You might also like
- Theory GraphDocument23 pagesTheory GraphArthur CarabioNo ratings yet
- Hey Friends B TBDocument152 pagesHey Friends B TBTizianoCiro CarrizoNo ratings yet
- Working Capital in YamahaDocument64 pagesWorking Capital in YamahaRenu Jindal50% (2)
- PMP Question BankDocument3 pagesPMP Question BankOmerZiaNo ratings yet
- (IJCST-V4I4P2) :walelign Tewabe Sewunetie, Eshete Derb EmiruDocument8 pages(IJCST-V4I4P2) :walelign Tewabe Sewunetie, Eshete Derb EmiruEighthSenseGroupNo ratings yet
- 2006 Liviu P. Dinu, Anca Dinu, 2006. On The Data Base of Romanian SyllablesDocument4 pages2006 Liviu P. Dinu, Anca Dinu, 2006. On The Data Base of Romanian SyllablesaNo ratings yet
- Versatile Speech Databases For High Quality Synthesis For BasqueDocument5 pagesVersatile Speech Databases For High Quality Synthesis For BasqueacouillaultNo ratings yet
- Acoustical Characterization of Vocalic Fillers in European Portuguese - ProencaDocument4 pagesAcoustical Characterization of Vocalic Fillers in European Portuguese - ProencaJorge SeguraNo ratings yet
- 2-Phonology Notes of TedimDocument6 pages2-Phonology Notes of TedimChesedel Jobien M. LimlinganNo ratings yet
- A First LVCSR System For Luxembourgish ADocument13 pagesA First LVCSR System For Luxembourgish AAlexandre Rocha Lima e MarcondesNo ratings yet
- Impact of Duration and Vowel Inventory Size On Formant Values of Oral Vowels: An Automated Formant Analysis From Eight LanguagesDocument4 pagesImpact of Duration and Vowel Inventory Size On Formant Values of Oral Vowels: An Automated Formant Analysis From Eight LanguagesIgor ReinaNo ratings yet
- Different Modeling For Amharic PDFDocument14 pagesDifferent Modeling For Amharic PDFInderjeetSinghNo ratings yet
- 208 PaperDocument7 pages208 PaperacouillaultNo ratings yet
- Dynamic Language Modeling For European Portuguese: Ciro Martins, Anto Nio Teixeira, Joa o NetoDocument24 pagesDynamic Language Modeling For European Portuguese: Ciro Martins, Anto Nio Teixeira, Joa o NetoBader Al-NadhiriNo ratings yet
- DNN-Based Multilingual Automatic Speech Recognition For Wolaytta Using Oromo SpeechDocument6 pagesDNN-Based Multilingual Automatic Speech Recognition For Wolaytta Using Oromo SpeechadamuNo ratings yet
- Development of An Amharic Text-to-Speech System PDFDocument7 pagesDevelopment of An Amharic Text-to-Speech System PDFEndalew SimieNo ratings yet
- A Fuzzy Decision Tree-Based Duration Model For Standard Yoru'ba Text-To-Speech SynthesisDocument25 pagesA Fuzzy Decision Tree-Based Duration Model For Standard Yoru'ba Text-To-Speech SynthesisMarcos VerdugoNo ratings yet
- ALICE: An Open-Source Tool For Automatic Measurement of Phoneme, Syllable, and Word Counts From Child-Centered Daylong RecordingsDocument49 pagesALICE: An Open-Source Tool For Automatic Measurement of Phoneme, Syllable, and Word Counts From Child-Centered Daylong RecordingsGermán CapdehouratNo ratings yet
- Portable Spelling CorrectorDocument6 pagesPortable Spelling Correctorhayu B.No ratings yet
- Laura Sasu - Compararive-Contrastive Analysis of Romanian To English Translation. Language StructuresDocument7 pagesLaura Sasu - Compararive-Contrastive Analysis of Romanian To English Translation. Language StructuresIoana MNo ratings yet
