You might also like
- Materials Planning and Control: by Priyanka Deepali Divya Parineeta Naqueeb SanaDocument22 pagesMaterials Planning and Control: by Priyanka Deepali Divya Parineeta Naqueeb SanaSunil AroraNo ratings yet
- Contents and Chapter Scheme of The Company Project StudyDocument5 pagesContents and Chapter Scheme of The Company Project StudySaurav PeriwalNo ratings yet
- Data Analysis PDFDocument65 pagesData Analysis PDFYaronBabaNo ratings yet
- How Does A Research Paper Differ From A Research ProposalDocument5 pagesHow Does A Research Paper Differ From A Research ProposalJonardTanNo ratings yet
- TEST1 Percentages 05062016Document5 pagesTEST1 Percentages 05062016Sahil KalaNo ratings yet
- Statistics 2Document4 pagesStatistics 2waleed100% (1)
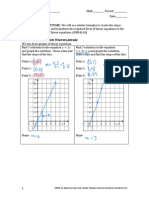
- Slope of A LineDocument4 pagesSlope of A LineSruthy S. KhanNo ratings yet
- Unit 5 Processing and Analysis of Data: CoritentsDocument11 pagesUnit 5 Processing and Analysis of Data: CoritentsJananee RajagopalanNo ratings yet
- Hard Math #3 ProblemsDocument28 pagesHard Math #3 Problemsapi-3839111100% (3)
- AP Statistics Exam Action PlanDocument3 pagesAP Statistics Exam Action PlanldlewisNo ratings yet
- Multiplying and Dividing MonomialsDocument3 pagesMultiplying and Dividing Monomialsapi-310503032No ratings yet
- DispersionDocument2 pagesDispersionrauf tabassumNo ratings yet
- AP Statistics 1st Semester Study GuideDocument6 pagesAP Statistics 1st Semester Study GuideSusan HuynhNo ratings yet
- Statistics - Describing Data NumericalDocument56 pagesStatistics - Describing Data NumericalDr Rushen SinghNo ratings yet
- Introduction To RatiosDocument21 pagesIntroduction To RatiosJay Ey BetchaidaNo ratings yet
- Review Graphing Linear Equations NotesDocument1 pageReview Graphing Linear Equations NotesBeth Ferguson0% (1)
- ARCH ModelDocument26 pagesARCH ModelAnish S.MenonNo ratings yet
- Mock AP Exam 3 Review - MC ProblemsDocument36 pagesMock AP Exam 3 Review - MC ProblemsMohammed IbrahimNo ratings yet
- A Five-Paragraph Essay Outline FlowchartDocument1 pageA Five-Paragraph Essay Outline FlowchartWan HabibNo ratings yet
- Factor AnalysisDocument8 pagesFactor AnalysisKeerthana keeruNo ratings yet
- AP Research PresentationDocument26 pagesAP Research PresentationCameron SherryNo ratings yet
- Solving ProportionsDocument8 pagesSolving ProportionsMr. PetersonNo ratings yet
- Ration Proportion and Percent Test PDFDocument3 pagesRation Proportion and Percent Test PDFChotiwat PreampresertsookNo ratings yet
- Manova and MancovaDocument10 pagesManova and Mancovakinhai_seeNo ratings yet
- 1 Statistics PDFDocument40 pages1 Statistics PDFHue HueNo ratings yet
- Unit8 Percentages ProportionalityDocument11 pagesUnit8 Percentages Proportionalitygiggia02No ratings yet
- Linear Regression Makes Several Key AssumptionsDocument5 pagesLinear Regression Makes Several Key AssumptionsVchair GuideNo ratings yet
- Module 02.1 Time Series Analysis and Forecasting AccuracyDocument11 pagesModule 02.1 Time Series Analysis and Forecasting AccuracyJunmirMalicVillanuevaNo ratings yet
- Time Series Forecasting Chapter 16Document43 pagesTime Series Forecasting Chapter 16Jeff Ray SanchezNo ratings yet
- Factoring Quadratic Equations PDFDocument2 pagesFactoring Quadratic Equations PDFCreola0% (1)
- Introduction To IBM SPSS StatisticsDocument85 pagesIntroduction To IBM SPSS StatisticswssirugNo ratings yet
