocument11 pagesRobotic Process AutomationPankaj SharmaNo ratings yet
- Practice Test OMR Sheet - Yakeen 2.0 2023Document1 pagePractice Test OMR Sheet - Yakeen 2.0 2023Manjula PatelNo ratings yet
- SCX 4521f, SCX 4321 FirmwareDocument59 pagesSCX 4521f, SCX 4321 Firmwarecaronnte0% (2)
- Microsoft - Pre .AI 102.by .VCEplus.54q DEMODocument71 pagesMicrosoft - Pre .AI 102.by .VCEplus.54q DEMORaymond CruzinNo ratings yet
- Manual Scaner Microtek 6100Document53 pagesManual Scaner Microtek 6100ervin8571No ratings yet
- Computer Full FormsDocument2 pagesComputer Full FormsYogesh TiwariNo ratings yet
- Optical Character Recognition by Open Source OCR Tool Tesseract: A Case StudyDocument8 pagesOptical Character Recognition by Open Source OCR Tool Tesseract: A Case StudySimran SinghNo ratings yet
- Canon SEND Ir ADV C2030/C2025/C2020 Series Service ManualDocument82 pagesCanon SEND Ir ADV C2030/C2025/C2020 Series Service ManualYury Kobzar75% (8)
- ICT PPT (Input Devices)Document11 pagesICT PPT (Input Devices)Jigar GajjarNo ratings yet
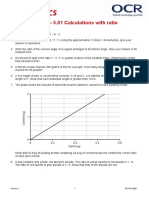
- Higher Check in - 5.01 Calculations With RatioDocument5 pagesHigher Check in - 5.01 Calculations With RatioKyleNo ratings yet
- Computer Graphics and Multimedia NotesDocument18 pagesComputer Graphics and Multimedia Notesrosewelt444No ratings yet
- OMRDocument15 pagesOMRmangerahNo ratings yet