- PL Features ParametersDocument13 pagesPL Features ParametersMateus Alves MottaNo ratings yet
- ArMeXLeR Arabic Meaning Extraction Through Lexical Resources: A General-Purpose Data Mining Model For Arabic TextsDocument6 pagesArMeXLeR Arabic Meaning Extraction Through Lexical Resources: A General-Purpose Data Mining Model For Arabic TextsIlariaNo ratings yet
- Current F-LARSP For ClinLingDocument17 pagesCurrent F-LARSP For ClinLingLalitha RajaNo ratings yet
- Language Identification Through GMMs and Language ModellingDocument30 pagesLanguage Identification Through GMMs and Language ModellingHarsh HemaniNo ratings yet
- 2020 The Use of English, Czech and French Punctuation Marks in Reference, Parallel and Comparable Corpora - Question of MethodologyDocument21 pages2020 The Use of English, Czech and French Punctuation Marks in Reference, Parallel and Comparable Corpora - Question of MethodologynadvolgNo ratings yet
- Abhijit Pradhan, Aswin Shanmugam S, Anusha Prakash, Kamakoti Veezhinathan, Hema MurthyDocument5 pagesAbhijit Pradhan, Aswin Shanmugam S, Anusha Prakash, Kamakoti Veezhinathan, Hema MurthyBoby JosephNo ratings yet
- The Academic Dictionary of The Romanian Language (Dicţionarul Academic Al Limbii Române - DLR) Lexicological Relevance and Romanic ContextDocument8 pagesThe Academic Dictionary of The Romanian Language (Dicţionarul Academic Al Limbii Române - DLR) Lexicological Relevance and Romanic ContextsuidivoNo ratings yet
- Documentos de Trabajo: Universidad Del Cema Buenos Aires ArgentinaDocument29 pagesDocumentos de Trabajo: Universidad Del Cema Buenos Aires ArgentinaDavid SeisaNo ratings yet
- Unsupervised Learning of The Morphology PDFDocument46 pagesUnsupervised Learning of The Morphology PDFappled.apNo ratings yet
- Comparison:Four Approaches To Automatic Language Identification of Telephone SpeechDocument14 pagesComparison:Four Approaches To Automatic Language Identification of Telephone SpeechHuong LeNo ratings yet
- Articles: Speech Synthesis 1 Prosody (Linguistics) 11 Tone (Linguistics) 13Document26 pagesArticles: Speech Synthesis 1 Prosody (Linguistics) 11 Tone (Linguistics) 13Mouni SharonNo ratings yet
- Light Stemming For Arabic Information RetrievalDocument34 pagesLight Stemming For Arabic Information RetrievalVega DeltaNo ratings yet
- Yeh 2012 Speech-CommunicationDocument12 pagesYeh 2012 Speech-CommunicationAmanda MartinezNo ratings yet
- JamaMusse J Somali Corpus StateOfTheArt PDFDocument8 pagesJamaMusse J Somali Corpus StateOfTheArt PDFAhmedNo ratings yet
- TranscriptionDocument6 pagesTranscriptionDanail MarinovNo ratings yet
- Solomon Teferra Abate, Martha Yifiru Tachbelie, Wolfgang Menzel - AmharicDocument12 pagesSolomon Teferra Abate, Martha Yifiru Tachbelie, Wolfgang Menzel - AmharicmohammedNo ratings yet
- A Novel Approach in Continuous Speech Recognition For Vietnamese, An Isolating Tonal LanguageDocument4 pagesA Novel Approach in Continuous Speech Recognition For Vietnamese, An Isolating Tonal LanguageMicro TuấnNo ratings yet
- 2007 Liviu P. Dinu, Denis Enachescu, 2007. On Clustering Romance LanguagesDocument8 pages2007 Liviu P. Dinu, Denis Enachescu, 2007. On Clustering Romance LanguagesaNo ratings yet
- Jong and Wempe 2009 - Praat Script To Detect Syllable NucleiDocument6 pagesJong and Wempe 2009 - Praat Script To Detect Syllable Nucleictrplieff2669No ratings yet