- g8m4l16 - Slope Intercept Form of A Line and Converting From Standard Form To Slope InterceptDocument7 pagesg8m4l16 - Slope Intercept Form of A Line and Converting From Standard Form To Slope Interceptapi-276774049No ratings yet
- ch03 Ver3Document25 pagesch03 Ver3Mustansar Hussain NiaziNo ratings yet
- Final Exam Review 2015Document14 pagesFinal Exam Review 2015api-264817418No ratings yet
- CH 12VennDiagramsDocument13 pagesCH 12VennDiagramsashok_skpNo ratings yet
- ECONOMETRICS-Assignment 2Document2 pagesECONOMETRICS-Assignment 2Gaby Jacinda Andreas100% (1)
- Basic Concepts of StatisticsDocument313 pagesBasic Concepts of StatisticsKNOWLEDGE CREATORS100% (1)
- Supply Chain Management-Historical PerspectiveDocument7 pagesSupply Chain Management-Historical PerspectiveTalha SaeedNo ratings yet
- Data AnalysisDocument55 pagesData AnalysisSwati PowarNo ratings yet
- Elements of Statistics and Biometry Course ContentsDocument35 pagesElements of Statistics and Biometry Course ContentsMuhammad UsmanNo ratings yet
- Exploratory Data AnalysisDocument38 pagesExploratory Data Analysishss601No ratings yet
- Business MathematicsDocument61 pagesBusiness MathematicsVishal BhadraNo ratings yet
- Finding The Slope of A LineDocument4 pagesFinding The Slope of A Lineapi-490376928No ratings yet
- Class 8 Revision SheetDocument10 pagesClass 8 Revision SheetShamik GhoshNo ratings yet
- Name: - Score: - Grade/Section - DateDocument4 pagesName: - Score: - Grade/Section - DatemaryNo ratings yet
- Linear Algebra & MatricesDocument20 pagesLinear Algebra & Matriceskamayani_prNo ratings yet
- Linear Algebra and Matrices: Methods For Dummies 21 October, 2009 Elvina Chu & Flavia ManciniDocument33 pagesLinear Algebra and Matrices: Methods For Dummies 21 October, 2009 Elvina Chu & Flavia ManciniSyed Raheel AdeelNo ratings yet
- Chi SquareDocument35 pagesChi SquarePravab DhakalNo ratings yet
- Stages of Public PolicyDocument1 pageStages of Public PolicySuniel ChhetriNo ratings yet
- Ba9201 - Statistics For Managementjanuary 2010Document5 pagesBa9201 - Statistics For Managementjanuary 2010Sivakumar Natarajan100% (1)
- Trigonometric Equations and Identities Solved ExamplesDocument16 pagesTrigonometric Equations and Identities Solved Examplesmazhar10325No ratings yet
- Lecture 4: Let's Get Data!: Prof. Esther DufloDocument44 pagesLecture 4: Let's Get Data!: Prof. Esther DufloJake TolentinoNo ratings yet
- Introduction To Straight Lines (Students Study Material & Assignment)Document25 pagesIntroduction To Straight Lines (Students Study Material & Assignment)DAVID ABDULSHUAIB AYEDUNNo ratings yet
- Applications of Matrices To Business and EconomicsDocument6 pagesApplications of Matrices To Business and EconomicsAhmed Zubairu0% (1)
- STAT 251 Statistics Notes UBCDocument292 pagesSTAT 251 Statistics Notes UBChavarticanNo ratings yet
- Organizing Numerical Data Frequency DistributionsDocument55 pagesOrganizing Numerical Data Frequency Distributionsdendenlibero0% (1)
- Unit 20 - Central Tendency and Dispersion (Student)Document13 pagesUnit 20 - Central Tendency and Dispersion (Student)Suresh MgNo ratings yet
- Analysis of Quantitative Data LectureDocument178 pagesAnalysis of Quantitative Data LectureJones Ofei AgyemangNo ratings yet
- Engineering Statistics Lecture OverviewDocument10 pagesEngineering Statistics Lecture OverviewhkaqlqNo ratings yet
- Est Question For Iecep 2012Document4 pagesEst Question For Iecep 2012Ericson Blue Sta MariaNo ratings yet
- Iecep GEASDocument11 pagesIecep GEASFranz Henri de GuzmanNo ratings yet