- File 4Document10 pagesFile 4Iliass AboulhoucineNo ratings yet
- Incorporating Contextual Phonetics Into Automatic Speech RecognitionDocument4 pagesIncorporating Contextual Phonetics Into Automatic Speech RecognitionYuder CuadrosNo ratings yet
- Transcription (Linguistics)Document5 pagesTranscription (Linguistics)parand2003No ratings yet
- Snowball: A Language For Stemming AlgorithmsDocument14 pagesSnowball: A Language For Stemming AlgorithmssimonchikNo ratings yet
- Describing SoundsDocument13 pagesDescribing SoundsMaya GenevaNo ratings yet
- Seifart, Orthography Development PDFDocument26 pagesSeifart, Orthography Development PDFGeorgia PantioraNo ratings yet
- Syntactic Dislocation Phenomena in The Adverbial Clauses of Romance Languages - A Comparative PerspectiveDocument20 pagesSyntactic Dislocation Phenomena in The Adverbial Clauses of Romance Languages - A Comparative PerspectiveGlobal Research and Development ServicesNo ratings yet
- English-Afaan Oromo Statistical Machine TranslationDocument6 pagesEnglish-Afaan Oromo Statistical Machine TranslationAI Coordinator - CSC Journals100% (1)
- Orthography Development: Frank SeifartDocument26 pagesOrthography Development: Frank SeifartAnwar WafiNo ratings yet
- A Corpus of Spoken Faroese: Janne Bondi Johannessen University of OsloDocument11 pagesA Corpus of Spoken Faroese: Janne Bondi Johannessen University of OsloArcadio CanepariNo ratings yet
- Harris, Z. Simultaneous Components in PhonologyDocument26 pagesHarris, Z. Simultaneous Components in PhonologyRodolfo van GoodmanNo ratings yet
- Transcription of Phonemes and PhonesDocument2 pagesTranscription of Phonemes and PhonesAgustina D'AndreaNo ratings yet
- The Role of Phonetics and Phonetic Databases in Japanese Speech TechnologyDocument6 pagesThe Role of Phonetics and Phonetic Databases in Japanese Speech TechnologyHelena BaudelaireNo ratings yet
- A Finite-State Morphological Analyzer For WolayttaDocument10 pagesA Finite-State Morphological Analyzer For WolayttaIysusi GetanwNo ratings yet
- End-to-End Evaluation in Simultaneous TranslationDocument9 pagesEnd-to-End Evaluation in Simultaneous TranslationMarco TrujilloNo ratings yet
- Textual Characteristics For Language Engineering: Mathias Bank, Robert Remus, Martin SchierleDocument5 pagesTextual Characteristics For Language Engineering: Mathias Bank, Robert Remus, Martin SchierleacouillaultNo ratings yet
- Text Independent Amharic Language Speaker IdentifiDocument6 pagesText Independent Amharic Language Speaker Identifilamrotgetaw15No ratings yet
- Acoustic Representation of BODO and RABHA Phonemes: Issn NoDocument9 pagesAcoustic Representation of BODO and RABHA Phonemes: Issn NoWARSE JournalsNo ratings yet
- The At&t German Text-To-Speech System: Realistic Linguistic DescriptionDocument4 pagesThe At&t German Text-To-Speech System: Realistic Linguistic DescriptionViktor ZipenjukNo ratings yet
- Mining Filipino-English Corpora From The Web: Joel P. Ilao and Rowena Cristina L. GuevaraDocument5 pagesMining Filipino-English Corpora From The Web: Joel P. Ilao and Rowena Cristina L. GuevaraElizabeth CastroNo ratings yet
- NG Et Al VNSFP Is13 HalDocument5 pagesNG Et Al VNSFP Is13 HalJoshua OrtizNo ratings yet