- AlgebraDocument1 pageAlgebraJames LindoNo ratings yet
- Iecep Problem SolvingsDocument85 pagesIecep Problem SolvingsJohn Paul M. Tubig0% (2)
- Math IecepDocument10 pagesMath IecepDenaiya Watton Leeh100% (2)
- UPHSD - EST Control SystemDocument26 pagesUPHSD - EST Control SystemAlthea FortesNo ratings yet
- Math and Physics Practice QuestionsDocument3 pagesMath and Physics Practice QuestionsMark Anthony SantosNo ratings yet
- Geas Iecep PDFDocument26 pagesGeas Iecep PDFHenryboi CañasNo ratings yet
- Discrete Mathematics MATH 006 (TIP Reviewer)Document12 pagesDiscrete Mathematics MATH 006 (TIP Reviewer)James LindoNo ratings yet
- Engineering Orientation COE 001 (TIP Reviewer)Document8 pagesEngineering Orientation COE 001 (TIP Reviewer)James LindoNo ratings yet
- Society and Culture With Family Planning SOCSC 002 (TIP Reviewer)Document4 pagesSociety and Culture With Family Planning SOCSC 002 (TIP Reviewer)James Lindo86% (7)
- Economics, Agrarian Reform and Taxation SOCSC 001 (TIP Reviewer)Document39 pagesEconomics, Agrarian Reform and Taxation SOCSC 001 (TIP Reviewer)James LindoNo ratings yet
- Analytic Geometry MATH 004 (TIP Reviewer)Document9 pagesAnalytic Geometry MATH 004 (TIP Reviewer)James Lindo100% (1)
- Solid Mensuration MATH 005 (TIP Reviewer)Document14 pagesSolid Mensuration MATH 005 (TIP Reviewer)James Lindo80% (5)
- Life and Works of Rizal SOCSC 005 (TIP Reviewer)Document34 pagesLife and Works of Rizal SOCSC 005 (TIP Reviewer)James Lindo100% (4)
- Advanced Algebra MATH 003 (TIP Reviewer)Document1 pageAdvanced Algebra MATH 003 (TIP Reviewer)James LindoNo ratings yet
- Advanced Engineering Mathematics MATH 011 (TIP Reviewer)Document16 pagesAdvanced Engineering Mathematics MATH 011 (TIP Reviewer)James LindoNo ratings yet
- Advanced Electromagnetism ECE 121 (TIP Reviewer)Document30 pagesAdvanced Electromagnetism ECE 121 (TIP Reviewer)James LindoNo ratings yet
- Logic HUM 002 (TIP Reviewer)Document26 pagesLogic HUM 002 (TIP Reviewer)James LindoNo ratings yet
- Electronic Devices and Circuits ECE 001 (TIP Reviewer)Document33 pagesElectronic Devices and Circuits ECE 001 (TIP Reviewer)James Lindo100% (2)
- Fundamentals of MATLAB Programming MATH 014 (TIP Reviewer)Document3 pagesFundamentals of MATLAB Programming MATH 014 (TIP Reviewer)James LindoNo ratings yet
- Dynamics of Rigid Bodies CE 002 (TIP Reviewer)Document7 pagesDynamics of Rigid Bodies CE 002 (TIP Reviewer)James LindoNo ratings yet
- Computer Organization CPE 005B (TIP Reviewer)Document39 pagesComputer Organization CPE 005B (TIP Reviewer)James LindoNo ratings yet
- Vector Analysis ECE 301 (TIP Reviewer)Document17 pagesVector Analysis ECE 301 (TIP Reviewer)James Lindo100% (1)
- Electromagnetics ECE 121 (TIP Reviewer)Document22 pagesElectromagnetics ECE 121 (TIP Reviewer)James LindoNo ratings yet
- Calculus-Based Physics 2 PHYS 002 (TIP Reviewer)Document28 pagesCalculus-Based Physics 2 PHYS 002 (TIP Reviewer)James LindoNo ratings yet
- Logic Circuits and Switching Theory CPE 004 (TIP Reviewer)Document4 pagesLogic Circuits and Switching Theory CPE 004 (TIP Reviewer)James LindoNo ratings yet
- Safety Management IE 002 (TIP Reviewer)Document5 pagesSafety Management IE 002 (TIP Reviewer)James LindoNo ratings yet
- Signals, Spectra, Signal Processing ECE 401 (TIP Reviewer)Document40 pagesSignals, Spectra, Signal Processing ECE 401 (TIP Reviewer)James Lindo100% (2)
- Vlastakis ScienceDocument4 pagesVlastakis ScienceAnonymous 4O5p5xK2OBNo ratings yet