- Syntax, Goals of Generative Grammar, 2021-22Document6 pagesSyntax, Goals of Generative Grammar, 2021-22Sara BelemkaddemNo ratings yet
- A Speaker Independent Continuous Speech Recognizer For AmharicDocument5 pagesA Speaker Independent Continuous Speech Recognizer For AmharicBelete BelayNo ratings yet
- Makalah SociolinguisticsDocument8 pagesMakalah SociolinguisticsVandy suanNo ratings yet
- Informal Speech: Alphabetic and Phonemic Text with Statistical Analyses and TablesFrom EverandInformal Speech: Alphabetic and Phonemic Text with Statistical Analyses and TablesNo ratings yet
- Chitoran Et AlDocument5 pagesChitoran Et AlCristina TomaNo ratings yet
- Idioms Between Motivation and Translation: Prep. Univ. Oana Dugan, Universitatea "Dunărea de Jos", GalaţiDocument11 pagesIdioms Between Motivation and Translation: Prep. Univ. Oana Dugan, Universitatea "Dunărea de Jos", GalaţiCristina TomaNo ratings yet
- A Comparison of The Knight and The Samurai (By Ricky Buria) PDFDocument19 pagesA Comparison of The Knight and The Samurai (By Ricky Buria) PDFCristina TomaNo ratings yet
- 05 Multiword ExpressionsDocument26 pages05 Multiword ExpressionsCristina TomaNo ratings yet
- Towards Cross-Language ApplicationDocument10 pagesTowards Cross-Language ApplicationCristina TomaNo ratings yet
- A Comparison of The Knight and The Samurai (By Ricky Buria) PDFDocument19 pagesA Comparison of The Knight and The Samurai (By Ricky Buria) PDFCristina TomaNo ratings yet
- Infographic OpencallDocument1 pageInfographic OpencallCristina TomaNo ratings yet
- Research Group in Speech Technology and Communication TechniquesDocument3 pagesResearch Group in Speech Technology and Communication TechniquesCristina TomaNo ratings yet
- Romanian Demonstratives and Minimality: 1. Aim of The SectionDocument14 pagesRomanian Demonstratives and Minimality: 1. Aim of The SectionCristina TomaNo ratings yet
- Arabic NPI and NCDocument70 pagesArabic NPI and NCCristina TomaNo ratings yet
- T Standards and QADocument66 pagesT Standards and QACristina TomaNo ratings yet
- 30 20-23-10HANDOUT The Syntax of Romanian DemonstrativesDocument26 pages30 20-23-10HANDOUT The Syntax of Romanian DemonstrativesCristina TomaNo ratings yet
- University of Bucharest: On The Syntax of Romanian Definite Phrases: C P D CDocument23 pagesUniversity of Bucharest: On The Syntax of Romanian Definite Phrases: C P D CCristina TomaNo ratings yet
- Quick Start Guide SDL Trados Studio 2015 - Translating and Reviewing DocumentsDocument54 pagesQuick Start Guide SDL Trados Studio 2015 - Translating and Reviewing DocumentsCristina Toma100% (1)
- Gerund in English LanguageDocument31 pagesGerund in English LanguageCristina TomaNo ratings yet
- Opportunities in Natural Language ProcessingDocument60 pagesOpportunities in Natural Language ProcessingCristina TomaNo ratings yet
- Cognitive Approaches To TranslationDocument10 pagesCognitive Approaches To TranslationCristina TomaNo ratings yet
- Cognitive Linguistics and TranslationDocument3 pagesCognitive Linguistics and TranslationCristina Toma100% (1)
- ChicagoDocument25 pagesChicagoCristina TomaNo ratings yet
- Writing GuideDocument11 pagesWriting GuideCristina TomaNo ratings yet
- Punctuating CompoundsDocument1 pagePunctuating CompoundsCristina TomaNo ratings yet
- Chicago Style Paper ExampleDocument6 pagesChicago Style Paper ExampleCristina TomaNo ratings yet
- Essay Rough Draft 19Document9 pagesEssay Rough Draft 19api-549246767No ratings yet
- Classifications of AssessmentsDocument11 pagesClassifications of AssessmentsClaire CatapangNo ratings yet
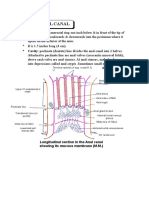
- Anatomy Anal CanalDocument14 pagesAnatomy Anal CanalBela Ronaldoe100% (1)
- The Person Environment Occupation (PEO) Model of Occupational TherapyDocument15 pagesThe Person Environment Occupation (PEO) Model of Occupational TherapyAlice GiffordNo ratings yet
- Excon2019 ShowPreview02122019 PDFDocument492 pagesExcon2019 ShowPreview02122019 PDFSanjay KherNo ratings yet
- Assignment#10 Global Strategy and The Multinational CorporationDocument1 pageAssignment#10 Global Strategy and The Multinational CorporationAnjaneth A. VillegasNo ratings yet
- Ricoh IM C2000 IM C2500: Full Colour Multi Function PrinterDocument4 pagesRicoh IM C2000 IM C2500: Full Colour Multi Function PrinterKothapalli ChiranjeeviNo ratings yet
- E0 UoE Unit 7Document16 pagesE0 UoE Unit 7Patrick GutierrezNo ratings yet
- Tetralogy of FallotDocument8 pagesTetralogy of FallotHillary Faye FernandezNo ratings yet
- Residual Power Series Method For Obstacle Boundary Value ProblemsDocument5 pagesResidual Power Series Method For Obstacle Boundary Value ProblemsSayiqa JabeenNo ratings yet
- Agco Serie 800 PDFDocument24 pagesAgco Serie 800 PDFJohnny VargasNo ratings yet
- NDY 9332v3Document8 pagesNDY 9332v3sulphurdioxideNo ratings yet
- Fusion Implementing Offerings Using Functional Setup Manager PDFDocument51 pagesFusion Implementing Offerings Using Functional Setup Manager PDFSrinivasa Rao Asuru0% (1)
- SSGC-RSGLEG Draft Study On The Applicability of IAL To Cyber Threats Against Civil AviationDocument41 pagesSSGC-RSGLEG Draft Study On The Applicability of IAL To Cyber Threats Against Civil AviationPrachita AgrawalNo ratings yet
- Shostack ModSec08 Experiences Threat Modeling at MicrosoftDocument11 pagesShostack ModSec08 Experiences Threat Modeling at MicrosoftwolfenicNo ratings yet
- Quick Help For EDI SEZ IntegrationDocument2 pagesQuick Help For EDI SEZ IntegrationsrinivasNo ratings yet
- Functions in C++Document23 pagesFunctions in C++Abhishek ModiNo ratings yet
- PR KehumasanDocument14 pagesPR KehumasanImamNo ratings yet
- Companyprofil E: Erfanconstructionsolut IonDocument14 pagesCompanyprofil E: Erfanconstructionsolut IonNurin AleesyaNo ratings yet
- 5c3f1a8b262ec7a Ek PDFDocument5 pages5c3f1a8b262ec7a Ek PDFIsmet HizyoluNo ratings yet
- Manual s10 PDFDocument402 pagesManual s10 PDFLibros18No ratings yet
- Biological Beneficiation of Kaolin: A Review On Iron RemovalDocument8 pagesBiological Beneficiation of Kaolin: A Review On Iron RemovalValentin GnoumouNo ratings yet
- Report Card Grade 1 2Document3 pagesReport Card Grade 1 2Mely DelacruzNo ratings yet
- Oracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qDocument49 pagesOracle - Prep4sure.1z0 068.v2016!07!12.by - Lana.60qLuis AlfredoNo ratings yet
- Making Effective Powerpoint Presentations: October 2014Document18 pagesMaking Effective Powerpoint Presentations: October 2014Mariam TchkoidzeNo ratings yet
- Ron Kangas - IoanDocument11 pagesRon Kangas - IoanBogdan SoptereanNo ratings yet