- Stat 11 Q4 Week 2-SSLMDocument4 pagesStat 11 Q4 Week 2-SSLMwiggleypuff100% (1)
- Machine Learning: An Introduction to Predicting the Future from Past ExperienceDocument65 pagesMachine Learning: An Introduction to Predicting the Future from Past ExperienceAnilNo ratings yet
- 081 CH 5Document5 pages081 CH 5Andrew James ReadNo ratings yet
- Cbot-Unit 1-LPPDocument23 pagesCbot-Unit 1-LPPJaya SuryaNo ratings yet
- Wks Mar09 Zscore ProblemsDocument1 pageWks Mar09 Zscore ProblemsKennyNo ratings yet
- Ucu Trigonometry Practice ProblemsDocument2 pagesUcu Trigonometry Practice ProblemsAngie Alcaide BautistaNo ratings yet
- Practical-2: DoneDocument16 pagesPractical-2: DoneSonam SinghNo ratings yet
- Module-1: Review Questions: Automata Theory and Computability - 15CS54Document4 pagesModule-1: Review Questions: Automata Theory and Computability - 15CS54ZuviNo ratings yet
- Functions, limits, derivatives and integralsDocument5 pagesFunctions, limits, derivatives and integralsTHE ACENo ratings yet
- Lodes Robot Simulator in MATLABDocument7 pagesLodes Robot Simulator in MATLABPhạm Ngọc HòaNo ratings yet
- Quantum simulation of negative hydrogen ion using VQEDocument16 pagesQuantum simulation of negative hydrogen ion using VQEiviNo ratings yet
- Table of Contents and Basic Hydraulic PrinciplesDocument6 pagesTable of Contents and Basic Hydraulic Principleskawser zamanNo ratings yet
- Balticway 11 SolDocument20 pagesBalticway 11 Solbenedito freireNo ratings yet
- OOP Lab#8: Pointers and InheritanceDocument5 pagesOOP Lab#8: Pointers and InheritanceKhalid AkramNo ratings yet
- Math 6 - Contextualized Lesson PlanDocument4 pagesMath 6 - Contextualized Lesson Planlk venturaNo ratings yet
- Portfolio Performance Measures: A Brief Survey and Hypothesis TestingDocument2 pagesPortfolio Performance Measures: A Brief Survey and Hypothesis Testingaurorashiva1No ratings yet
- Aerospace Engineering Sample Report PDFDocument4 pagesAerospace Engineering Sample Report PDFDuncan LeeNo ratings yet
- PEC Presentation LSA 2022Document35 pagesPEC Presentation LSA 2022Wahaaj AhmadNo ratings yet
- Laws of Exponents Simplification GuideDocument18 pagesLaws of Exponents Simplification GuideJoseff Rey PizonNo ratings yet
- Test Bank For Principles and Applications of Assessment in Counseling 5th Edition WhistonDocument24 pagesTest Bank For Principles and Applications of Assessment in Counseling 5th Edition WhistonSaraSmithcftj100% (35)
- CE214Document2 pagesCE214Mujammil ChoudhariNo ratings yet
- Deep Learning in Trading PDFDocument10 pagesDeep Learning in Trading PDFRicardo Velasco GuachallaNo ratings yet
- Marketing Head's Conundrum (Group 7)Document13 pagesMarketing Head's Conundrum (Group 7)Rini Rafi100% (2)
- Rounding To Decimal Places: 10 Multiple Choice QuestionsDocument29 pagesRounding To Decimal Places: 10 Multiple Choice QuestionsAlisha BhatiaNo ratings yet
- 01AUL SG 17d SymbolicCircuitAnalysisDocument33 pages01AUL SG 17d SymbolicCircuitAnalysisLuca CorNo ratings yet
- Latitude and Longitude BasicDocument14 pagesLatitude and Longitude Basicapi-235000986100% (3)
- Tutorial Fourier Series and TransformDocument5 pagesTutorial Fourier Series and TransformRatish DhimanNo ratings yet
- Subject ApptitudeDocument54 pagesSubject ApptitudeVaidh Prakash ChoudharyNo ratings yet
- Directional Drilling - Target Approach CalculationsDocument34 pagesDirectional Drilling - Target Approach CalculationswalidNo ratings yet